
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIの限界を決めるのは知能ではなく「データ」だ
AIの性能が上がれば、何でも自動化できる。そう信じていた時期があった。
現実は全く違う。賢いAIも、ぐちゃぐちゃのPDFや表記揺れだらけのCSVを食わされれば簡単に幻覚を起こす。
2万1000社の食品卸を支える巨大システムも、個人開発の売上予測アプリも、直面した壁は同じだ。
モデルの推論能力よりも、入力データをいかに綺麗に整えるかが勝敗を分ける。
「とりあえずLLMに投げればなんとかなる」という幻想は終わっている。
非構造化データを構造化する。泥臭い正規化のパイプラインこそが、AIシステムの命運を握る。
カオスな入力を構造化する戦い
海外の食品サプライチェーンで、AIによる受発注の自動化が進んでいる。
2万1000社の卸業者と10万以上の買い手を繋ぐプラットフォームでの事例だ。
受発注の現場は、長年アナログな手法に支配されてきた。
メール、テキストメッセージ、画像、手書きのメモが飛び交うカオスな状態だ。
手作業による基幹システムへの入力は遅く、エラーの温床になっていた。
そこで彼らは、強力なAIモデルをシステムの中核に組み込んだ。
音声からテキストへの変換、関数呼び出し、ベクトル化といった機能をインフラに統合した。
マルチモーダルな入力を処理し、基幹システムが読み込める構造化データに変換するエージェントを開発した。

リアルタイムAPIを活用した音声エージェントも構築した。
顧客は電話で自然に発注でき、システムはミリ秒単位の遅延で応答する。
営業時間外でも注文を受け付ける。
顧客側は行動を変える必要がない。
裏側でAIがカオスな入力を解釈し、システムが処理できる形式に整形する。
年間で処理されるAIトークン数は膨大な規模だ。
精度を担保するために、厳格な評価フレームワークも構築されている。
正解データセットを用意し、継続的なモニタリングとA/Bテストを実施する。
本番環境での信頼性を確保するための取り組みだ。
一方で、個人開発の売上予測アプリでも同じアプローチが取られている。
ユーザーがアップロードするCSVやエクセルデータは、列名もフォーマットもバラバラだ。
これをユーザーに修正させるのではなく、システム側で自動的に正規化する。
エクセルからコピーされたタブ区切りのデータは、フロントエンドでカンマ区切りに変換される。
バックエンドでは、無数にある列の中から日付を示す列を自動で検出する。
「日付」「Date」「年月日」といった表記揺れをシステムが吸収する。
データの匿名化にも工夫がある。
- 日付をランダムに±180日シフトさせる
- 売上データを0から1の範囲に正規化する
- ランダムなUUIDを付与して保存する
セキュリティ対策も実装されている。
- ファイルサイズを5MB以下に制限する
- 同一IPからのアクセスを1分間に10回までに制限する
- 中身のフォーマットも厳格に検証する
文書処理に特化したオープンソースのライブラリも注目を集めている。
PDFやワードなどの複雑なレイアウトを持つ文書を、構造を保ったままマークダウンやJSONに変換するツールだ。
ただテキストを抽出するのではなく、見出し、表、リストといった意味的なまとまりを維持する。
入力される文書形式に応じて、処理パイプラインを自動で切り替える。
PDFや画像に対しては、レイアウト解析やOCR、表構造認識を駆使して文書構造を再構成する。
オフィス文書やHTMLのように元々構造を持つ形式は、その情報を活かしながら変換を行う。
最終的には共通のドキュメント形式に統一される。
これにより、後続のシステム連携やデータ分割がシンプルになる。
ローカルのファイルだけでなく、URL上のPDFもそのまま処理できる。
コマンドラインから簡単に実行でき、Pythonスクリプトへの組み込みも容易だ。
しんたろー:
AIにPDFを読ませて「全然違うじゃん」と画面を閉じた経験がある。
表のデータがただのテキストの羅列になると、LLMも文脈を見失う。
前処理を飛ばしてプロンプトだけで解決しようとしていた時期を思い出す。
開発者が直面する「正規化」という泥臭い現実
AI開発といえば、プロンプトエンジニアリングやRAGの構築が語られる。
実態は、非構造化データを構造化する「正規化エンジニアリング」に大半の時間が割かれる。
どれだけ強力なモデルを使っても、入力データが不適切なら出力も不適切になる。
「Garbage In, Garbage Out」の原則は、AI時代に顕著だ。
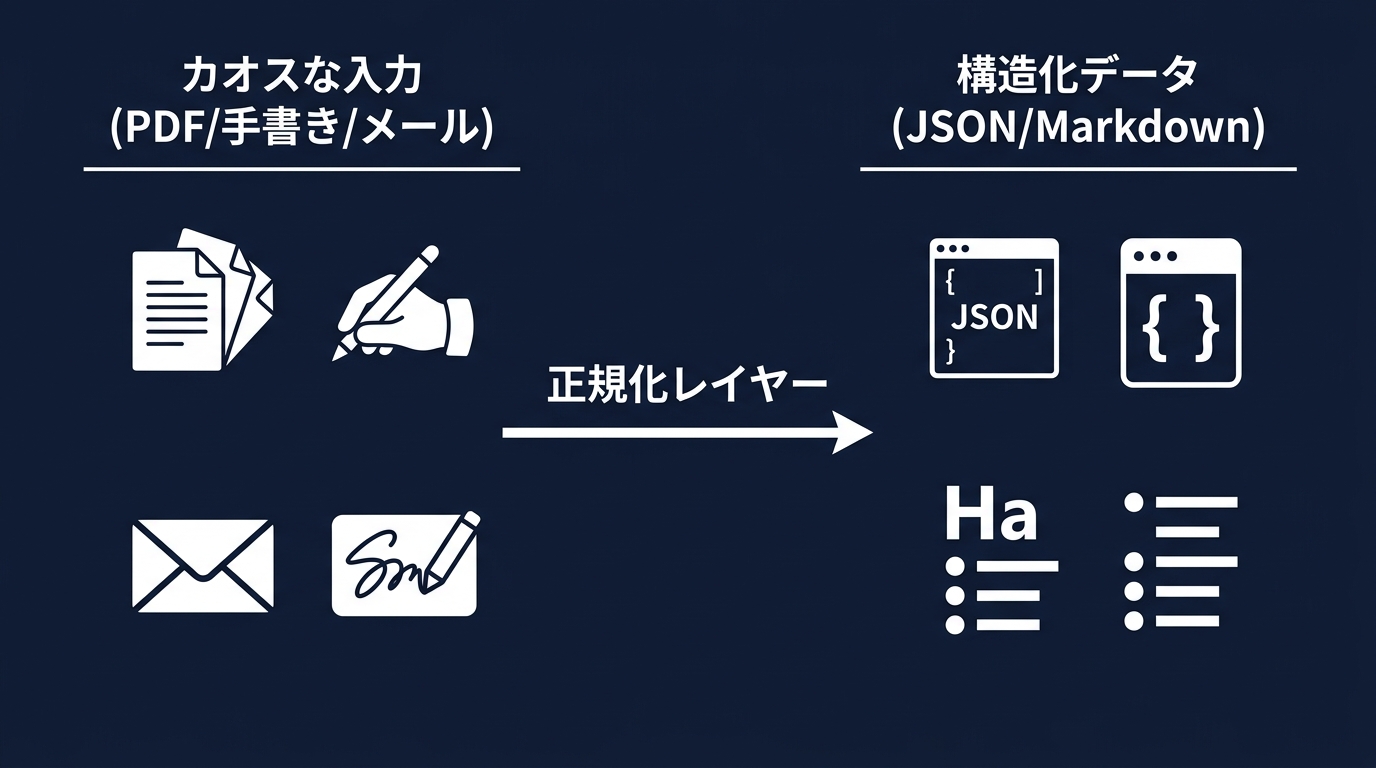
大規模なサプライチェーンの事例でも、個人開発のアプリでも、課題は同じだ。
「入力データの揺らぎをどう吸収するか」という一点に尽きる。
ユーザーに綺麗なデータを用意させるのは、UXの敗北だ。
システム側で泥臭く正規化のパイプラインを組む。
たとえばPDFの表組みデータだ。
レイアウトが崩れたテキストをそのままLLMに投げると、行と列の対応関係が崩壊する。
「商品A」の価格が「商品B」のものとして認識される。
この状態でプロンプトを工夫しても、正確な回答は返ってこない。
文書構造を維持したままマークダウンに変換するツールの出番となる。
文書変換ツールを前段に挟むメリットは大きい。
- レイアウト解析による視覚的構造の保持
- OCRを活用した画像内テキストの抽出
- 表構造の正確なマークダウン化
これを前段に噛ませるだけで、LLMの理解度は向上する。
マークダウンのテーブル記法は、LLMにとって消化しやすいフォーマットだ。
Claude Codeを使って開発していると、この前処理の重要性がわかる。
外部ドキュメントを読み込ませてコードを書かせる時、ドキュメントの構造が綺麗だと生成されるコードの精度が上がる。
ノイズだらけのテキストを渡すと、Claudeも幻覚を見る。
エージェントの性能を最大限に引き出すには、渡すコンテキストの純度を上げる必要がある。
個人開発の売上予測アプリの事例は、正規化のベストプラクティスだ。
ユーザーがエクセルからコピペしたデータは、タブ区切りでフロントエンドに渡される。
これをバックエンドに送る前に、カンマ区切りのCSVに自動で整形する。
セル内改行や不要な空白スペースも、この段階で排除する。
日付列の自動検出まで実装されている。
ユーザーごとに異なる列名を、システムが判断する。
これこそが、AI時代に求められる「ユーザーに考えさせない」設計だ。
データのフォーマットをシステムに合わせさせる時代は終わった。
強力なAIモデルを「知能」としてではなく「構造化器」として使うアプローチも増えている。
手書きのメモや音声データを、JSON形式の構造化データに変換するためだけにLLMを使う。
推論や文章生成ではなく、単なるフォーマット変換装置としての起用だ。
特定のスキーマに従った出力を強制する機能を使えば、後続のシステム連携が確実になる。
非構造化データを構造化データに変換するプロセスは、地味だ。
しかし、これこそがAIシステムを本番環境で稼働させるための障壁となっている。
データの前処理を制する者が、AI開発を制する。
RAGを構築する際も同じ問題が発生する。
単純にテキストを一定の文字数で分割すると、重要な文脈が途切れる。
見出しや段落といった文書の構造を意識して分割しなければ、検索精度は上がらない。
意味的なまとまりを無視したチャンキングは、検索ノイズを増やす。
文書変換ツールを使ってマークダウン形式に統一しておけば、この分割作業が楽になる。
見出し単位でデータを切り出すことが容易になるからだ。
結果として、ベクトルデータベースに格納されるデータの質が向上する。
検索される情報の純度が高まれば、最終的な生成結果も正確になる。
最近はLLMを「超高機能な正規表現」として使っている。
複雑なテキストから特定の情報だけ抜いてJSONにする作業は、正規表現では限界がある。
API代はかかるが、正規表現のメンテに時間を溶かすよりはるかに効率的だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
幻覚を防ぐためのデータパイプライン構築
AIシステムを作るなら「プロンプトの工夫」より「データパイプラインの構築」に時間をかける。
LLMに直接生データを投げるのは避ける。
それは爆弾を抱えたまま走るようなものだ。

まずは入力データの正規化レイヤーを設ける。
ユーザーからの入力がテキストであれ画像であれ、一度システムが扱いやすい形式に変換する。
ここで文書変換ツールや、自動整形ロジックを挟む。
この中間層の存在が、システム全体の堅牢性を決定づける。
とくに表データやレイアウトが複雑なPDFを扱う場合は、マークダウン化が有効だ。
LLMはマークダウンの構造を理解するのが得意だ。
見出しや表の構造をマークダウンで明示するだけで、文脈の誤認は減る。
HTMLやXMLよりも、マークダウンの方がトークン数も節約できる。
データパイプライン構築の鉄則は以下の通りだ。
- ユーザー入力の揺らぎをフロントエンドで吸収する
- 複雑な文書は必ずマークダウン形式に変換する
- 構造化に特化した軽量モデルを併用する
ユーザー入力の揺らぎを吸収するフロントエンドの工夫も重要だ。
コピペされたデータの区切り文字を自動で判別し、統一フォーマットに変換する。
エラーを返すのではなく、システム側で修正する設計にする。
「フォーマットが違います」というエラーメッセージは、ユーザーの離脱を招く。
Claude Codeでエージェントにタスクを投げる際も同じだ。
コンテキストとして渡すファイルは、事前にノイズを除去し、構造化しておく。
これだけで、エージェントの迷いが消え、一発で目的のコードを出力するようになる。
AIに無駄な推測をさせないことが、精度の高い出力を得るための鉄則だ。
AIは確率的なテキスト生成器だ。
その確率をコントロールし、望む結果を引き出すための土台が、データの前処理だ。
前処理の質が、そのままAIの出力に直結する。
モデルの選定においても、この視点は重要だ。
複雑な推論を行うメインのモデルと、データ構造化に特化した軽量モデルを使い分ける。
すべての処理を巨大なモデルに任せると、コストとレイテンシが跳ね上がる。
適材適所でモデルを配置するアーキテクチャ設計が求められる。
構造化のためのプロンプトも、シンプルにする。
「以下のテキストから日付と金額を抽出し、JSON形式で出力せよ」といった具合だ。
余計な指示を与えず、タスクを分割する。
一つのプロンプトに複数のタスクを詰め込むと、構造化の精度は落ちる。
テストデータの準備も忘れてはいけない。
本番環境で想定される、あらゆる「汚いデータ」を集めておく。
そのデータが正しく構造化されるかを、自動テストで継続的に検証する。
エッジケースをどれだけ網羅できるかが、システムの安定性を左右する。
システムの信頼性は、この地道な検証作業によってのみ担保される。
AIの出力は常に不安定だ。
だからこそ、入力データだけは完全にコントロール下に置く必要がある。
揺らぐ出力に対して、揺るがない入力を提供し続ける。
結局、泥臭いデータ処理から逃げられないのが現実だ。
「AIが全部やってくれる」という言葉は、自分でシステムを組んだことのない人のものだ。
エラーハンドリングとデータ整形に命をかけるのが、今のAI開発のリアルだ。
AI開発のデータ処理に関するFAQ
Q1: AIに読み込ませるデータの「構造化」はなぜ重要なのですか?
LLMは文脈を理解する能力が高い一方で、表形式やレイアウトが崩れたデータからは「意味的な関連性」を誤認しやすいためだ。PDFの表が崩れてテキストとして抽出されると、行と列の対応関係が失われ、AIは誤った数値解釈を行う。文書構造を維持したままマークダウン化することで、LLMは「どこが表で、どこが見出しなのか」を正確に把握でき、推論精度が向上する。前処理はAIの知能を最大限活かすための土台だ。
Q2: ユーザーがアップロードするデータの形式がバラバラな場合、どう対処すべきですか?
「ユーザーに形式を合わせさせる」のではなく、「システム側で自動吸収する」設計がUXの鍵となる。日付列の自動検出や、タブ区切りテキストの自動正規化ロジックをバックエンドに組み込む。また、マルチモーダルな入力データを許容する場合は、強力なAIモデルを「構造化器」として使い、非構造化データをシステムが読み込めるJSON形式に変換するパイプラインを構築するのが現代的なベストプラクティスだ。
Q3: PDFや複雑なレイアウトの文書を扱う際のおすすめのアプローチはありますか?
単なるテキスト抽出ではなく、レイアウト解析や表構造認識を備えた専用の変換ツールを前段に挟むアプローチが有効だ。文書ごとに適した処理を選び、最終的にマークダウンやJSONといった共通形式に統一する。これにより、後続のチャンク分割やRAGへの組み込みがシンプルになる。LLMのチューニングに時間をかける前に、入力する文書の形を整えるだけで結果が変わることは多い。
データが整えば、AIは本気を出す
AIの真価を引き出すのは、プロンプトの魔法ではなく、泥臭いデータの正規化だ。
入力の揺らぎをシステムで吸収する覚悟が、実用的なAIシステムを生む。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
