
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AI開発の主戦場が「モデルの賢さ」から「インフラの最適化」へ。
AI開発のフェーズが、完全に変わった。
これまでは「どのモデルが賢いか」というベンチマーク競争に一喜一憂していた。
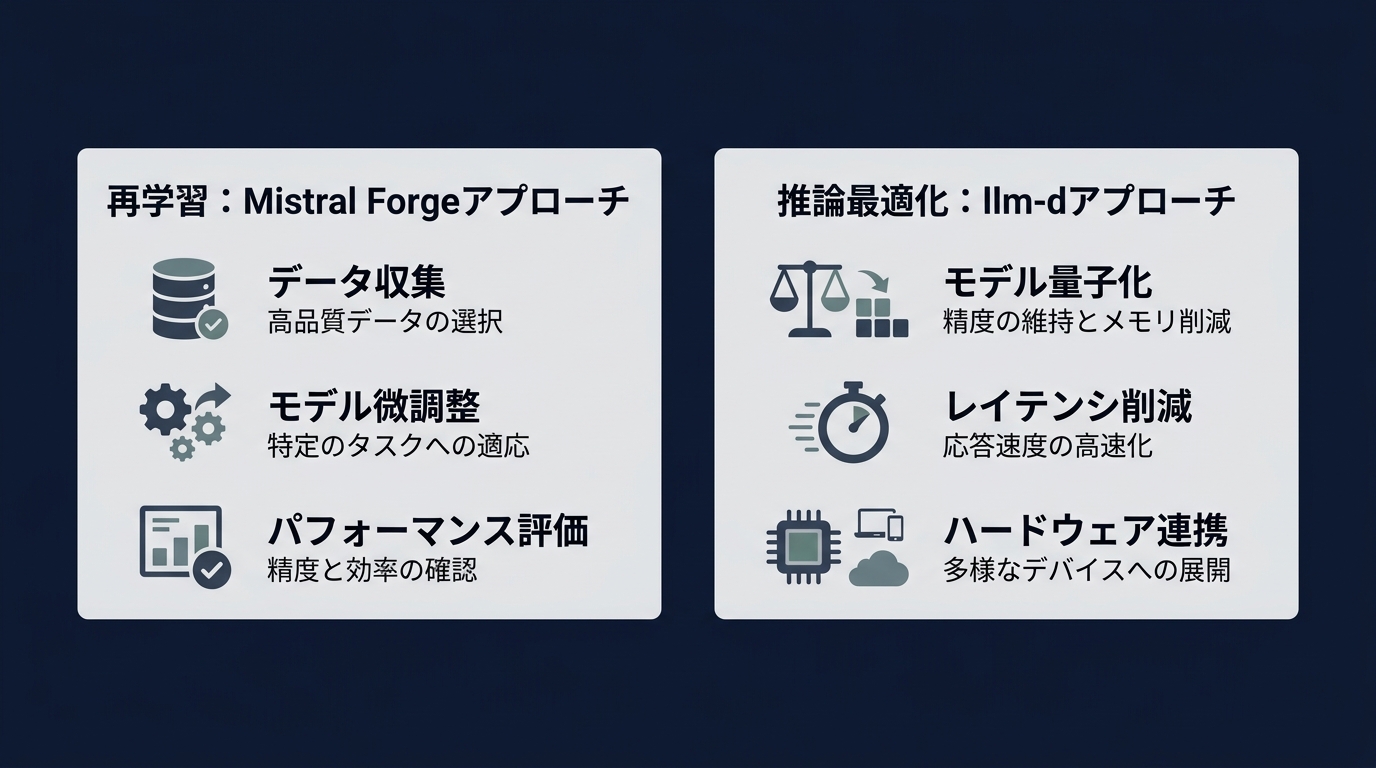
10億ドル規模の年間収益を見込むMistral AIは、自社データでモデルをゼロから再学習させるプラットフォーム「Mistral Forge」を立ち上げた。
コンテナ管理システム上での推論効率を最大化する分散フレームワークも登場している。
VRAMの制約、メモリ配置、そして推論インフラの設計。
これらを理解しているかどうかが、プロダクトの成否を分ける。
僕が愛用しているClaude Codeのようなツールが、今後この複雑なインフラ層をどうハックしていくのか。
その最前線を、開発者目線で深掘りする。
汎用モデルの限界と「自社専用モデル」への回帰
「インターネットのデータで学習した汎用モデル」では、企業の深いドメイン知識に対応できない。
モデルが、その会社の内部ワークフローや専門用語を理解していないケースが散見される。
Mistral Forgeは、企業独自のデータを使ってモデルを再学習(リトレーニング)させるためのプラットフォームだ。
これまでの主流は、既存のモデルに外部知識を組み合わせるRAG(検索拡張生成)や、特定のタスクに特化させる微調整だった。
新しいプラットフォームでは、モデルをゼロから、あるいは深い階層から再学習させることを可能にする。
これにより、非英語圏の言語や、極めて専門性の高い業界データに対しても、モデルが「ネイティブ」に対応する。
モデルの重み自体を書き換えることで、推論時のコストを抑えつつ、精度を向上させる狙いがある。
特に注目すべきは、小型モデルの活用だ。
巨大なモデルを汎用的に使うのではなく、特定のタスクに最適化した軽量なモデルを自社で育てる。
これが、今後のエンタープライズAIのスタンダードになる。
開発者は、どのモデルを使うかだけでなく、「どう育てるか」という視点を持つ。
しんたろー:
RAGでプロンプトを太らせるのにも限界がある。トークン代は嵩むし、コンテキストが長くなればなるほど精度も不安定になる。自社データでモデルを叩き直せるプラットフォームが一般化すれば、僕ら開発者の仕事は「プロンプトエンジニアリング」から「データパイプライン設計」にシフトしていくはずだ。
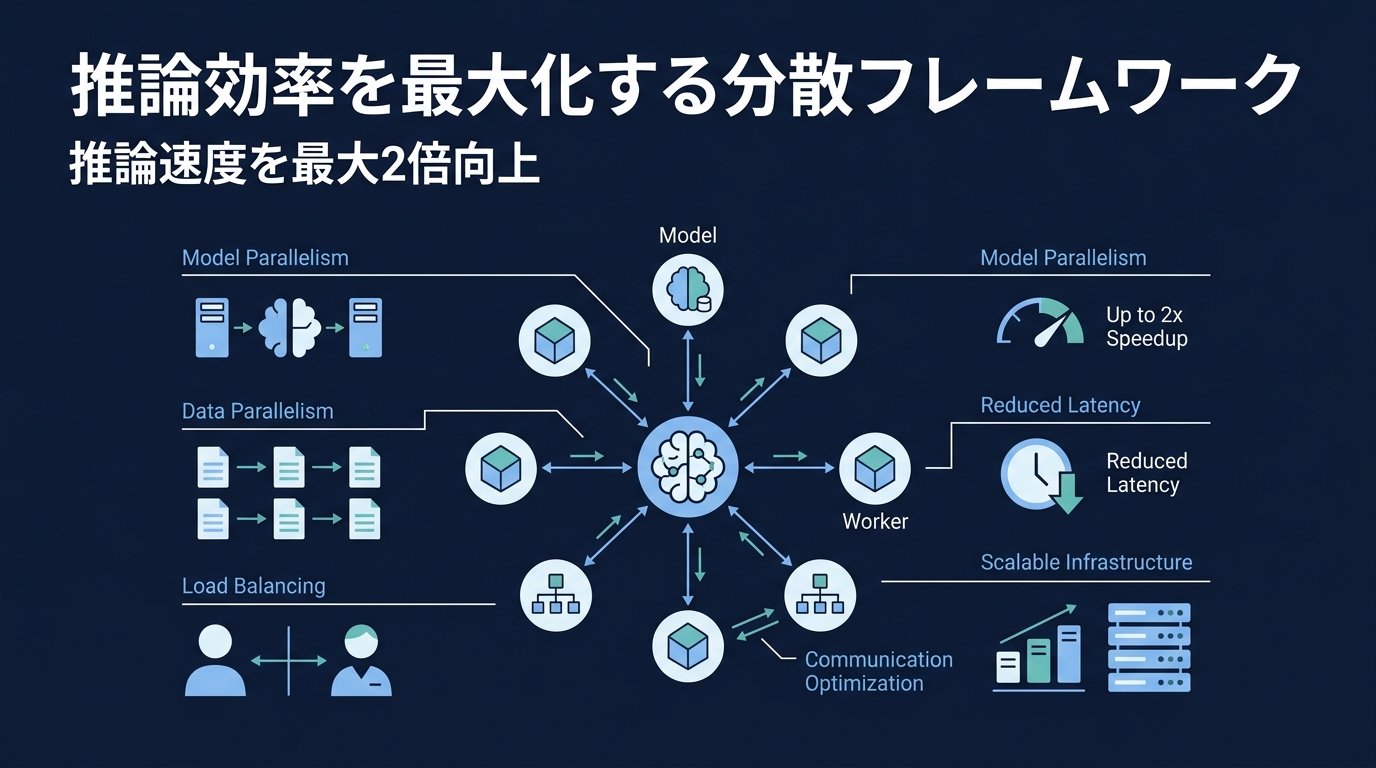
インフラ層の革命。LLM推論を最適化する分散フレームワーク
「どう動かすか」というインフラ層でも大きな動きがある。
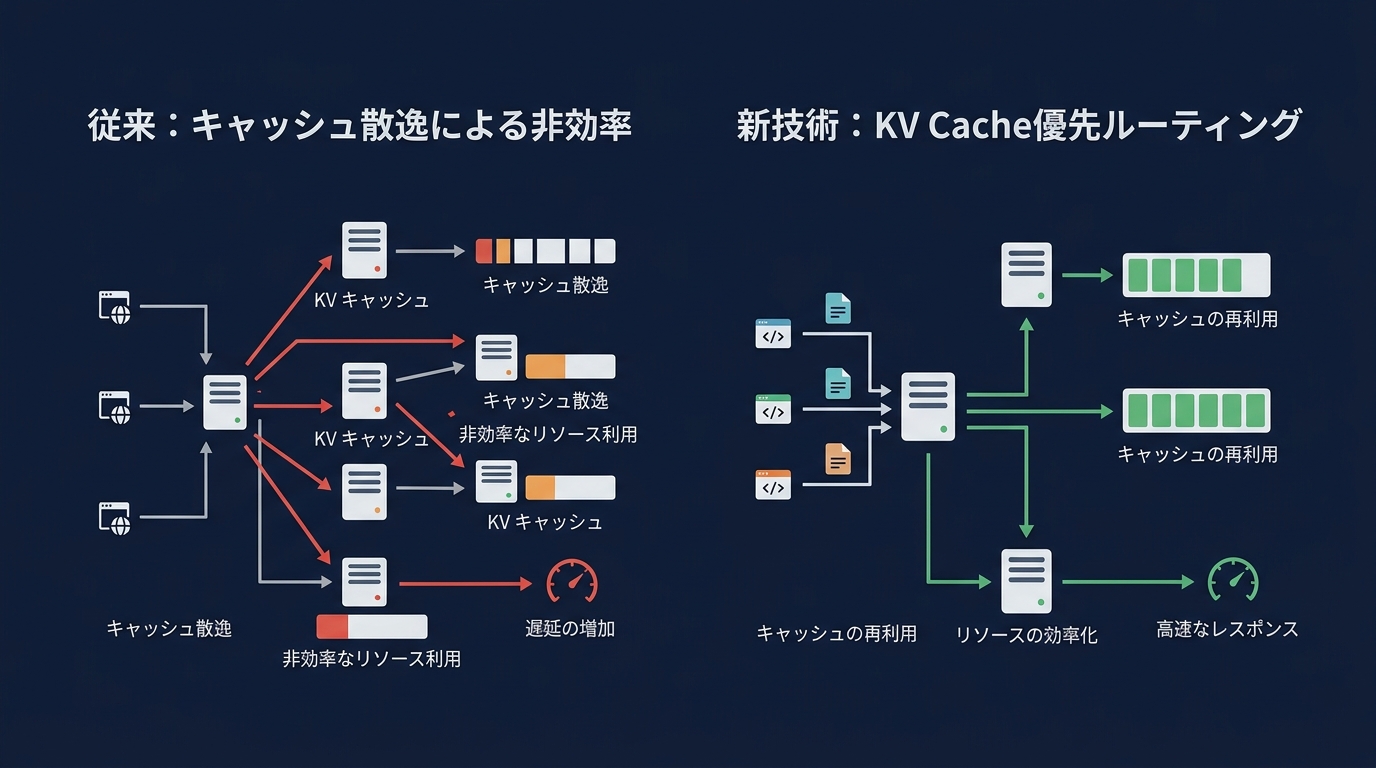
現在、多くの開発者が直面しているのが、Kubernetes(K8s)上でのLLM推論の非効率さだ。
推論プロセスではKV Cache(Key-Value Cache)と呼ばれる中間データが生成され、これがGPUメモリ(VRAM)に保持される。
同じ会話の続きを別のコンテナに送ってしまうと、このキャッシュが使えず、計算をゼロからやり直すことになる。
この課題を解決するために登場したのが、LLM推論に特化したインテリジェントなルーティングを実現するフレームワークだ。
このフレームワークは、リクエストの内容を解析し、特定のキャッシュを持っているコンテナへ優先的に割り振る。
これにより、計算リソースの無駄を省き、推論速度を最大で2倍近く向上させる。
さらに、最新の強力なモデルの多くが採用しているMoE(Mixture-of-Experts)アーキテクチャへの対応も進んでいる。
これを複数のノードに分散配置し、高速に通信させる技術が、今後のインフラ設計の核となる。
K8sでGPUを回していると、この「キャッシュの散逸」は頭が痛い問題だった。インフラ側で賢くルーティングしてくれるようになれば、アプリケーション側で無理な最適化をしなくて済む。結局、AI開発も最後は「いかにハードウェアの制約をソフトウェアで隠蔽するか」という伝統的なインフラの戦いに戻ってきた感じがする。
なぜClaude Codeがこのインフラ複雑化を救うのか
僕が推しているClaude Codeは、ターミナル上で動作し、ファイル操作やコマンド実行を自律的に行うエージェントツールだ。
これからのAI開発では、先ほど述べたような複雑な分散インフラの設定や、再学習のためのデータパイプライン構築が必須になる。
YAMLファイルの山を書き換え、ネットワーク設定を調整し、GPUのメモリ配置を最適化する。
Claude Codeのようなエージェントは、こうした「インフラの構築と管理」において真価を発揮する。
例えば、分散推論フレームワークの設定ファイルを、現在のクラスタ構成に合わせて自動生成させる。
あるいは、モデルの再学習に必要なログ収集スクリプトを、既存のコードベースを理解した上で書き上げさせる。
「コードを書く」ことと「インフラを整える」ことの境界線が、AIエージェントによって溶けていく。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
VRAMの壁とユニファイドメモリが変える未来
AI開発における最大の物理的制約は、間違いなくVRAM(GPUメモリ)だ。
モデルの重みがVRAMを占有し、さらに推論時のキャッシュが動的に増え続ける。
このメモリ不足をどう回避するかが、現在のインフラ技術のほとんどを占めている。
しかし、この前提自体が覆されようとしている。
それが、ユニファイドメモリアーキテクチャの台頭だ。
CPUとGPUが同じメモリ空間を共有すれば、データの転送コストは下がる。
最近では、128GB以上のユニファイドメモリを搭載した小型PCも登場しており、ローカル環境での大規模モデル推論が現実味を帯びてきた。
もしこのアーキテクチャがサーバーグレードでも一般化すれば、現在苦労している「VRAMの壁を迂回するための複雑な仕組み」の多くは不要になる。
メモリ上のデータをどこからでも同じ速度で参照できる世界。
そこでは、LLM推論は「ただのメモリ消費が激しいアプリケーション」へと変わる。
VRAMを増やすために数十万円のGPUを買い足す日々が、いつか「昔は大変だったね」と思い出話になるかもしれない。ユニファイドメモリが当たり前になれば、分散コンピューティングの考え方そのものが変わる。その時、僕らの開発スタイルも、もっと自由で軽量なものになっているはずだ。
開発者が今すぐ意識すべきアクションアイテム
この激動の状況下で、以下の3つの視点を持つ。
第一に、RAGの限界を見極めることだ。
精度が出ない、あるいはコストが見合わないと感じたら、「小型モデルの再学習」という選択肢を検討する。
第二に、推論インフラの仕組みを理解することだ。
KV CacheやMoEの並列化といった用語を、「自分のシステムでどう動いているか」というレベルで把握する。
第三に、AIエージェントをインフラ操作に組み込むことだ。
Claude Codeを使って、デプロイ設定の自動化や、負荷試験のスクリプト生成を試す。
「AIにコードを書かせる」段階から、「AIにシステム全体を管理させる」段階へ、スキルをアップデートする。
AI活用に関するFAQ
Q1: RAGと再学習、どちらを選ぶべきか?
A1: まずはRAGから始めるのが正解だ。実装コストが低く、情報の更新も容易だからだ。しかし、特定の専門用語への適応が不十分だったり、推論時のコンテキストコストがビジネスを圧迫し始めたりした場合は、再学習(リトレーニング)を検討する。独自言語や特殊なフォーマットをモデルに叩き込みたい場合は、再学習の方が最終的な精度とコストパフォーマンスで勝る。
Q2: 分散推論フレームワークは、小規模なチームでも導入すべきか?
A2: 現時点では、リクエスト数が少ないうちはマネージドなAPIを利用するのが最も効率的だ。分散推論フレームワークが必要になるのは、自前でGPUサーバーを運用し、かつレイテンシがサービスの収益に直結するフェーズになってからだ。ただし、将来的なスケーリングを見越して、KV Cacheの概念やMoEの挙動については知識として持っておく。
Q3: Claude Codeをインフラ構築に使う際の注意点は?
A3: 破壊的なコマンドを自律的に実行するリスクがある。特に本番環境に近い操作をさせる場合は、必ず実行前にプランを確認し、ステップバイステップで進める。また、Claude Codeにインフラを操作させるなら、Infrastructure as Code(IaC)を徹底する。コードとして管理されていれば、AIが何を変更したかを人間が正確に追跡できる。
まとめ
AI開発の重心は、モデルからインフラ、そしてドメイン特化へと移っている。
10億ドルの収益を目指す企業が再学習に舵を切り、推論効率を2倍にするインフラ技術が標準になりつつある。
VRAMの制約と戦い、メモリ空間をハックし、AIエージェントと共にシステムを組み上げる。
そんな「泥臭い」開発こそが、これからのAI時代に最も価値を持つ。
僕もClaude Codeを相棒に、この複雑な世界を1つずつ紐解いていく。
最新のAIインフラ知見を武器に、次世代のプロダクトを共に作っていこう。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
