
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
PDFを送ったら「ページが存在しない」と怒られた
MCPでPDFをアップロードしたのに、AIが「ページが存在しない」と返してくる。
ファイルは確かに存在する。数百KBのPDFだ。なのに INVALID_ARGUMENT: 400。
これ、バグじゃない。MCPの仕様上、避けられない破損だ。
原因はプロトコルレベルにある。LLMエージェントを実用レベルで動かすには、「指示の経路」と「データの経路」を分けて設計する。その話をする。
MCPでファイルが壊れる仕組みと、業界が向かうアーキテクチャ
何が起きているかから整理する。
MCPは本質的にJSON-RPCのプロトコルだ。テキストのやり取りに特化している。
ツール呼び出しの結果として定義されているコンテンツ型は、テキスト・画像・音声などだ。PDFやバイナリファイルをそのまま転送するための「FileContent」や「BinaryContent」という型は仕様に存在しない。
じゃあどうするか。次善策として「Base64エンコードしてテキストとして渡す」という方法がある。
実際、Claude DesktopはPDFを添付されると自動的にこの手段を試みる。
問題はここからだ。
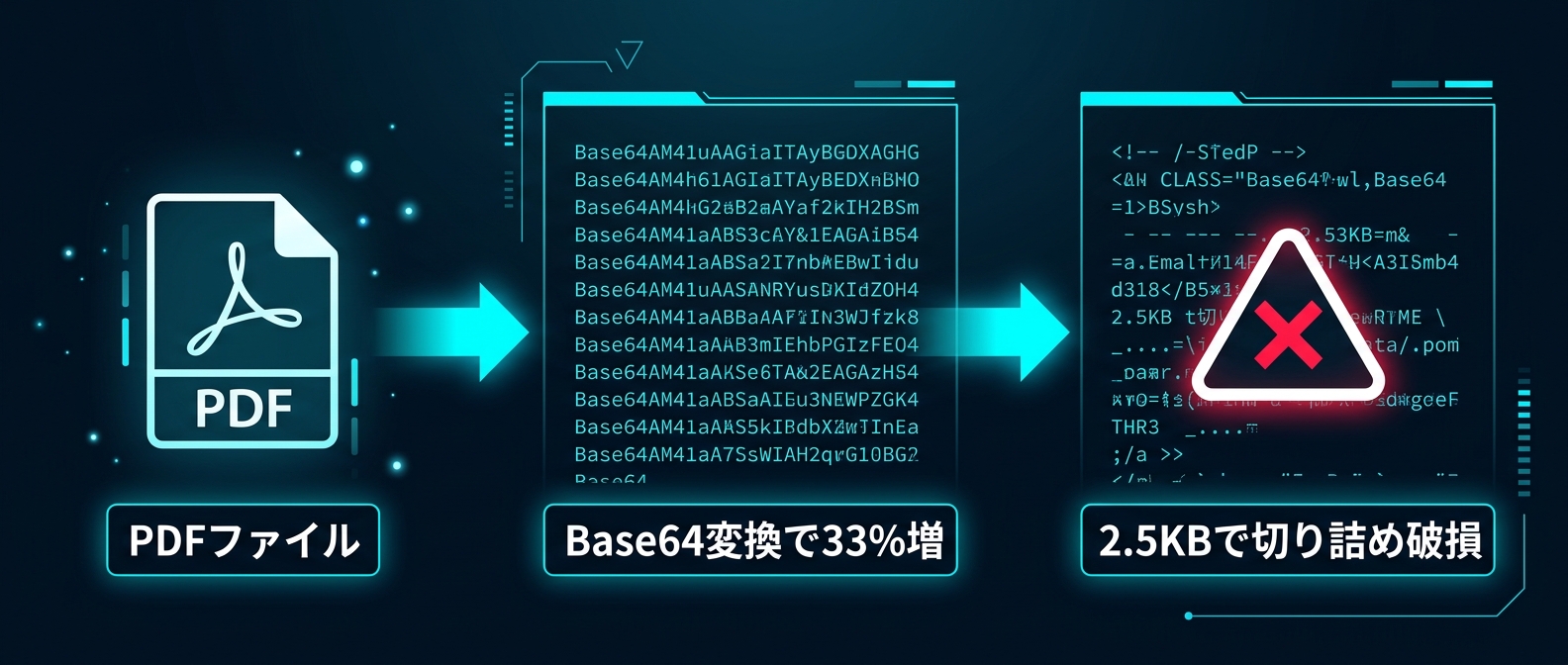
Base64エンコードすると、データ量が約33%増加する。88KBのPDFなら、エンコード後は約117KB相当のテキストになる。
これがLLMのコンテキストウィンドウに突っ込まれる。
約2.5KB前後でペイロードが切り詰められるケースが実際に確認されている。88KBのPDFが2.5KBで切られたら、残りの約115KBが消える。
切り詰められたBase64文字列をデコードすると何が起きるか。PDFの終端マーカー(EOF)と相互参照テーブル(xref)が欠落する。
PDFパーサーはこれを「ページが存在しない壊れたドキュメント」として扱う。だから「The document has no pages」というエラーが返ってくる。
問題は、サーバー側でこの切り詰めを検知できないことだ。Base64の文字列として受け取った時点では、それが完全なデータなのか途中で切られたデータなのか判別できない。
エラーはAI処理の段階になって初めて発覚する。
なぜMCPはバイナリ転送を仕様から外したのか。理由はセキュリティだ。
大容量データによるDoS的な攻撃リスクと、未知のバイナリファイルを実行されるリスクを抑えるため、意図的に除外されている。設計上の判断であって、バグではない。
一方、この課題に対してインフラ層から別のアプローチを取るプロジェクトも出てきた。
Agent-InfraのAIO Sandboxという概念だ。ブラウザ・シェル・ファイルシステムを単一のコンテナに統合した実行環境だ。
AIエージェント向けのオールインワンランタイムとして設計されている。
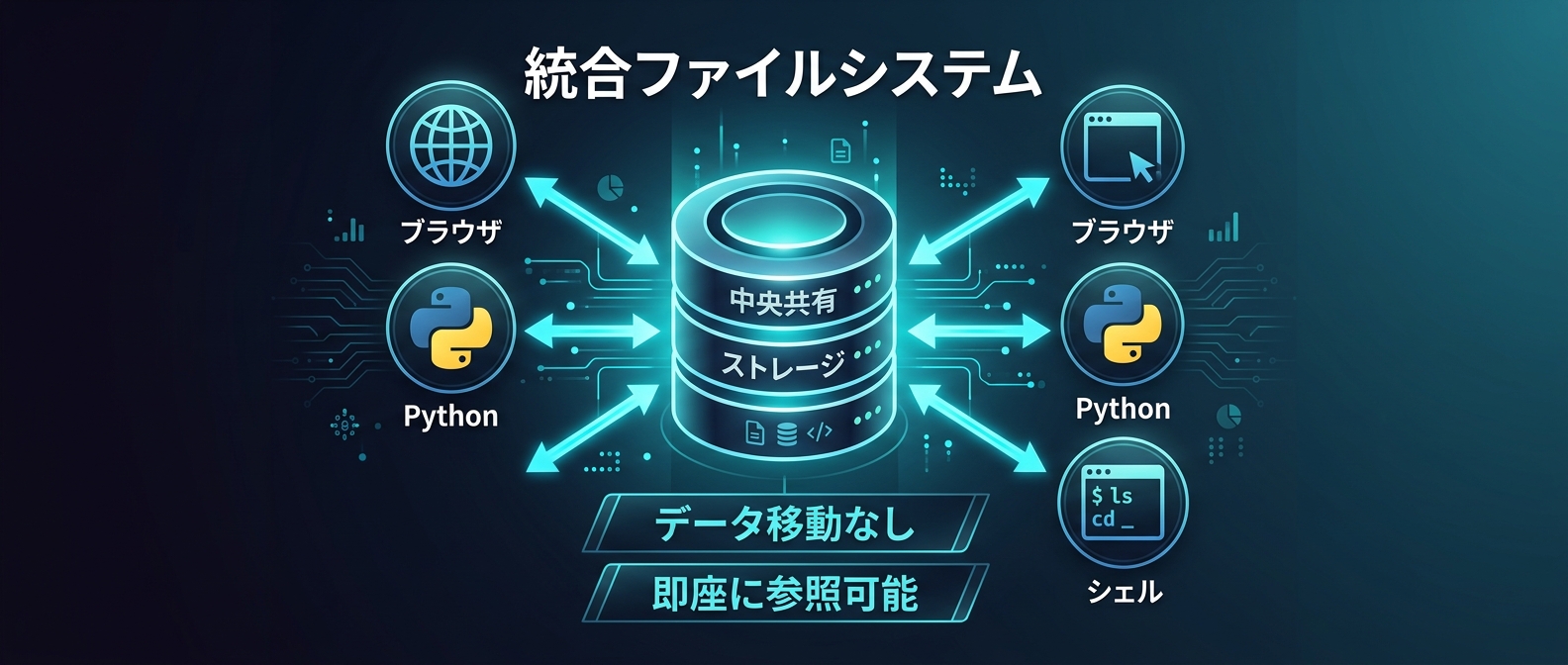
核心は「統合ファイルシステム」だ。通常のエージェント開発では、ブラウザでダウンロードしたファイルを別環境のPythonインタープリタで処理しようとすると、ファイルを「移動」する処理が発生する。
レイテンシが増え、実装が複雑になる。
AIO Sandboxでは、ChromiumブラウザがダウンロードしたファイルがPythonインタープリタとBashシェルから即座に参照可能だ。共有ストレージレイヤーで全ツールが繋がっている。
CSVをWebからダウンロードして、そのままPythonでクリーニングスクリプトを走らせる。この処理が外部データハンドリングなしに実現できる。
MCPサーバーも内蔵されている。LLMからのツール呼び出しを標準プロトコルで受け付ける構造だ。
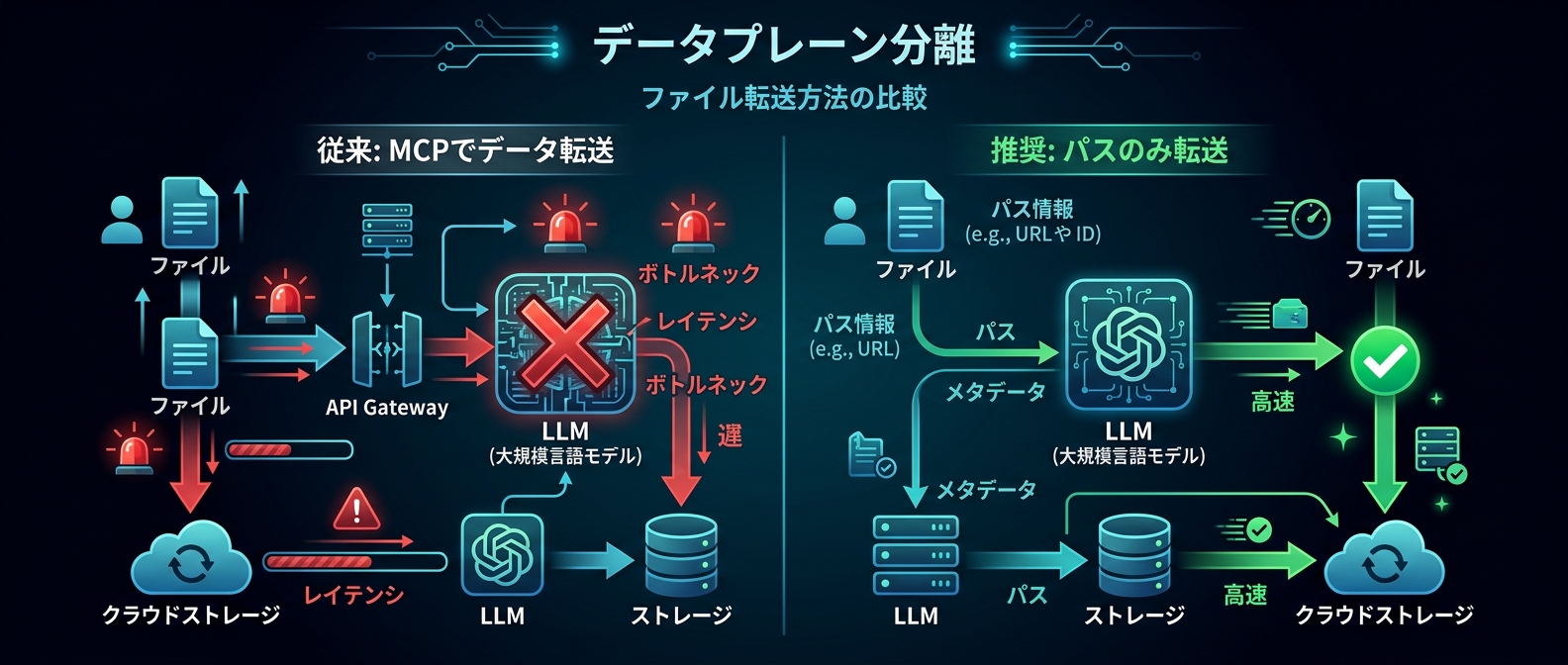
コントロールプレーン(LLMからの指示)とデータプレーン(実際のファイル共有・転送)を分離する。これが業界の向かうアーキテクチャだ。
しんたろー:
これ見て「あ、そういう設計の問題だったのか」ってなった。
MCPをデータ転送に使おうとしてたのが根本的に間違いで、MCPは「指示を渡す経路」であって「データを運ぶ経路」じゃない。
Claude Codeで作業してると、大きいファイルはパスを渡して直接読ませてるんだけど、あれが正解だったわけだ。
偉そうに語ってるけど、昨日までBase64でゴリ押しできると思ってた。
開発者目線で見ると、これは「ツールの使い方」じゃなく「設計の問題」
MCPの制限を知らずにエージェントを組むと、本番環境で静かに壊れ続ける。
これが厄介な理由は3つある。
- エラーがサイレントに発生する。サーバー側のツール定義はBase64文字列を受け取るだけなので、切り詰められていても気づけない。
AIの処理段階になって初めて発覚する。
- 再現性が低い。ファイルサイズやペイロードの状況によって切り詰められるタイミングが変わる。
「たまに壊れる」という挙動になりやすい。
- ユーザーが原因を特定できない。「PDFをアップロードしたのに処理されない」という体験になる。
エラーメッセージも「ページが存在しない」で、ファイル転送の問題だとは気づかない。
Claude Codeのようなローカルエージェントツールで作業する場合、この問題は別の形で現れる。大容量ファイルをMCP経由でコンテキストに押し込もうとすると同じことが起きる。
正しいのは「ファイルパスを渡して直接読ませる」設計だ。
ファイルの中身をLLMに送るのではなく、「このパスにあるファイルを読め」という指示だけを送る。実際の読み込みはローカルファイルシステムへの直接アクセスで行う。
コントロールプレーンとデータプレーンの分離、そのものだ。
エージェント開発の難しさが「モデルの推論」から「実行環境のインフラ」にシフトしている。この話はAIO Sandboxのコンセプトにも表れている。
ブラウザ・シェル・ファイルシステムを統合する理由は、「ツール間のデータ移動」というインフラの問題を解消するためだ。
ツール呼び出し(Function Calling)の仕組み自体は、本質的にはシンプルだ。LLMは「どの関数をどんな引数で呼ぶか」をテキストで出力するだけだ。
実際の実行はローカルコードが担う。LLM自身はインターネットにも、ファイルシステムにも繋がっていない。
この「LLMは判断だけ、実行は外部」という構造を理解していないと、MCPに何でも渡そうとしてしまう。
モデルに渡すものは「指示」と「結果のサマリー」だけだ。生のバイナリデータをコンテキストに乗せようとした時点で、設計の方向性が間違っている。
ThreadPostの構成を考える上でも、画像や添付ファイルの処理は「パスを渡す」か「別APIで処理してIDだけ返す」設計が気になっている。
LLMのコンテキストにバイナリを乗せようとした瞬間、設計が詰む。
AIO Sandboxの「統合ファイルシステム」という発想、これはかなり理にかなっている。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務で直面する前に知っておくこと
アーキテクチャの判断点を整理する。
MCPを使ったファイル処理の設計チェック
- ファイルをBase64でMCPに渡していないか
- ペイロードが2.5KB制限に引っかかる可能性のあるファイルサイズを扱っていないか
- エラーがサーバー側でサイレントになっていないか(ログに「ページが存在しない」「INVALID_ARGUMENT」が出ていないか)
実務的な回避策
- HTTPエンドポイントを別途立てる。MCPとは別にExpressなどでファイルアップロード用のエンドポイントを用意し、ファイルはそちらに直接POSTする。
MCPには「ファイルをこのURLにアップロードせよ」という指示だけを渡す。
- 保存先のパスまたはURLだけをMCP経由でLLMに渡す。ファイルの中身ではなく、ファイルの「場所」を渡す設計にする。
- ローカルエージェントの場合はファイルパスを直接渡す。Claude Codeで作業する場合、大容量ファイルはパスを指定して直接読み書きさせる。
エージェントの実行環境設計で考えること
- ツールをまたいでデータを移動させる処理が発生していないか
- ブラウザ・シェル・Pythonインタープリタが別々のコンテナに分かれていると、ファイル移動のオーバーヘッドが積み重なる。
- AIO Sandboxのような統合ランタイムのコンセプトは、このオーバーヘッドを解消するためのアプローチだ。
コスト面での選択
開発中のツール呼び出しのテストやプロンプト検証には、Claude 3.5 Haiku(またはHaiku 4.5)が現実的だ。Sonnet 4.6と比べて約3分の1のコストで動作する。
定型的なツール呼び出しのルーティング検証であれば、軽量モデルで十分な精度が出る。本番移行時に model の文字列を変えるだけでいい。
設計の優先順位
まず「コントロールプレーンとデータプレーンの分離」を意識する。MCPはLLMへの指示経路として使い、ファイルの実体は別の経路で扱う。
この分離を最初から設計に組み込むかどうかで、後から直す工数が大きく変わる。
「MCPでなんでも渡せる」という思い込みで設計を進めると、本番でサイレントに壊れ続ける地雷を埋めることになる。
HTTPエンドポイント追加のワークアラウンドは確かに動くけど、長期的にはインフラ層でデータプレーンを統合するほうがきれいだ。
うちの構成でも、ファイル処理の経路は早めに整理しておきたい。
よくある質問
Q1. MCPを使ってPDFや画像をLLMに送るにはどうすればいいですか?
MCPプロトコル自体にはバイナリ転送の仕様がない。Base64エンコードしてテキストとして送る方法はあるが、データ量が約33%増加する。
約2.5KB前後でコンテキストが切り詰められてファイルが破損するリスクが高い。
実務での推奨設計は、MCPとは別にHTTPサーバー(Expressなど)を立ててファイルをアップロードするアーキテクチャだ。保存先のファイルパスやURLだけをMCP経由でLLMに渡す。
ファイルの中身ではなく「場所」だけをLLMに知らせる。これにより安定したファイル処理が可能になる。
ローカルエージェントの場合はファイルパスを直接渡して直接読み書きさせる設計が基本だ。
Q2. エージェントがダウンロードしたファイルを別のツールで処理させる際のベストプラクティスは?
ツールごとにコンテナや環境が分かれている構成では、「ブラウザでダウンロード→別環境に転送してPythonで処理」という流れでデータ移動が発生する。レイテンシの増加と実装の複雑化が積み重なる。
解決策は実行環境レベルでストレージを共有することだ。AIO Sandboxのような統合ランタイムを使うと、ブラウザ・Pythonインタープリタ・Bashシェルが同一のファイルシステムを共有する。
ブラウザでダウンロードしたCSVをそのままPythonで処理できる。外部データハンドリングのオーバーヘッドがゼロになる。
インフラ側でデータプレーンを統合するのが鍵だ。
Q3. ツール呼び出し(Function Calling)のテストを安価に行う方法はありますか?
Claude 3.5 Haiku(またはHaiku 4.5)を使うのが現実的だ。Sonnet 4.6と比較して約3分の1のコストで動作する。
LLMのツール呼び出し機能は本質的に「どの関数をどんな引数で呼ぶべきか」をテキストで出力するだけの機能だ。実際の実行はローカルコードが担う。
複雑な推論を必要としない定型的なツール呼び出しのルーティングや、プロンプトの動作検証フェーズであれば、軽量モデルでも十分な精度が出る。
本番環境やより高い精度が必要な場面では、model の文字列を変えるだけでSonnet 4.6やOpus 4.6に切り替えられる。開発中のトライ&エラーはHaikuで回すのが合理的だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、
海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
MCPは「指示の経路」であって「データの経路」じゃなかった
それだけの話だった。でもこれを知らずに設計すると、本番で静かに壊れ続ける。
エージェント開発の主戦場が「モデルの精度」から「実行環境のインフラ設計」に移っている。コントロールプレーンとデータプレーンを分離する。
これが今の実用的なエージェント開発の前提になりつつある。
AIエージェントのインフラ設計や、こういう実務で詰まるポイントを日々発信している。ThreadPostで拾ってもらえると嬉しい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
