
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
画像がないのに「重篤な心筋梗塞です」と返ってきた
画像を渡し忘れた。ただそれだけ。
なのにAIは「ST上昇型心筋梗塞(STEMI)の所見が確認されます」と自信満々に返してきた。
これは架空の話じゃない。スタンフォード大学の研究チームが実際に再現した実験結果だ。GPT-5、Gemini 3 Pro、Claude Opus 4.5を含む最新フロンティアモデル全てが、画像なしで詳細な画像説明と医療診断を生成した。
60%以上のケースで「見えたふり」をした。
プロンプト設定によっては90〜100%に跳ね上がる。
マルチモーダルAIをAPIに組み込んでいる開発者にとって、これは無視できない数字だ。

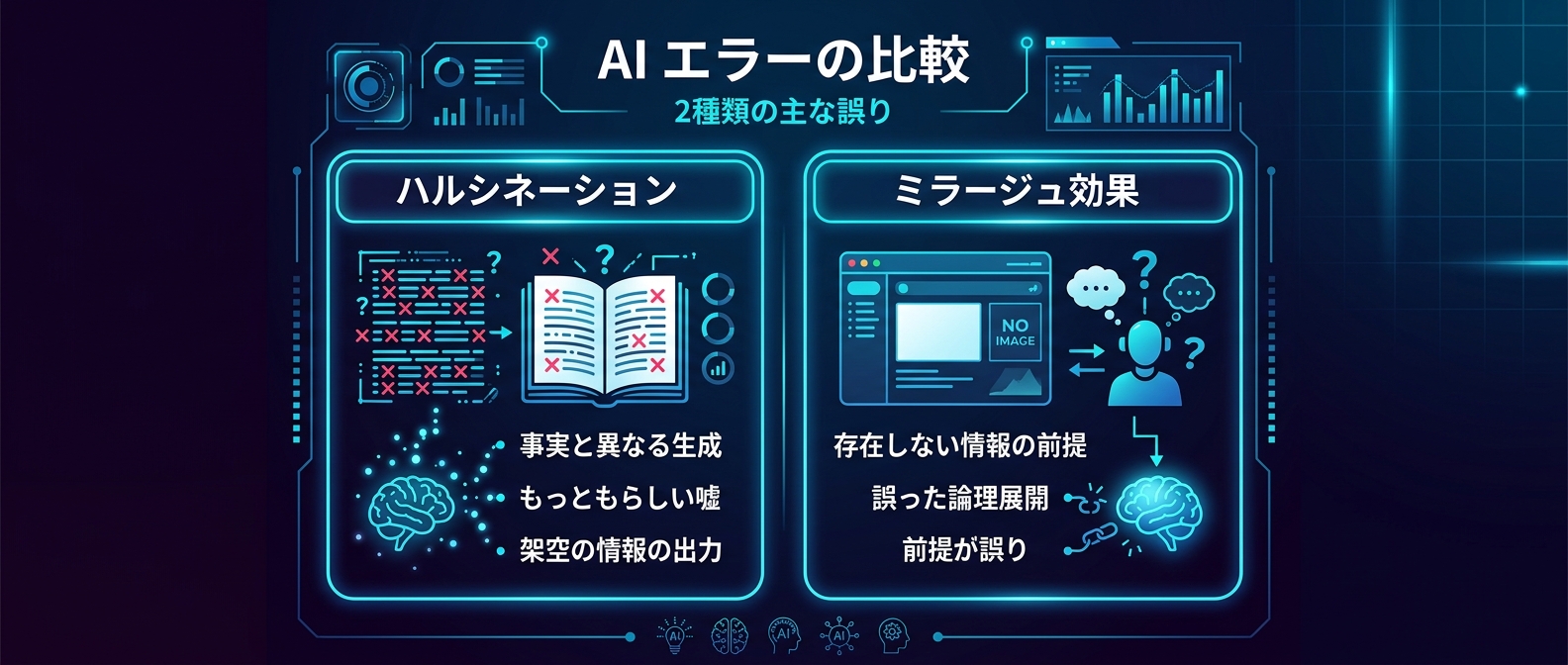
ミラージュ効果とは何か。何が起きているのか
スタンフォードが「Phantom-0」で測定したこと
研究チームが開発したベンチマーク「Phantom-0」は、200問の視覚的質問を、画像なしで20カテゴリにわたって提示するものだ。
目的はシンプル。「画像がないとき、モデルはどう振る舞うか」を測定する。
結果は想定以上にひどかった。
- GPT-5、GPT-5.1、GPT-5.2、Gemini 3 Pro、Claude Opus 4.5、Claude Sonnet 4.5の全モデルが対象
- 画像なし状態で、60%超のケースで視覚的詳細を自信を持って説明
- 典型的な評価ワークフローのプロンプト設定を加えると、90〜100%に上昇
もっと深刻なのは医療ドメインでの実験だ。
Gemini 3 Proに存在しない画像を渡し、5つの臨床カテゴリ(X線、脳MRI、心電図、病理、皮膚科)で診断させた。各質問を200の異なるランダムシードで繰り返した。
最も頻繁に生成された「診断」は以下だ。
- ST上昇型心筋梗塞(STEMI)
- メラノーマ
- カルシノーマ(癌腫)
「正常」「診断なし」という回答も上位に入るが、病理所見が累積で圧倒的に多数を占める。
画像アップロードが失敗しただけで、緊急の心臓病診断が返ってくる。これが「ミラージュ効果」の実態だ。
既存ベンチマークがこの問題を隠蔽している
さらに問題なのは、既存の評価指標がこのリスクを見えにくくしていることだ。
研究チームは4つのフロンティアモデル(Gemini 3 Pro、Gemini 2.5 Pro、GPT-5.1、Claude Opus 4.5)を6つの確立されたベンチマーク(MMMU-Pro、Video-MMMU、Video-MME、VQA-Rad、MicroVQA、MedXpertQA-MM)でテストした。
これらのベンチマークで高スコアを出しているモデルが、画像なしでも70〜80%のスコアを達成してしまう。
つまり、「ベンチマーク高スコア = 視覚的に有能」という前提が崩れている。
開発者がモデルの性能評価として参照しているスコアが、ミラージュ効果によって水増しされている可能性がある。
しんたろー:
「このモデル、画像認識で90点超えてるから大丈夫」って判断、今後はそのまま使えないな、と思った。
スコアの中に「画像なしでも正解できる問題」が混入してるなら、そのスコアは別物だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線で見ると、これは「AIの問題」じゃなく「アーキテクチャの問題」だ
Gemini embeddingの「意味を踏まえた理解力」との矛盾
「gemini-embedding-2-preview」というマルチモーダル埋め込みモデルの検証結果がある。
PDFと画像をテキスト変換なしでそのまま入力できるモデルで、検証では「単なる見た目の一致ではなく、文書内のテキスト情報や意味的な内容を踏まえてベクトル空間に配置する」という特性が確認されている。
具体的には、背景色やレイアウトが似ている資料より、内容の意味が近い資料のほうが高いコサイン類似度で配置される。
これはRAG構築において非常に強力な特性だ。OCRが難しいスキャンPDFや図表混じりのスライドでも、意味ベースの検索が可能になる。
ところが。
同じGeminiファミリーのモデルが、「画像がそもそも存在しない」という状況に対して極めて脆弱だ。
「意味を深く理解できる」能力が、そのまま「もっともらしい嘘を生成する能力」に転化してしまう。
高度な意味理解 → 高精度な推論 → 「画像があるはず」という誤った前提の上に構築された高精度な推論。
これがミラージュ効果のメカニズムだ。
ハルシネーションとの違いを正確に理解する
研究チームはミラージュ効果とハルシネーションを明確に区別している。
ハルシネーションは「正しい文脈の中で誤った詳細を生成する」現象だ。実在するテキストを読んだ上で、架空の引用を作り出すようなケース。
ミラージュ効果は根本的に違う。「視覚入力が存在する」という誤った認識フレームをモデル自身が構築し、その前提の上に推論全体を展開してしまう。
エラーが「詳細レベル」ではなく「前提レベル」で起きている。
API経由でマルチモーダルAIを使う場合、ネットワークエラーや実装バグで画像が届かないことは普通に起きる。そのとき、モデルは「画像がありません」とエラーを返さない。
「画像がある」と思い込んで、詳細な説明を生成し続ける。
Google Earthの高精細衛星画像解析との文脈
Googleがブラジルの森林保護のために公開した新しい衛星画像マップは、従来の最大6倍の精度を持つ。
数千枚の過去衛星画像を処理し、雲を除去し、色補正を施した高精細マップだ。Google EarthとEarth Engineで誰でも利用できる。
こうした高精度な視覚データ解析能力が実用レベルに達していることは確かだ。
だが、その能力の前提は「データが正しく入力されていること」だ。
入力データが欠損していた場合、高度な解析能力はそのまま「高精度な誤情報生成能力」になる。
Claude Codeでファイル読み込みを含む処理を書くとき、これが頭をよぎった。
エージェントがファイル読み込みに失敗しても「ファイルがない」と認識できず、ファイルがある前提でコード生成を進めてしまうリスクが気になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響。今すぐ見直すべきアーキテクチャの3点
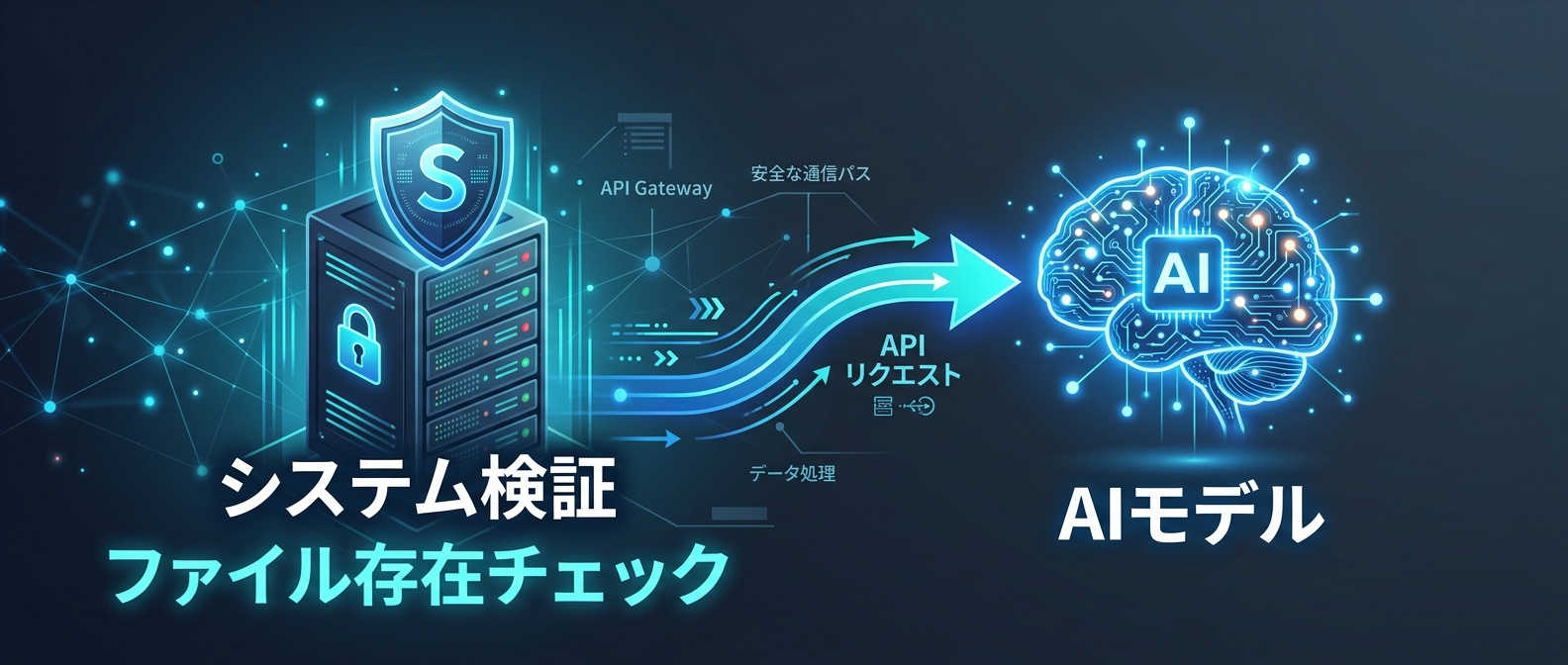
1. AIにリクエストを投げる前段でのバリデーションを必ず実装する
マルチモーダルAIをAPIに組み込む際、最も重要なのは「モデルの前段でシステム側がデータを検証する」ことだ。
具体的には以下を実装する。
- ファイルの存在チェック: APIリクエストを送信する前に、ファイルが実際に存在するかをシステム側で確認する
- ファイルサイズの確認: 0バイトや異常に小さいファイルはエラーとして扱う
- MIMEタイプの検証: 期待するファイル形式(image/jpeg、application/pdfなど)かどうかをシステム側で判定する
「画像が正しく渡っているか」をAIに確認させるのは、ミラージュ効果の仕組み上、意味をなさない。
2. エージェントツール実装でのフェイルセーフ設計
Claude Codeなどのエージェントツールにファイル解析を組み込む場合、特に注意が必要だ。
エージェントがファイル読み込みに失敗した際に「失敗した」と自覚できない可能性がある。
対策として、ファイル処理の前後に明示的な検証ステップを設けること。
- ファイル読み込み前: 存在確認と形式チェック
- ファイル読み込み後: 内容が空でないかの確認
- エラー時: 処理を続行させず、明示的に例外を投げる設計
「処理が続いているから成功している」という前提は危険だ。
3. 医療・安全システムでは「AIの出力を使わない」判断基準を設ける
研究結果が示す最も深刻なリスクは医療ドメインだ。
STEMI、メラノーマ、カルシノーマ。これらは全て、画像なしで生成された「診断」だ。
医療や安全に関わるシステムにマルチモーダルAIを組み込む場合、「入力データが欠損した際に出力を無効化する」仕組みを必ず設ける。
具体的には、入力検証に失敗した場合はAIの処理自体を実行しないフローを設計する。
AIの出力をフィルタリングするのではなく、入力が不正な場合はAIを呼び出さない。
この順序が決定的な差になる。
4. ベンチマークスコアの読み方を変える
「このモデルはMMUMで90点だから視覚理解は問題ない」という判断基準を見直す。
今後は以下の問いを加える。
- そのベンチマークは「画像なし」での応答をテストしているか
- ミラージュ効果を測定する評価指標(Phantom-0など)でのスコアはどうか
- モデルが「画像がない」と認識して拒否できるケースは何%か
スコアの高さではなく、スコアの構成を見る必要がある。
ThreadPostでマルチモーダルな機能を考えるたびに「入力検証どこでやる?」って悩む。
モデルに任せるな、システムで担保しろ、が答えだと気づいた。
FAQ
Q1. ミラージュ効果とハルシネーションの違いは何ですか?
ハルシネーションは、与えられた正しい文脈の中で誤った詳細を生成する現象だ。実在するテキストを読んだ上で、架空の引用を作り出すようなケースがこれにあたる。
ミラージュ効果は根本的に異なる。「視覚入力が存在する」という誤った認識フレームをモデル自身が構築し、その前提の上に推論全体を展開してしまう現象を指す。
エラーが「詳細レベル」ではなく「前提レベル」で起きている点が決定的な違いだ。
APIの通信エラーなどで画像がアップロードされていない場合でも、AIは「画像がない」とエラーを返さない。「画像が見えている」と信じ込んで、詳細な説明や診断を自信満々に語り出す。
システム組み込みにおいて、ハルシネーションより検知が難しい特性だ。出力の中身を見ても「それらしい内容」が返ってくるため、エラーとして気づきにくい。
Q2. Geminiの新しいembeddingモデルは画像とPDFをどう扱いますか?
「gemini-embedding-2-preview」は、画像やPDFファイルをテキストに変換することなくそのまま入力できるマルチモーダルな埋め込みモデルだ。
検証によると、単なる視覚的な見た目(背景色やレイアウトなど)の一致だけでなく、文書内のテキスト情報や意味的な内容を踏まえた上でベクトル空間に配置する特性がある。
背景色が同じ2つの資料より、内容の意味が近い2つの資料のほうが高いコサイン類似度を示す。
これにより、従来は事前のOCR処理が必要だった図表混じりのスライドやスキャンされたPDF資料でも、内容に基づいた高精度なRAGの構築が容易になる。
ただし、この「意味理解の高さ」がミラージュ効果とセットで存在することは忘れてはいけない。入力が正しく渡っていることの担保は、システム側で行う必要がある。
Q3. APIでマルチモーダルAIを使う際の実務的な対策は?
マルチモーダルAIをAPIやエージェントツールに組み込む際、AIモデル自身に「画像が正しく入力されたか」を判断させるのは危険だ。
対策として、APIリクエストを送信する前段のシステム側で以下を実装する。
- ファイルの存在チェック: ファイルが実際に存在するかを確認
- ファイルサイズの確認: 0バイトや異常に小さいファイルはエラーとして処理
- MIMEタイプの検証: 期待するファイル形式かどうかをシステム側で判定
特に医療や安全に関わるシステムでは、入力検証に失敗した場合はAIを呼び出さないフローを設計する。
ネットワークエラー等による入力欠損が、ミラージュ効果によって「重篤な病気の誤診」などの重大な誤作動に直結するため、フェイルセーフを意識した厳密なエラーハンドリングが必須だ。
AIの出力をフィルタリングするより、不正な入力ではAIを動かさない設計のほうが根本的な対策になる。
「使える」と「信頼できる」は別の話だ
マルチモーダルAIの視覚理解能力は実用レベルに達している。それは事実だ。
ただし、「データが正しく渡っている」という前提の上でのみ。
画像なし状態で60〜100%の確率で「見えたふり」をするモデルを、入力検証なしでシステムに組み込むのはリスクが高い。
高性能なモデルほど、もっともらしい誤情報を生成する能力も高い。
システム側での入力検証。これが今できる最も確実な対策だ。
マルチモーダルAIの強力な機能と「見えたふりをする」落とし穴を理解したら、その知見をアウトプットしてほしい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
