
AIにコードを書かせる時代は終わった。これからはAIの推論を「制御」する時代だ。
モデルを最新版にアップデートしても、ツール呼び出しが空振りする。
1Mトークンのコンテキストを読ませても、簡単な修正で迷う。
AIの賢さに依存するだけの開発は限界を迎えている。
コンテキストの量と推論の強度をエンジニアリングしなければ、生産性は頭打ちになる。
魔法の箱は消えた。今あるのは、精密なチューニングを要求する複雑な機械だ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
巨大コンテキストとサイレントな不具合の多発
AI界隈の最新のアップデートは、単なるモデルのバージョンアップではない。
開発者がAIをどう扱うか、そのパラダイムシフトだ。
これまで僕らは「より賢いモデル」を求めてきた。今は違う。
1Mトークンという巨大なコンテキストウィンドウが実用化された。
これまでファイル単位で読ませていたコードを、リポジトリ丸ごと投げ込める。
170ファイルを超えるインフラ構成コードと、3万行のアプリケーションコードを同時に分析する。
例えば、モジュールAの権限が、モジュールBのリソースに対して過剰に付与されている状態だ。
これまでは単一ファイルしか見えないため、このクロスモジュールの違反には気づけなかった。
今なら、最小権限違反やリソースのワイルドカード使用を、リポジトリ全体を俯瞰して洗い出せる。
アプリケーションとインフラを同じコンテキストで見られる事実は、開発体験を根底から覆した。
しかし、光の裏には強烈な影がある。
ローカル環境でAIエージェントを動かした際の、サイレントな不具合の多発だ。
同じモデルを使っても、開発者Aの環境では動き、開発者Bの環境ではツール呼び出しが空振りする。
原因はモデルの性能ではない。実行環境のデフォルト設定だ。
2048トークンで入力が切り詰められ、AIは自分が何をするツールなのか知らないまま回答を絞り出す。
出力側も128トークンで強制終了される。
これを「AIがバカになった」と勘違いして、無駄なプロンプト調整に時間を溶かす開発者がいる。
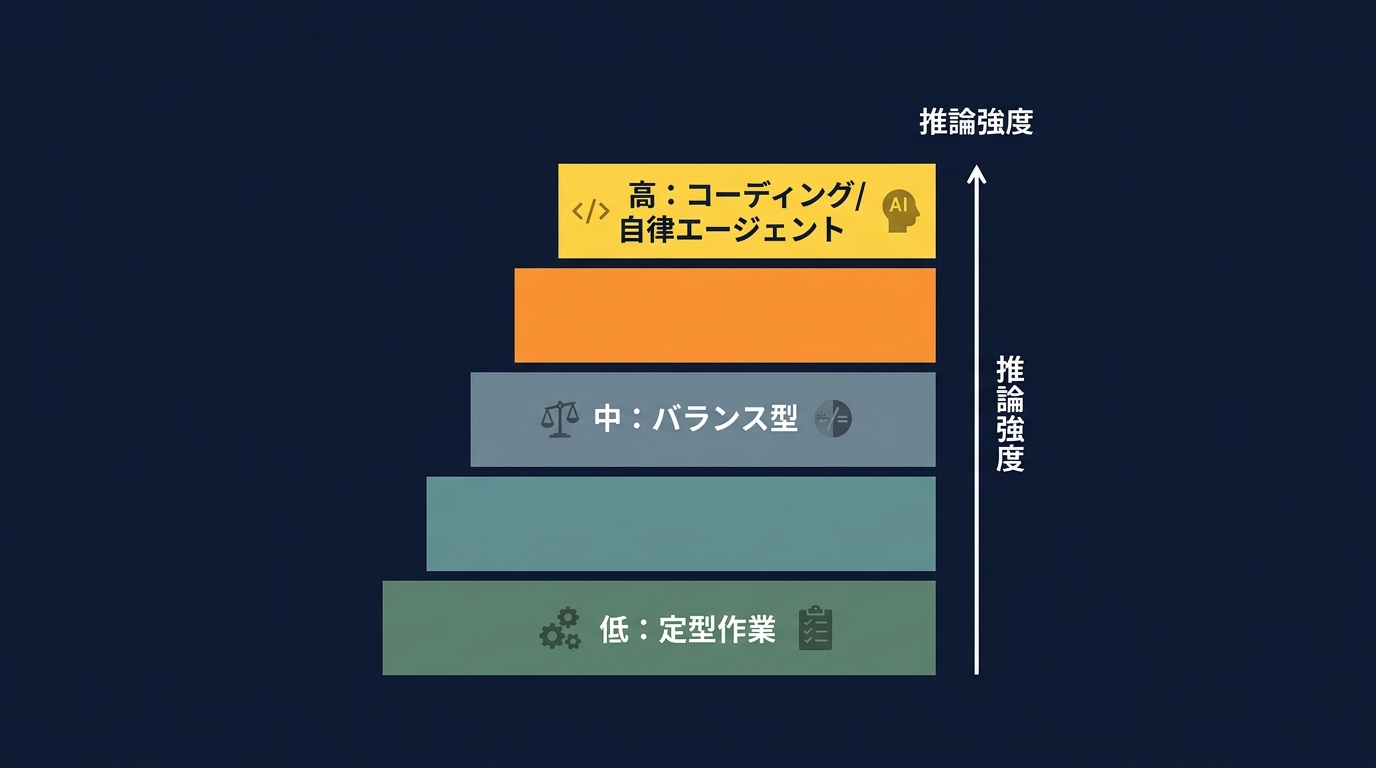
さらに決定的なのが、推論強度というダイヤルの登場だ。
モデルは単一の賢さで動かない。タスクに応じて5段階の推論強度を切り替える仕様だ。
コーディングや長時間の自律エージェント用途では、高い強度が推奨される。
単純なポーリング作業や定型フォーマットの変換に高い強度を当てると、無駄に深く考えすぎてコストだけが跳ね上がる。
AIは「プロンプトを入れたら答えが返ってくる箱」ではない。
入力の長さを管理し、実行環境の制約を突破し、推論の深さを設計する。
インフラ構築と同じ、エンジニアリングの対象だ。

※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
ブラックボックス化するAIの挙動とキャッシュ戦略
Claude Codeで毎日コードを書いていると、この変化の波を肌で感じる。
モデルが賢くなっても、挙動がブラックボックス化してデバッグが極めて難しくなっている。
最大の罠は「全部読ませれば精度が上がる」という幻想だ。
1Mトークンのコンテキストは強力だ。
しかし、不要なログファイルや自動生成コード、巨大な依存ライブラリまで突っ込むと、AIは情報の海で溺れる。
コンテキストが長くなればなるほど、中盤の重要な情報が軽視される傾向にある。
分厚いマニュアルの真ん中あたりに書かれた注意事項は、誰も読まない。
重要な制約事項はプロンプトの冒頭か末尾に置かないと、あっさり無視される。
ノイズを意図的に除外する設計が、これまで以上に求められる。
避けて通れないのがコストの問題だ。
1Mトークンを毎回フルで読ませれば、API破産は免れない。
ここで必須になるのがプロンプトキャッシュの活用だ。
エージェントツールのセッションを維持し、5分以内に連続して質問を投げる。
これでコストは一桁下がる。キャッシュが効くかどうかで、開発の持続可能性が決まる。
プロンプトキャッシュは、単に安くなるだけの機能ではない。
開発のテンポを変えるインフラ技術だ。
通常、1Mトークンの入力には数分単位の処理時間がかかる。
キャッシュにヒットすれば、これが数秒で返ってくる。
リアルタイムなコードレビューが成立するのは、このキャッシュ機構があるからだ。
しんたろー:
1Mコンテキストのキャッシュヒットは爽快だ。
セッション切れた直後に重い質問を投げて、API料金のダッシュボードを見て驚いたことがある。
キャッシュのTTL管理は命綱だ。
さらに厄介なのが、ローカル環境との連携だ。
APIの利用制限を回避するために、ローカルの推論モデルをエージェントのバックエンドに据える構成が流行っている。
ここで「AIが急にバカになった」と嘆く開発者がいる。
原因はローカルランナーの初期設定にある。
デフォルトのコンテキスト長が2048に設定されていることが多い。
エージェントツールのシステムプロンプトは、平気で5000トークンを超える。
結果として、プロンプトの先頭にある「あなたは優秀なコーディングアシスタントです」という指示が、AIに届く前にサイレントに捨てられている。
モデルはツールの存在を知らない。だから使えない。
出力側も同様の悲劇が起きる。
デフォルトの出力上限が128トークンに制限されていることがある。
AIが長文のコードや複雑なフォーマットのツール呼び出しを生成しようとしても、途中で強制終了される。
画面上は「AIが途中で黙った」「壊れたデータを返してきた」ようにしか見えない。
これをモデルの性能不足だと勘違いして、別のモデルに乗り換えても、同じ悲劇が繰り返されるだけだ。
インフラのレイヤーで起きている問題を、プロンプトのレイヤーで解決しようとすると迷走する。

環境を支配するための実地プローブと強度設計
僕らの開発への影響は大きい。
AIへの「おまかせ」は通用しない。
開発者はAIの機嫌を取るのではなく、環境を支配する。
まず、ローカル環境でエージェントを動かすなら、プローブによる環境診断が必須だ。
プロンプトの切り詰めが起きていないか確認するテストだ。
学習データに存在しない、ランダムな英数字の文字列を入力の先頭に仕込む。
そしてプロンプトの末尾で「さっきの文字列を出力して」と指示する。
これが出力されなければ、環境はAIの記憶を勝手に消去している。
今すぐ設定ファイルを開き、コンテキスト長の上限を引き上げる。
ヒューリスティックな推測ではなく、実地プローブで事実を確認する。これがエンジニアのやり方だ。
推論強度のコントロールも重要だ。
新しいモデルでは、タスクの複雑さに応じて推論の深さを設計する。
推論強度のダイヤルは、単なる思考時間の延長ではない。
ツール呼び出しの回数、本文の長さ、コメントの充実度までが一括で変わる。
最も効率的なレベルは、短く範囲が限定されたタスクに使う。
バランス型は、コストを重視する平均的なワークフローに。
コーディングや自律エージェントの推奨開始点となるのが、新設された高い強度のレベルだ。
真のフロンティア問題にのみ使う最高レベルは、過剰思考のリスクがありコストも大幅に増える。
Claude Codeの裏側で推論強度がどう切り替わっているのか、ブラックボックスなのが気になる。
複雑なタスクの途中で勝手に強度を下げられて、浅い回答を出されると困る。
CLIのオプションで「ここは全力で考えろ」と強制指定できるようになるのが待ち遠しい。
例えば、ブラウザを使ったテストの自動化を考えてみる。
画面の要素を探し、クリックし、エラーが出たらログを見て修正する。
この「反復的なツール呼び出しと仮説検証」のサイクルには、高い強度が刺さる。
一方で、クラウド環境へのデプロイやビルドの完了を待つだけのポーリング処理があるとする。
ただ完了ステータスを確認するだけの作業に、高い強度を使うのは無駄遣いだ。
フェーズによって最適な推論強度は違う。
タスクがツール呼び出しを繰り返すのか、複雑な推論を必要とするのか、短く限定的か。
このフローチャートを頭に描きながら、プロダクト全体のAI呼び出しをマッピングする。
「ここは強度が過剰」「ここは足りない」という凸凹が見えてくる。
大規模リポジトリを扱う際のディレクトリ設計も、AI時代に合わせて変える。
AIに読ませたいコアロジックと、読ませたくない自動生成ファイルや依存ライブラリを明確に分離する。
「ここからここまではコンテキストに含める」「ここは除外する」というルールを、プロジェクトの初期段階で決める。
ノイズを減らすことが、AIの回答精度を上げる近道だ。
APIの決定性についても注意が必要だ。
これまで決定性を高めるために、温度パラメータを0に設定していたコードが、新しいモデルに切り替えた瞬間にエラーを吐くことがある。
パラメータの扱いが厳格化されているからだ。
モデルを差し替えるだけで動く時代は終わった。
影響範囲を正確に見極め、コードを修正する。
よくある質問と実務的な回答
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
Q1: Claude Codeで「モデルがバカになった」と感じる原因は?
多くの場合、モデルの性能低下ではなく「コンテキストの切り詰め」や「ツール呼び出しの失敗」が原因だ。
特にローカル環境を併用している場合、デフォルト設定(コンテキスト長2048など)により、プロンプトの先頭が捨てられている可能性が高い。
システムプロンプトが欠落すれば、AIは自分が何者かさえ分からない。
まずはランダムな文字列を使ったプローブテストで、入力が正しくモデルの奥底まで届いているか確認する。
Q2: 1Mトークンをフル活用する際のコスト対策は?
プロンプトキャッシュの活用が絶対条件だ。
エージェントのセッションを維持し、5分以内の有効期限内で連続して質問を投げることでキャッシュヒット率を高められる。
また、すべてのファイルを常に読み込ませるのではなく、タスクに関連するモジュールのみを抽出する設計を行うことで、ノイズを減らしつつコストを削減できる。
「何を見せないか」を決めるのが、今のAI開発の要だ。
Q3: Claude Code側で推論強度(effort)は変更できる?
現時点では、Claude Code側で推論強度を明示的に指定する手段は提供されていない。
内部のエージェントが自動的に最適化を行うブラックボックス仕様だ。
特定のタスクで「もっと深く考えてほしい」「もっと簡潔に済ませたい」という要望がある場合は、エージェントツールではなくAPIを直接叩く実装へ切り替えるのが現実的だ。
制御を手放したくなければ、自分でコードを書くしかない。
APIを直接叩くスクリプトを書くのは手間だが、コスト管理を考えると避けられない道だ。
自動化ツールを作っていても、最後は泥臭いチューニングに行き着く。
AI開発は、どんどん職人芸になっている。
まとめ
AIの進化は、僕ら開発者に「魔法」ではなく「より複雑な操縦桿」を与えた。
ブラックボックスを恐れず、エンジニアリングの力でAIを制御する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
