
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
突然AIがポンコツになる理由
エージェント開発における最大の絶望。
それは、外部ツールを繋いだ瞬間にAIが直前の指示を完全に忘却することだ。
理由は極めて単純だ。
ツールの出力結果が長すぎる。
5000行の検索ログが返ってきた瞬間、AIのコンテキストは崩壊する。
膨れ上がるAPIコスト。堂々巡りのエラー修正ループ。
AIにツールを使わせるなら、入力の工夫だけでは全く足りない。
出力の保護層がないエージェントは、ただの金食い虫に成り下がる。
ツール連携の光と影
海外開発者コミュニティで、ある共通の課題が熱を帯びて議論されている。
「AIエージェントのツール連携におけるコンテキスト管理」の難しさだ。
Gemma 3のような強力なオープンモデルがある。
公式には関数呼び出し機能を持っていないとされることが多い。
だが、チャットテンプレートを書き換え、XML形式のタグでプロンプトを工夫すれば動かすことは可能だ。
27Bクラスのパラメータ数と推論能力があれば、擬似的なツール呼び出しは十分に成立する。
ここまでは「どうやってAIにツールを使わせるか」という入力側の話だ。
本当の地獄はその先に待っている。
ツールが実行された後、予測不能な大量のデータがシステムに返ってくる。
ファイルの検索結果。外部APIのレスポンス。数千行に及ぶビルドエラーのログ。
これを何のフィルターもかけずに、そのままLLMに返すとどうなるか。
コンテキストウィンドウの完全な崩壊が起きる。
AIは直近に入力された大量のデータに意識を奪われる。
ユーザーが最初に「このバグを修正して」と出した指示を、きれいさっぱり忘れてしまう。
無関係なファイルの編集を始めたり、同じエラーを何度も繰り返したりする。
さらに恐ろしいのは、クラウドAPIを利用している場合のコストだ。
巨大なログがコンテキストに残り続け、毎ターンの会話でその巨大なデータが入力トークンとして延々と課金され続ける。
1回の検索ミスが、トークン消費量を一気に10倍に跳ね上げる。
複数の開発者コミュニティの知見を統合すると、ひとつの構図が浮かび上がる。
ある者はプロンプトの力技でモデルの限界を突破しようとする。
またある者は、システムアーキテクチャのレベルで出力を制御しようとする。
エージェントの実用性は、ツールを呼び出す能力だけで決まらない。
ツールが吐き出した暴力をいかに制御し、安全にLLMに返すかで決まる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
エージェントを壊す「コンテキスト破綻」の正体
なぜAIはあっさりと指示を忘れるのか。
LLMには、直近に入力された情報に強く引きずられるという明確な傾向がある。
エージェントに「ディレクトリ内のTODOコメントを検索して」と指示したとする。
ツールが実行され、2000行の検索結果がドバッと返ってくる。
AIの視界は、その2000行のTODOリストで完全に埋め尽くされる。
本来の目的だった「システムのバグ修正」という大前提のコンテキストは彼方に消え去る。
ローカル環境で推論エンジンを回しているなら、メモリ不足でシステムがクラッシュする。
クラウド環境なら、一瞬で莫大な請求が発生する。
解決策は、システムアーキテクチャレベルでの保護機構の導入にある。
ツールの実行関数を、そのまま直接LLMに繋いではいけない。
間に必ず、出力を監視する「ラッパー」を挟む。
出力の行数やバイト数を常に監視する仕組みだ。
上限を2000行、または50KBといった閾値に設定する。
これを超えた場合、システムは自動的に出力を切り詰める。
切り捨てた生の巨大なデータは、一時ファイルとしてローカルディレクトリに保存する。
そして、LLMには切り詰めた一部の結果とともに、自然言語の「ヒント」を返す。
「出力が長すぎたため切り詰めました。全文は指定のファイルパスに保存されています」と。
AIは「情報が足りないなら、次はファイル読み込みツールを使って必要な部分だけを読めばいい」と自己解決する。
コンテキストの崩壊を防ぎつつ、次の自律的なアクションを安全に促せる。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、このログの暴力は本当に心臓に悪い。
うっかり巨大なビルドエラーをそのまま食わせると、一瞬でトークンが吹き飛んで冷や汗が出る。
エージェントは賢いけど、与えられた餌は全部食べようとするから、飼い主側で食事制限しないと即死するんだよね。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
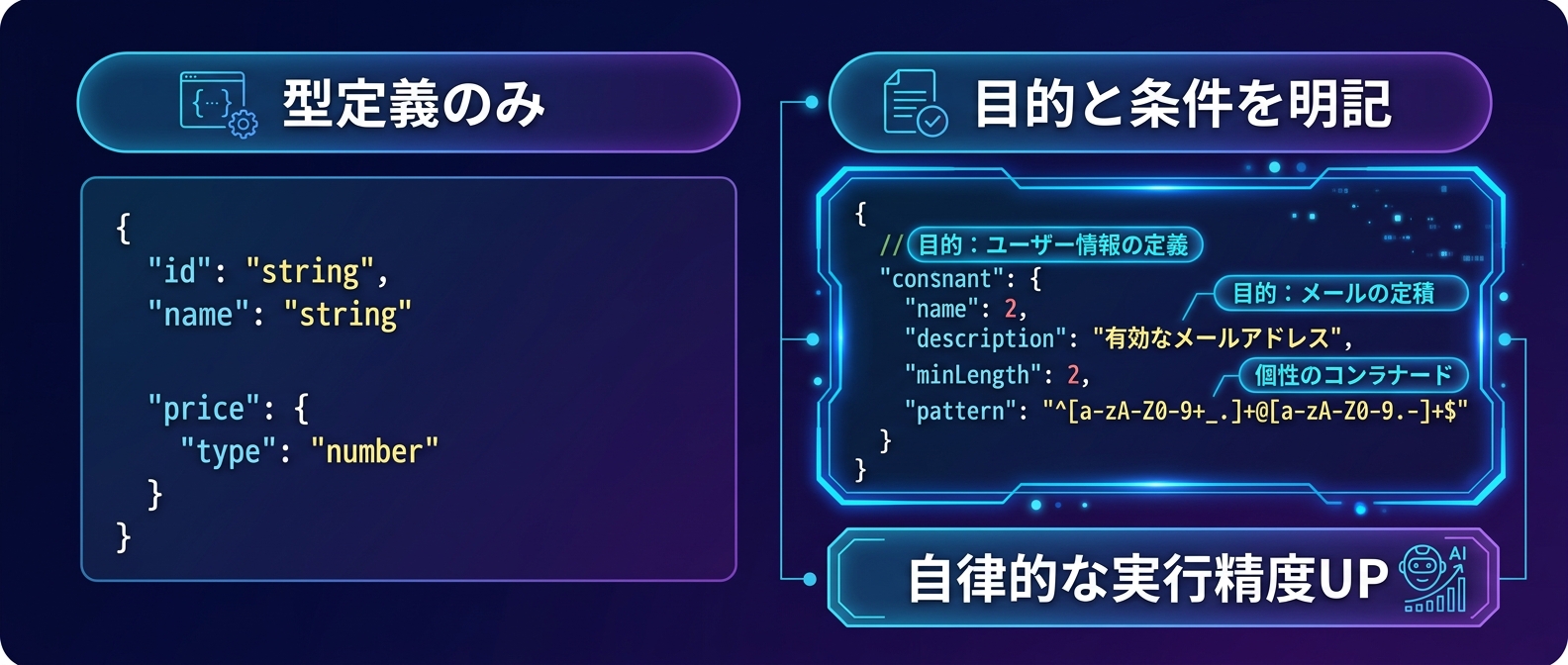
モデルに「空気」を読ませるスキーマ設計
出力の制御と同じくらい、入力側の設計も効いてくる。
ツール定義、つまりJSONスキーマの書き方ひとつでAIの挙動は激変する。
多くの開発者は、引数の型定義だけを書いて満足してしまう。
「緯度」は数値データ。「経度」も数値データ。
これだけでは、AIは「いつ」「なんのために」そのツールを使えばいいのか全く分からない。
ツールの説明欄に自然言語でメタ指示を書き込む。
「天気に関する質問に答える前に、必ずこのツールを呼び出すこと」
このように、行動のトリガーを明確に言語化して叩き込む。
AIに空気を読ませようと期待してはいけない。
使うべきタイミングを、システムプロンプトのレベルで強制する。
AIがツールを使うタイミングを迷わなくなり、自律的な実行精度は数段上がる。
入力側の「明確なトリガー定義」と、出力側の「安全な切り詰め機構」。
この両輪が揃って初めて、AIは迷わず、かつ壊れずに動き続けることができる。
片方だけでは、すぐにセッションが破綻する。
昔、APIの仕様書をそのままコピペしてツール定義にしてたけど、全然意図通りに動かなくて絶望した。
LLMには「型」じゃなくて「目的」を伝えないとダメなんだと気づいた時のアハ体験は異常。
人間に仕事頼む時と同じで、「これ何に使うの?」が分からない道具は誰も使ってくれない。
僕らの開発にどう影響するのか
AIエージェントや、LLMを組み込んだ自動化システムを作るなら、防御的プログラミングの徹底が前提になる。
外部APIのレスポンスを、そのまま無加工でLLMに渡す設計は今すぐ見直したほうがいい。
どんなに優秀なプロンプトを書いても、予測不能なデータ長の前では無力だ。
システムは常に最悪の出力を想定して組む。
すべてのツール呼び出し処理に、インターセプターやラッパー関数を実装する。
文字数制限を設け、超過時は要約するか、バッサリと切り捨てる。
エラー発生時のハンドリングも同様だ。
長大なスタックトレースをそのまま返せば、AIはパニックを起こすか、トークンを無駄遣いする。
「エラーの最初の5行と最後の5行だけを抽出して返す」といった泥臭い工夫がいる。
僕のThreadPost開発でも、この視点は非常に重要だ。
外部のSNSプラットフォームから取得するデータは、時に予測不可能なサイズになる。
それを安全に処理し、AIのコンテキストを常にクリーンに保つ必要がある。
エージェントの安定稼働は、LLM自体の頭の良さで決まらない。
周りを囲むシステムの堅牢性と、いかにAIを守るかで決まる。
AIに渡すデータは、徹底的に疑って制限をかける。
ThreadPostの裏側で動かすAI連携を考える時も、この「出力の保護層」は絶対サボれないポイント。
APIのレスポンスが想定外にデカくてAIが沈黙するパターン、テスト環境で何度も踏み抜くんだよね。
ツール連携は、繋ぐことより「いかに安全に切るか」が腕の見せどころだと思う。

よくある質問
Q1: Function Calling非対応のローカルLLMでもツールを使わせることは可能ですか?
はい、可能だ。
推論エンジンを使用し、チャットテンプレートを上書きする力技が存在する。
XML形式のタグなどを用いて、ツール定義と呼び出しフォーマットをプロンプトとして強制的に差し込む。
これで非対応モデルでも擬似的にFunction Callingを実現できる。
ただし、モデル自体にある程度の推論能力が求められる。
27Bクラスのパラメータ数があれば、実用的なレベルで安定して稼働する。
Q2: ツール定義を書く際のコツは何ですか?
単なる引数の型定義で終わらせないことだ。
説明フィールドに「いつ、どのような目的でこのツールを呼び出すべきか」を自然言語で明確に記述する。
「天気に関する質問に答える前に必ず呼び出すこと」のように、行動の条件を明示する。
これにより、LLMがツールを使用するタイミングを迷わなくなる。
結果として、自律的な実行精度が数段上がる。
Q3: ツール実行結果が長すぎてLLMのコンテキスト上限を超えてしまう場合はどうすればよいですか?
ツール実行のラッパー関数を作成し、自動で切り詰める処理を実装する。
出力の行数やバイト数が閾値を超えたら、強制的にカットする。
全文は一時ファイルに保存し、LLMには「切り詰めたこと」と「全文のファイルパス」をヒントとして返す。
コンテキスト破綻を防ぎつつ、LLMに次のアクションを促せる。
最後に
エージェント開発のキモは、賢いプロンプトよりも泥臭い文字数制限だったりする。
AIの暴走を防ぐ強固な安全装置を作って、快適な開発ライフを手に入れよう。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
