
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIの「待ち時間」が消える。推論高速化のパラダイムシフト
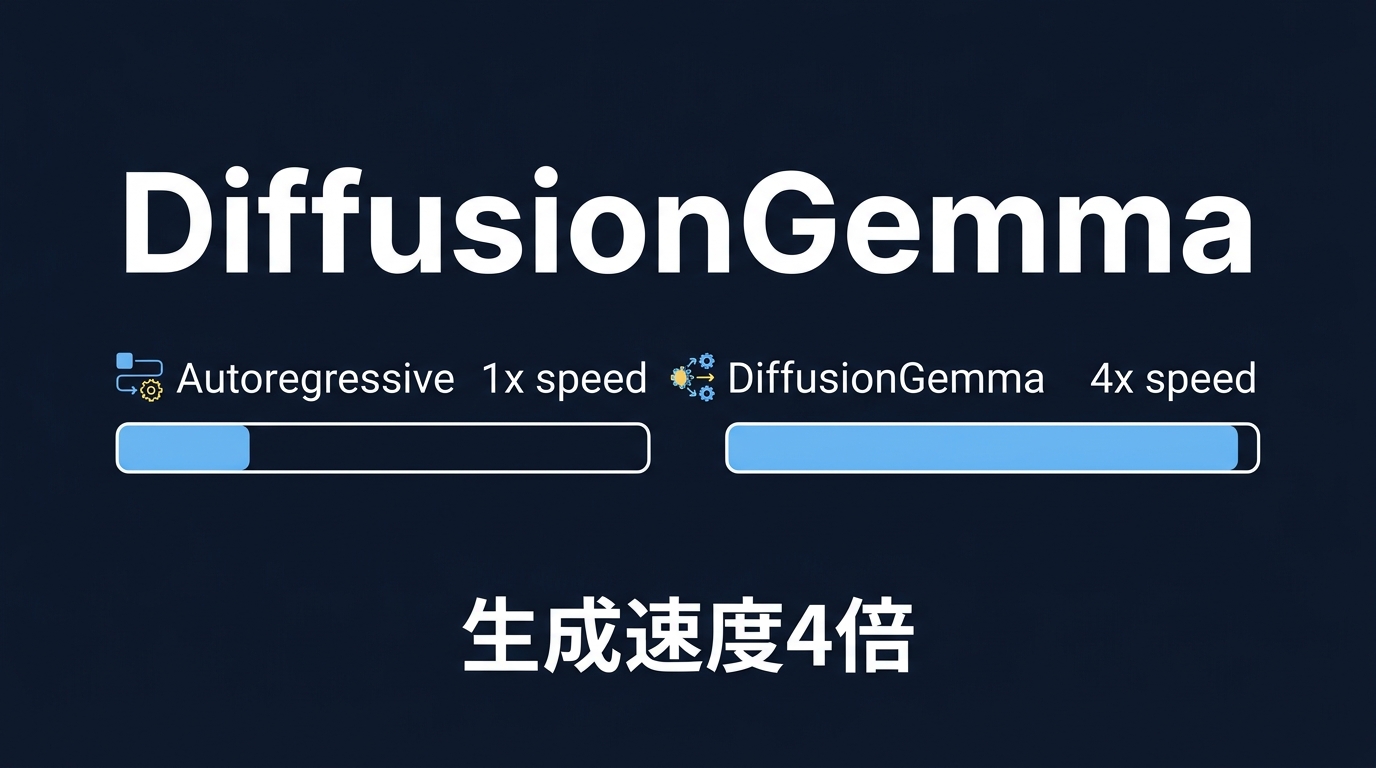
AIの進化は賢さの競争から速度と効率のフェーズへ移行した。Googleが発表したDiffusionGemmaは、GPU上での推論速度を4倍に引き上げた。
シリコンバレーのGimlet Labsは、ハードウェアの利用効率を極限まで高めることで推論のボトルネックを解消する。Midjourneyの最新モデルV8は、生成速度を5倍に高速化した。
開発者が直面してきた推論コストとレイテンシの壁が崩れ始めている。この高速化の二極化を乗りこなすための核心に迫る。
テキストを「1文字ずつ打つ」時代から「一気に印刷する」時代へ
推論の高速化は2つの異なるアプローチで進んでいる。1つはモデルのアーキテクチャ刷新であり、その筆頭がGoogleのDiffusionGemmaだ。
このモデルは26Bの規模を持つMixture of Experts(MoE)構成を採用している。従来の自己回帰型モデルは、タイプライターのように1トークンずつ順番に文字を生成していた。
DiffusionGemmaは、独自の拡散ヘッドを搭載し、256トークンのブロックを同時に生成する。並列デコードにより、専用のGPUやTPU上での推論速度が向上した。
Gimlet Labsは、マルチシリコン推論クラウドという概念を打ち出した。現在のAIアプリは既存のハードウェアリソースの15%から30%しか活用できていない。
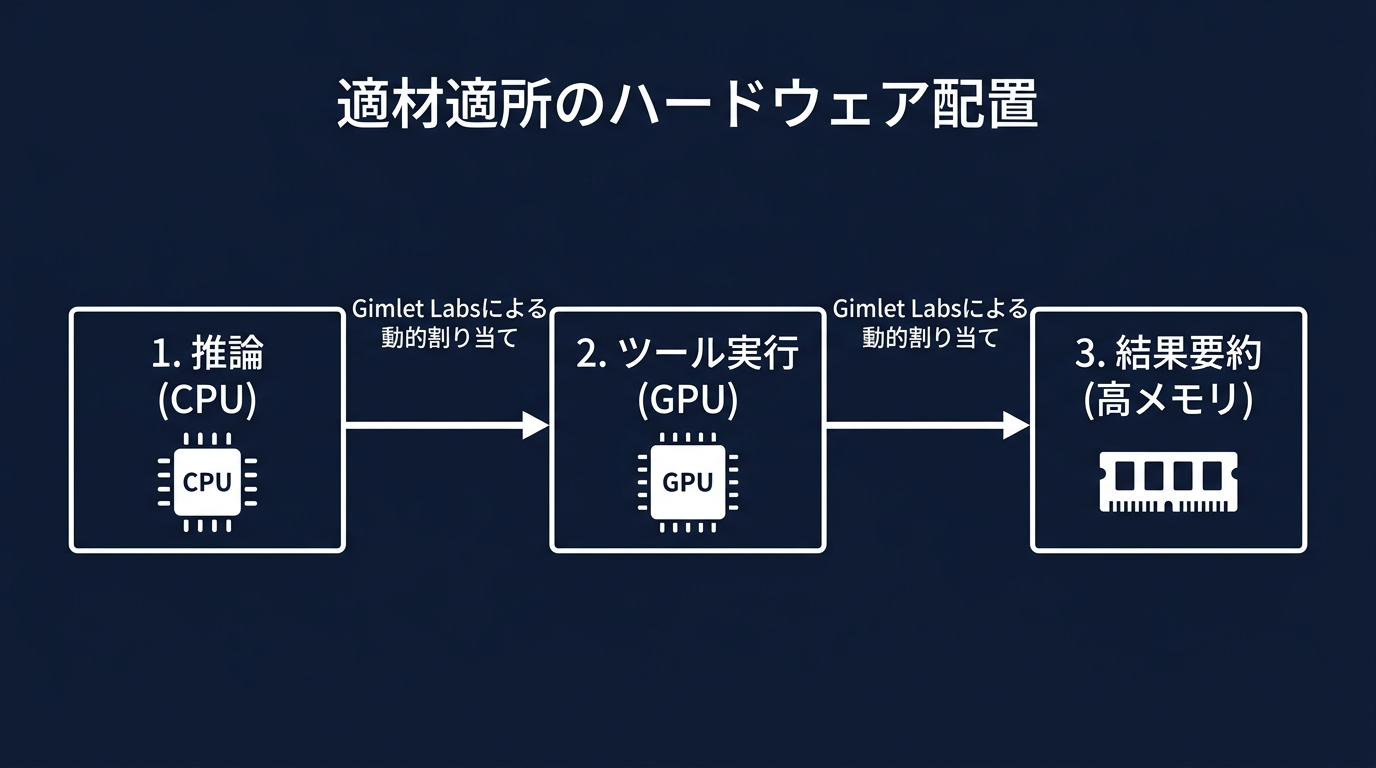
彼らが開発したオーケストレーション・ソフトウェアは、AIエージェントのワークロードを分解し、CPU、GPU、高メモリシステムへ動的に割り当てる。この適材適所の配置により、同じコストで3倍から10倍の効率化を実現する。
画像生成の分野ではMidjourney V8がアルファ版として登場した。生成速度は従来の5倍に達する。
しんたろー:
1トークンずつ律儀に生成するのを待つ時間は、開発者にとってストレスだ。DiffusionGemmaの「塊で出す」発想は、ローカルLLMのUXを変える。ハードウェアが遊んでいるというGimletの指摘も、クラウド破産しそうな開発者には刺さる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線の解説:推論の「質」と「速さ」のトレードオフ
今回のニュースから、速度向上の定義が文脈によって異なる事実が見える。開発者は、プロダクトが必要とする高速化を見極める必要がある。
DiffusionGemmaが提示した拡散型テキスト生成は、ローカル推論において威力を発揮する。クラウドサーバーであれば数千人のリクエストをバッチ処理できるが、ローカル環境ではGPUの計算資源が余りやすい。
DiffusionGemmaはこの余白を埋める。双方向アテンションを活用することで、未来のトークンの情報を参照しながら現在のブロックを生成する。

拡散モデルは並列処理に優れる反面、複雑な論理的指示や長大な文脈の保持においては、自己回帰モデルに一歩譲る。Midjourney V8が一部の複雑なプロンプトで苦戦しているという報告は、このアーキテクチャの限界を示唆している。
Gimlet Labsのアプローチは、モデルの中身を変えずにインフラの動的な切り出しで解決を図る。これはAIエージェント開発において重要になる。
エージェントは推論、ツール実行、結果の要約という工程を繰り返す。Gimletの技術は、工程ごとに最適なチップへ処理を飛ばす。高価なH100をツール実行の待ち時間で遊ばせる無駄を省く。
Claude Codeを使ってると、推論の待ち時間で思考が途切れる。モデルを賢くするのも大事だが、このインフラの最適化が進めば、1回のプロンプトで10個のファイルを直すような重い処理も爆速で終わる。結局、開発効率は推論の往復時間で決まる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響:開発アーキテクチャの変容
この高速化の波を受けて、開発者が意識すべきアクションは3つある。
第一に、フロントエンド推論とバックエンド推論の分離だ。入力補完やリアルタイムの文章校正には、DiffusionGemmaのような拡散型モデルをローカルで走らせる設計が主流になる。
第二に、推論コストの構造に対する理解のアップデートだ。Gimlet Labsがパートナーシップを組むNVIDIA、AMD、Intel、ARM、Cerebrasの顔ぶれを見れば分かる通り、推論環境は多様化している。
第三に、拡散モデル特有のプロンプトエンジニアリングへの適応だ。Midjourney V8の事例が示すように、モデルの構造が変われば最適な指示の出し方も変わる。
Midjourney V8では、高速化と高画質化の一方で、一部の高度な機能の利用料金が引き上げられた。速度をお金で買うというモデルが鮮明になっている。
うちのThreadPostの開発でも、SNS投稿の生成は速さが命だ。ユーザーがボタンを押してから3秒待たされるか、0.5秒で出るかで継続率が変わる。全部を最強モデルに投げるんじゃなくて、この推論の適材適所を実装できる奴が勝つ。技術選定の難易度は上がったが、やりがいはある。
FAQ:推論高速化に関する疑問
Q1: DiffusionGemmaは既存のLLMの完全な代わりになりますか?
いいえ、完全な代替にはなりません。DiffusionGemmaは同時生成を行うため、コード補完やインライン編集のような用途には最適ですが、複雑な論理推論や長い文脈を保持するタスクでは、自己回帰型モデルの方が高い精度を維持します。
Q2: Gimlet Labsの技術は個人開発者でも今すぐ使えますか?
現時点では、Gimlet Labsは大規模なモデルラボやデータセンターをターゲットにしており、個人開発者が直接触れるツールではありません。将来的には、クラウドプロバイダーのAPIの裏側でこの技術が採用され、安くて速いAPIという形で恩恵を享受することになります。
Q3: 拡散モデルと自己回帰モデル、結局どちらを選ぶべきですか?
判断基準は速度とインタラクティブ性か、論理的な正確性かです。UIのレスポンス向上や構造化データの高速生成を求めるなら拡散モデルを、プロンプトの細かなニュアンスへの追従や複雑な指示の遂行を重視するなら自己回帰モデルを選択してください。
結論:推論を制する者がAIプロダクトを制する
AI開発の主戦場は推論の効率化にシフトした。モデル側ではDiffusionGemmaが並列処理の道を切り開き、インフラ側ではGimlet Labsがハードウェアの無駄を削ぎ落とす。
開発者に求められているのは、それぞれのモデルが持つ生成の仕組みを理解し、自分のプロダクトのどの機能に、どのアーキテクチャを割り当てるべきかを選択する眼力だ。
AIが賢いのは当たり前になった。これからは、その賢さをいかに速く、いかに安くユーザーに届けられるかが勝負の分かれ目になる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
