
ローカル環境で自分専用のAIモデルを動かすのは、もはや一部の研究者だけの特権ではない。
結論から言うと、RTX 4080のような個人向けGPUが1枚あれば、わずか15分で自分専用のLLMを構築できる。
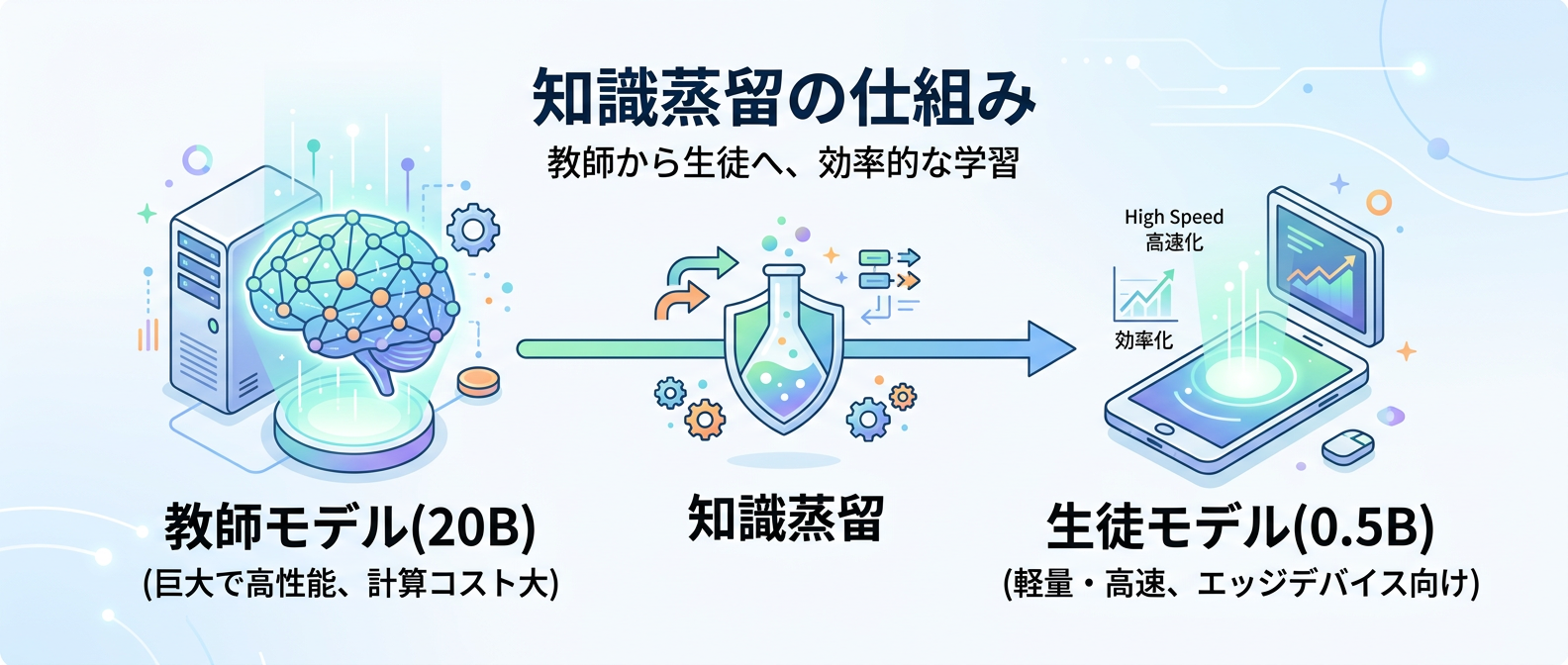
巨大なモデルの知識を、スマホでも動くような小さなモデルに詰め込む「知識蒸留」という技術がそれを可能にした。
この記事では、個人環境で大規模モデルの知識を軽量モデルに蒸留し、最適化するための実践的な6つのステップを解説する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
前提知識:必要な環境とツール
実際に手を動かす前に、必要な環境を整理しておく。
高価なサーバーや複雑な初期設定は不要だ。
手元のPCとオープンソースのツールだけで、十分に実用的なモデルを構築できる。
| 必要なもの | 推奨スペック・ツール | 役割・用途 |
| :--- | :--- | :--- |
| GPU | VRAM 16GB以上(RTX 4080など) | モデルの学習と推論を高速に行う |
| 教師モデル | 20Bクラスのモデル | 高精度な回答を生成し、学習データを作る |
| 生徒モデル | 0.5Bクラスのモデル(Qwen2.5等) | 知識を受け継ぎ、軽量かつ高速に動く |
| 実行環境 | Ollama | 教師モデルを手軽にローカルで動かす |
ステップ1:教師モデルを用いた多様な訓練データの生成
最初のステップは、賢い「教師モデル」に様々なタスクを解かせて、学習データを作ることだ。
たとえば、Ollamaを使って20Bクラスの高精度なモデルを立ち上げ、プロンプトを与えて入力と出力のペアを生成する。
ここで重要なのは、出力に多様性を持たせることだ。
AIの温度パラメータ(temperature)を0.7などに設定すると、毎回少しずつ異なるニュアンスの回答が得られる。
この揺らぎが、特定のタスクに偏らない汎用的なモデルを作るための鍵となる。
同じような質問ばかり繰り返すと、そのカテゴリしか対応できない偏ったモデルになってしまう。
様々なジャンルの質問を投げかけ、100件程度の多様なデータセットを生成するといい。
RTX 4080クラスのGPUなら、このデータ生成は10分から15分程度で完了するはずだ。
ステップ2:データセットの「質とバランス」の最適化
データが集まったら、次はその「質とバランス」を整える作業に入る。
個人環境での小規模な学習において、数万件の大量のデータは必要ない。
むしろ、データは単に量を増やすのではなく、タスク間のバランスと質が圧倒的に重要になる。
たとえば、文章要約のデータばかりを極端に増やしてしまうと、今度は翻訳やプログラミングの質問に対する性能が落ちるというトレードオフが発生する。
少量の高品質なデータセットを厳選し、ノイズとなる不自然な回答を排除することが求められる。
質が高くバランスの取れた100件のデータは、質の悪い1万件のデータよりもはるかに価値がある。
まずは各タスクの割合が均等になるようにデータを間引き、精鋭のデータセットを構築するといい。

ステップ3:LoRAによる軽量モデルのファインチューニング
厳選したデータセットを使って、いよいよ「生徒モデル」を訓練する。
ここでは、0.5Bクラスの軽量モデルに対して、LoRAという手法を用いてファインチューニングを行う。
LoRAを使えば、訓練するパラメータをモデル全体のほんの数%に抑えることができる。
フルスクラッチで学習させると膨大なメモリを消費するが、LoRAならVRAM 16GBの環境でも問題ない。
数分もあればファインチューニングが完了し、教師モデルの賢い振る舞いや答え方のスタイルを小さなモデルに引き継がせることができる。
この「知識蒸留」によって、スマホや一般的なPCでも動く軽量サイズでありながら、高い性能を持つ自分専用モデルが誕生する。
ステップ4:ハイパーパラメータの調整と過学習対策
モデルの訓練がうまくいかない場合、ハイパーパラメータの調整が必要になる。
特に影響が大きいのが、LoRAのrankやエポック数の設定だ。
たとえば、rankを32、エポック数を1.0といった数値に設定して様子を見るのが基本となる。
ここで注意すべきは、rankを高くしすぎると「過学習」を招くという点だ。
表現力が高すぎると、モデルが学習データの表面的なパターンだけを丸暗記してしまい、未知の質問に答えられなくなる。
また、モデルの評価を「eval_loss」という損失の数値だけで判断してはいけない。
lossが下がっていても実際の性能が落ちていることはよくあるため、必ず実際にプロンプトを入力して、期待通りの回答ができるかを確認するといい。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
ステップ5:Instruction Maskingと量子化による精度向上
さらにモデルの精度を上げるためのテクニックがある。
それが「Instruction Masking」という手法だ。
通常の学習では、ユーザーの質問やシステムプロンプトも含めて学習してしまうが、これをアシスタントの応答部分のみに限定する。
AIが回答すべき部分だけを学習させることで、モデルが不要な入力パターンを覚える無駄が省ける。
結果として「何を出力すべきか」に集中できるようになり、少ないデータでも回答精度が大きく向上する。
また、4ビット量子化という技術を組み合わせることも有効だ。
量子化はモデルのサイズを圧縮するだけでなく、暗黙の正則化として働き、過学習を防いで汎化性能を向上させる効果も期待できる。
ステップ6:TICA等による線形Attentionモデルの活用
最後のステップは、さらに高度な最適化を目指す人向けのアプローチだ。
最新のアーキテクチャである「TICA」などの線形Attentionモデルを活用することで、計算量を大幅に削減できる。
従来のモデルは、長い文章を読み込むほど計算量が跳ね上がるという弱点があった。
しかし、RWKVなどの線形Attentionモデルに超小型のAttentionを融合させるTICAの仕組みを使えば、この問題を解決できる。
計算のボトルネックとなる部分を極限まで小さくしつつ、フルサイズに近い品質を維持することが可能になる。
こうした最新の技術トレンドを取り入れることで、個人開発のローカルLLMはさらに進化していく。
まずは手元の環境で動かし、少しずつ新しい手法を試していくのがおすすめだ。
しんたろー:
Claude Codeで毎日コードを書いている身からすると、ローカルLLMの進化スピードには驚かされる。
理由はシンプルで、ちょっと前まで巨大なサーバーが必要だった処理が、今や個人のPCで完結してしまうからだ。
自分で作ったThreadPostの開発でもClaude Codeをフル活用しているが、将来的にはこうしたローカルモデルを補助的に組み込むのも面白そうだ。
TICAのような最新アーキテクチャも非常に気になるので、いずれ自分の環境でも検証してみたい。
つまずきポイント:初心者がハマりやすい3つの罠
ローカルLLMの構築において、初心者がハマりやすいポイントを3つ紹介する。
ここを避けるだけでも、成功率は大きく上がるはずだ。
* データの量を重視しすぎる
* 数万件のデータがないと学習できないと思い込み、質の低いデータを大量に集めてしまうケースが多い。
* 個人環境では、100〜300件の高品質なデータの方がはるかに良い結果を生む。
* lossの低下だけで満足してしまう
* 学習中のeval_lossが下がったからといって、賢いモデルになったとは限らない。
* 過学習を起こしている可能性があるので、必ず実際のタスクでテストする必要がある。
* 最初から大きなモデルを訓練しようとする
* いきなり7Bや8Bのモデルをファインチューニングしようとして、VRAM不足でエラーになる失敗が目立つ。
* まずは0.5Bクラスの極小モデルで一連のフローを体験するのが近道だ。

よくある質問(FAQ)
Q1: 個人のPC(RTX 4080など)でもLLMの学習は可能か?
十分に可能だ。
LoRAという手法を使えば、学習するパラメータ数をモデル全体の数%に抑えることができる。
0.5Bクラスの小規模モデルであれば、VRAMを3GB程度しか消費せず、数分でファインチューニングが完了する。
教師データの生成を含めても、約15分程度で自分専用のモデルを作成できる。
Q2: 知識蒸留(Knowledge Distillation)とは何か?
大規模で高性能な教師モデルの出力結果を学習データとして使い、小規模な生徒モデルを訓練する手法だ。
単に正解を教えるだけでなく、教師モデルの答え方のスタイルや推論の過程まで引き継がせることができる。
これにより、スマホでも動く軽量サイズでありながら、高い性能を持つモデルを作ることが可能になる。
Q3: 学習データの量はどれくらい必要か?
個人環境での小規模な学習では、単純なデータ量よりも質とバランスが圧倒的に重要になる。
プロンプトの温度パラメータを調整して多様性を持たせた100〜300件程度の高品質なデータセットがあれば十分だ。
同じパターンのデータばかりを偏って学習させると、モデルの汎用性が失われるため注意が必要だ。
Q4: 学習がうまくいっているか(過学習していないか)はどう判断すればいいか?
lossの数値だけで学習の良し悪しを判断せず、実際にモデルにプロンプトを入力して確認するのが最も確実だ。
lossが下がっていても、実際のタスクで性能が落ちる過学習が起きていることはよくある。
期待通りの回答や行動ができるかを、実際の下流タスクで評価するといい。
Q5: モデルの精度を上げるためのコツはあるか?
Instruction Maskingという手法を取り入れるのがおすすめだ。
ユーザーの質問やシステムプロンプトを学習対象から外し、AIが回答すべき部分だけを学習させる方法だ。
モデルが不要な入力パターンを覚える無駄が省けるため、少ないデータでも回答精度が大きく向上する。
まとめ
ローカルLLMの構築は、正しい手順を踏めば決して難しくない。
教師モデルから多様なデータを生成し、質とバランスを整え、LoRAで軽量モデルに蒸留する。
この一連の流れをマスターすれば、誰でも自分専用のAIを手に入れることができる。
まずは0.5Bの小さなモデルから始めるのが近道だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
