
AIモデルの追加学習に数千行のPythonコードを書いていた過去のものになった。
今回公開されたTRL v1.0は、複雑な学習ループをたった1つのYAMLファイルに置き換えた。
これは単なるツールのアップデートではない。
モデル学習、アプリ実装、アーキテクチャ設計の全レイヤーでパラダイムシフトが起きている。
AI開発の主戦場が「コード」から「設定ファイル」へと完全に移行したサインだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
属人的な学習スクリプトの終焉
TRL v1.0が正式リリースされた。
これまで研究者向けだったライブラリが、本番環境で使える安定したフレームワークに生まれ変わった。
最大の目玉は、YAML設定とCLIだけでモデルの追加学習を完結できるようになったことだ。
これまで、LLMに特定の指示を従わせたり、複雑な推論能力を持たせたりするPost-Trainingは暗黒の魔術だった。
開発者は実験のたびに、膨大なボイラープレートコードと独自の学習ループを書かざるを得なかった。
データローダーの構築からオプティマイザの設定まで、手作業で組み上げる必要があった。
TRL v1.0は、この属人的なプロセスを完全に標準化した。
SFT、Reward Modeling、DPO、GRPOといった主要な学習プロセスが、共通のAPIで実行できるようになった。
KTOなどの最新の強化学習アルゴリズムも網羅されている。
これらはすべて、直感的な設定ファイルを通じて制御される。
YAMLファイルにモデルパス、データセット、出力先を定義するだけでいい。
あとは専用のCLIコマンドを叩くだけだ。
背後ではHugging Face Accelerateが動き、インフラの違いを完全に吸収する。
ローカルの単一GPUから、クラウド上のマルチノードクラスタまでシームレスに対応する。
FSDPやDeepSpeedを使った高度な分散処理も、コードを1行も変えずにスケールできる。
実験の再現性が100%保証され、保守不能なコードの山から開発者を解放した。
環境構築に費やしていた数十時間が、数分のYAML編集に短縮された。
技術的負債を生み出す独自スクリプトは、もはや不要になった。
モデルの学習フェーズは、完全に設定駆動のフェーズに移行した。
同時に、アプリ実装のレイヤーでも同じ変化が起きている。
LangChainを使った複数LLMの運用において、環境変数やハードコーディングを捨てる動きが加速している。
CSVやYAMLなどの外部設定ファイルでルーティングを制御するアプローチが主流になりつつある。
複数のプロバイダを使い分けるのが当たり前になった現在、単一のAPIキーに依存する設計は脆弱だ。
プロバイダの切り替え、フォールバックの順序、用途別のモデル定義をCSVに切り出す。
Groq、OpenAI、Geminiといった異なるプロバイダを、1つの設定ファイルで一元管理する。
これにより、コードを一切触らずに本番環境のAIの挙動を制御できるようになった。
先頭行をデフォルトモデルに設定するだけで、運用担当者が即座にシステムの挙動を変更できる。
障害発生時も、エンジニアのデプロイを待たずにトラフィックを切り替えられる。
高速なモデルと高精度なモデルの使い分けも、CSVのフラグ一つで制御可能だ。
APIのレートリミットに引っかかった際のフェイルオーバーも、設定ファイルに従って自動で行われる。
さらに、アーキテクチャ設計の領域でも設定駆動の波が来ている。
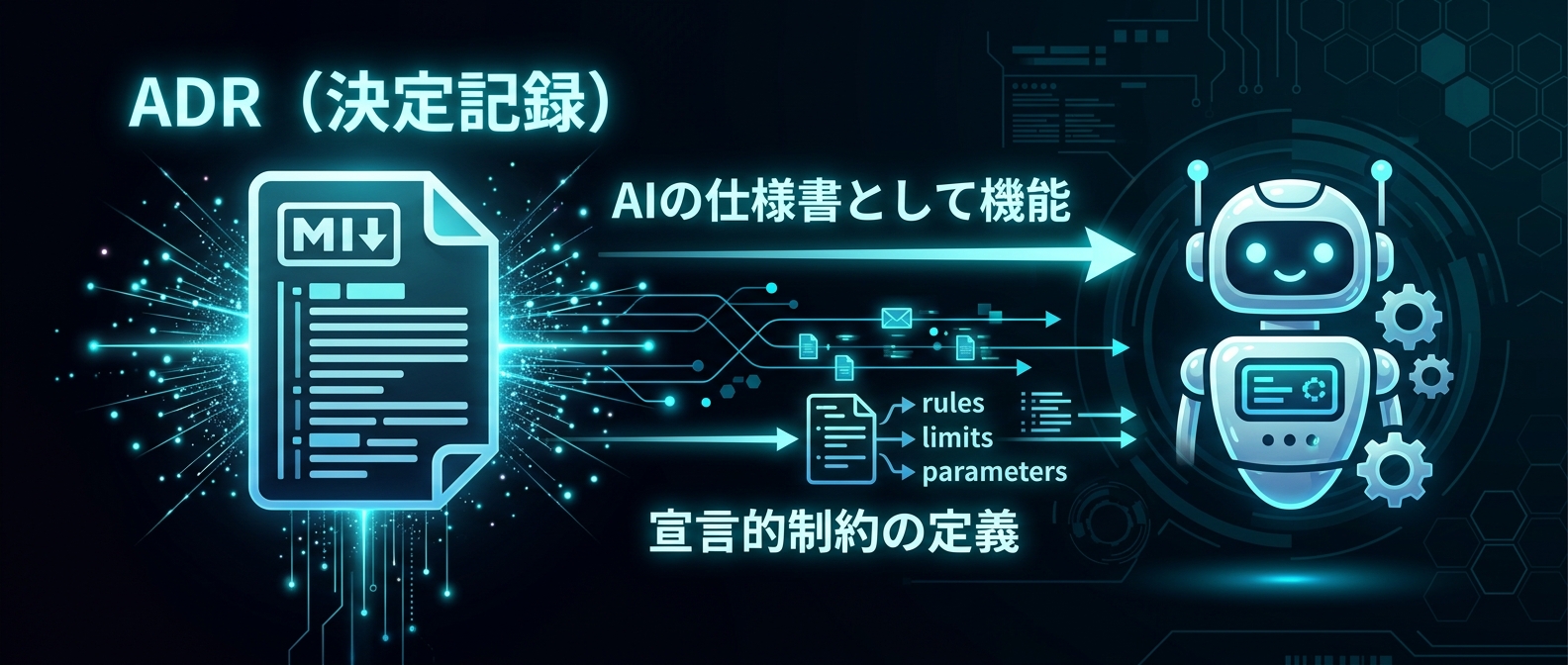
ADR(アーキテクチャ決定記録)をマークダウンで記述し、プロジェクトの専用ディレクトリに配置する。
これまでは人間向けのドキュメントだったADRが、全く新しい役割を獲得した。
Claude CodeのようなAIコーディングエージェントを制御するための、機械可読な仕様書として機能し始めた。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
コードから宣言的制約へのシフト
AI開発のパラダイムが完全に変わった。
主戦場はもう「どうロジックを実装するか」ではない。
「いかにAIやツールを制御するための宣言的な制約を定義するか」に移っている。
しんたろー:
TRLのYAML化、まじで助かる。
学習ループのバグ取りが減りそうで気になってる。
ただ、YAMLのインデントエラーで徹夜する未来も見えてる。
モデル学習のレイヤーを見てみよう。
TRL v1.0のYAML駆動アプローチは、インフラの抽象化という点で非常に優れている。
開発者は「何を学習させるか」という宣言的な設定に集中できる。
「どうやってGPUに分散させるか」という手続き的な処理はフレームワークに丸投げできる。
これにより、パラメータ数10億クラスのモデルでも、コンシューマ向けGPUで効率的に追加学習を回せるようになった。
研究とプロダクションの境界線が完全に消滅した。
ローカルで検証したYAMLファイルを、そのまま本番の学習クラスタに投入できる。
インフラの構成変更が、単なる設定値の書き換え作業になった。
学習のハイパーパラメータも、すべてYAML内で一元管理される。
学習率、バッチサイズ、エポック数が可視化され、Gitでのバージョン管理が容易になる。
どの設定で最も良いモデルができたのか、過去の履歴を正確に追跡できる。
実験の再現性が担保されたシステムが手に入る。
SFTは事前学習済みモデルに特定のタスクを教え込む基礎的な手法だ。
Reward Modelingは人間の好みを数値化する報酬関数を構築する。
DPOは強化学習の複雑なパイプラインを排除し、直接モデルを最適化する。
これらすべてが、単一のYAMLフォーマットで制御可能になった。
アプリ実装のレイヤーも同様だ。
複数のLLMプロバイダを使い分けるシステムにおいて、環境変数だけで運用するのは限界がある。
APIキーの保存には良くても、複雑なルーティングロジックを環境変数で表現するのは不可能だ。
CSVやYAMLに設定を切り出すことで、システム全体のAIの挙動を俯瞰できる。
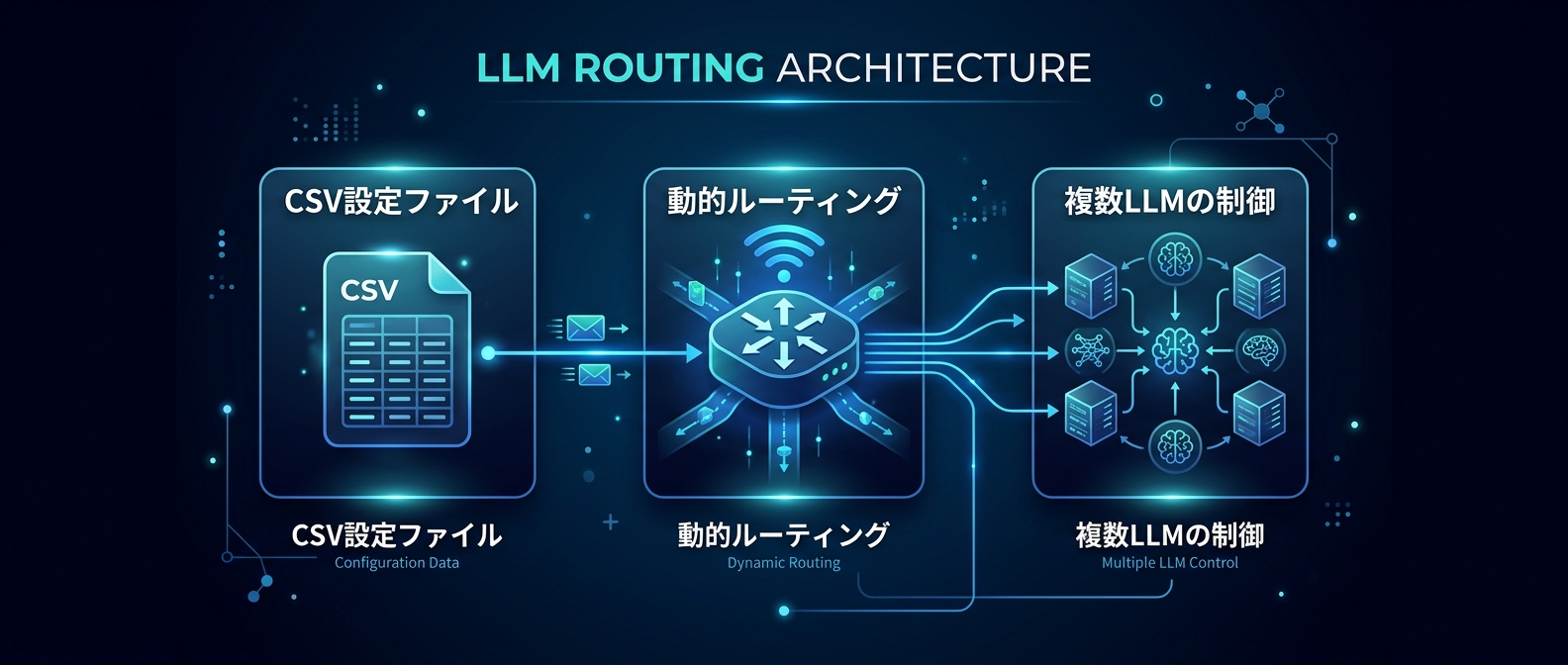
障害発生時も、設定ファイルを書き換えるだけでトラフィックを別のプロバイダに逃がせる。
運用担当者がエンジニアに頼らずとも、安全にAIの挙動を調整できる堅牢なシステムが作れる。
ロジックと設定を完全に分離することで、システムの拡張性は無限に広がる。
新しいプロバイダを追加する際も、CSVに1行追記するだけで済む。
モデルの特性に合わせたプロンプトの調整も、設定ファイルと紐付けて管理できる。
高速応答が求められる機能にはGroqを割り当て、複雑な推論が必要な機能にはOpenAIを割り当てる。
これらのルーティング設定をコードから追い出すことで、ビジネスロジックがクリーンに保たれる。
変更に強い、真にスケーラブルなAIアプリケーションが実現する。
そして、僕ら開発者に最も直結するのが、コーディングAIとADRの組み合わせだ。
Claude Codeを使っていて一番イライラするのは、プロジェクト固有の文脈を無視した提案をしてくる時だ。
一般的なベストプラクティスを押し付けてきて、チームが意図して作ったディレクトリ構造を壊そうとする。
ここでADRが効く。
なぜこの技術を選んだのか。
なぜこの構造にしたのか。
その背景と制約をマークダウンで残し、AIに読ませる。
ADRは単なる議事録ではない。
AIエージェントに対する強力なシステムプロンプトであり、仕様書だ。
Claude CodeにADR読ませるの、マジで効果ある。
毎回「このディレクトリに入れろ」って指示する手間が消えた。
ただし、過去のADRのメンテサボるとAIが混乱してカオスになる。
AIエージェントは、ADRに書かれた制約の範囲内でコードを生成するようになる。
「このプロジェクトでは特定のORMを使うと決まっている。理由は型安全性だ」
これだけで、AIは別のライブラリを使った見当違いな提案をしなくなる。
人間の新メンバーにコンテキストを共有するのと同じように、AIにもコンテキストをインストールする。
設定ファイルやドキュメントが、AIを制御するためのインターフェースに変質した瞬間だ。
コードを書く前にドキュメントを書く。
これが、AI開発における最も効率的な開発手法になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
プロンプトとしてのアーキテクチャ設計
この変化は、僕らの日々の開発にどう影響するのか。
結論から言うと、コードを書く時間は減り、設定ファイルやドキュメントを設計する時間が増える。
AIがコードを書いてくれる現在において、人間の役割は「制約を定義すること」にシフトしている。
まず、LLMの追加学習や実験環境の構築において、独自スクリプトを捨てる時が来た。
TRL v1.0のCLIとYAML設定に乗り換えることで、保守コストは大幅に下がる。
実験の再現性が担保されるため、チーム内でのモデルの共有や比較が容易になる。
インフラ環境が変わってもコードを書き直す必要がない。
学習パイプラインの構築に時間をかけるのは無駄だ。
データセットの準備と評価指標の設計にリソースを集中させる。
YAML設定による宣言的なアプローチは、このリソース配分の最適化を可能にする。
AIモデルの性能向上に直結するタスクだけにフォーカスできる環境が整う。
次に、複数LLMを運用するアプリでは、早急に設定駆動のアーキテクチャに移行する。
ハードコードされたモデル名やプロバイダのロジックを、CSVやYAMLに剥がす。
これだけで、プロバイダの障害や新しい高性能モデルの登場に対して、ダウンタイムゼロで対応できるようになる。
設定ファイルを変更するだけで、システムの既定アシスタントを瞬時に切り替えられる。
プロバイダごとの固有パラメータも、設定ファイル内で一元管理する。
温度パラメータや最大トークン数を、用途別に細かくチューニングできる。
コードの再デプロイなしに、本番環境でA/Bテストを実施することも可能になる。
設定駆動アーキテクチャは、変化の激しいAI業界を生き抜くための必須要件だ。
そして、AIコーディングエージェントを活用するなら、ADR駆動開発を直ちに導入する。
プロジェクトルートに専用のディレクトリを作り、設計の決定事項をマークダウンで記録する。
Claude Codeを起動する際、最初に必ずそのディレクトリを読み込ませる。
「コードを触る前に、必ずADRの制約を確認しろ」と指示する。
ThreadPostのバックエンドも、設定ファイル中心の構成に移行したくなってきた。
ロジックと設定を分離するだけで、AIのコード生成精度が跳ね上がりそうだ。
まあ、設定ファイルの設計ミスってシステム止める未来も見えてるけど。
AIエージェントは一般的な知識は豊富だが、あなたのプロジェクトの歴史は知らない。
なぜフラットな構造ではなくフェーズ別のディレクトリにしたのか。
なぜ最新のライブラリではなく、枯れた技術を選んだのか。
その文脈をADRとして明文化することで、AIの提案採用率は劇的に向上する。
手戻りのない、プロジェクトの規約に完全に準拠したコードが生成されるようになる。
コードレビューの焦点も根本的に変わる。
「この実装は正しいか」ではなく「この実装はADRの制約を満たしているか」になる。
AIが生成したコードを、人間が定義した設定とドキュメントで検証する。
ADRには背景、決定事項、そして制約を明確に記述する。
AIはこれを読み込み、システム全体の整合性を保ちながらコードを提案する。
過去の技術選定の理由が明文化されていれば、AIが古いライブラリを勝手にアップデートする事故も防げる。
プロジェクトのコンテキストをAIと共有することが、開発スピードを最大化する鍵だ。
開発者の主戦場は完全に移動した。
手続き的なロジックの実装はAIとフレームワークの仕事になった。
僕らは、AIが正しく動くための宣言的な設定と制約を設計することに集中する。
YAML、CSV、ADR。
これらが、次世代のAI開発における最も重要なソースコードになる。
AI開発の設定駆動化に関するFAQ
Q1: TRL v1.0のCLIとYAML設定は、既存のカスタム学習スクリプトと比べて何がメリットですか?
最大のメリットは、実験の再現性の向上と、保守が困難なボイラープレートコードの完全な排除だ。
従来、LLMのPost-Trainingでは実験ごとに複雑な学習ループや分散処理のセットアップを独自に記述する必要があった。
TRL v1.0では、これらがYAML設定と単一のCLIコマンドに完全に抽象化されている。
Hugging Face Accelerateと深く統合されているため、インフラ環境が変わってもコードを一切変更せずにスケールさせることが可能だ。
ローカルの単一GPUから大規模なマルチノードクラスタまで、開発チームのイテレーション速度が大幅に向上する。
Q2: 複数LLMを運用する際、なぜ環境変数ではなくCSVや外部設定ファイルを使うのですか?
環境変数はAPIキーの保存や単一モデルの切り替えには適しているが、本番環境での複雑な制御には表現力が不足している。
複数プロバイダの優先順位や、用途別のモデル定義を管理するには限界がある。
CSVやYAMLなどの外部設定ファイルにルーティングロジックを切り出すことで、システム全体の設定状態が一覧できるようになる。
コードを一切変更せずにプロバイダの追加や障害時のトラフィック切り替えが可能になる。
エンジニア以外の運用担当者でも安全かつ迅速にLLMの挙動を調整できる堅牢な運用体制が構築できる。
Q3: AIエージェント(Claude Code等)にADRを読ませる具体的な方法は?
プロジェクトルートに専用ディレクトリを作成し、マークダウン形式でアーキテクチャの決定事項を記述する。
背景と技術的な制約を簡潔にまとめるのがコツだ。
Claude Codeを使用する際、システムプロンプトや初期指示で「コードを生成・修正する前に、必ずADRディレクトリ内のドキュメントを読み、制約に厳密に従うこと」と明記する。
これにより、AIは一般的なベストプラクティスではなく、チーム固有の事情を深く理解する。
特定のライブラリのバージョン制約やディレクトリ構造を厳格に遵守した上で、手戻りのない的確なコード提案を行うようになる。
開発の主導権を握り直す
手続き型コードの記述から解放され、宣言的な制約の設計へと開発者の役割は進化した。
AI開発の全レイヤーで進む「設定駆動」のトレンドを取り入れ、Claude CodeとADRを組み合わせた効率的な開発手法を実践する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
