
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
RAGの精度限界は検索アルゴリズムのせいではない
RAGを作っても期待した精度が出ない。
多くの開発者がベクトル検索のアルゴリズムを弄り回している。
回答精度が40%で頭打ちになる原因はデータの取り込み方にある。
特にPDFの表データが鬼門だ。
ここで構造が壊れ、AIが幻覚を起こしている。
そこに、Markdown変換を捨てて空間配置をそのままLLMに読ませる新しいアプローチが登場した。
これを知らないと、RAG開発の前提を根本から間違えることになる。
RAGの精度低下を招くデータ抽出の罠
ある詳細な検証データが、RAG開発の現実を突きつけた。
620ページに及ぶ複雑な仕様書を使った精度検証だ。
概念的な質問に対しては100%の精度で回答できるシステムが、特定の項番を引くような質問になると精度が40%まで急落した。
原因はベクトル検索の限界ではない。
ドキュメント内の表データが正しく解析できていない。
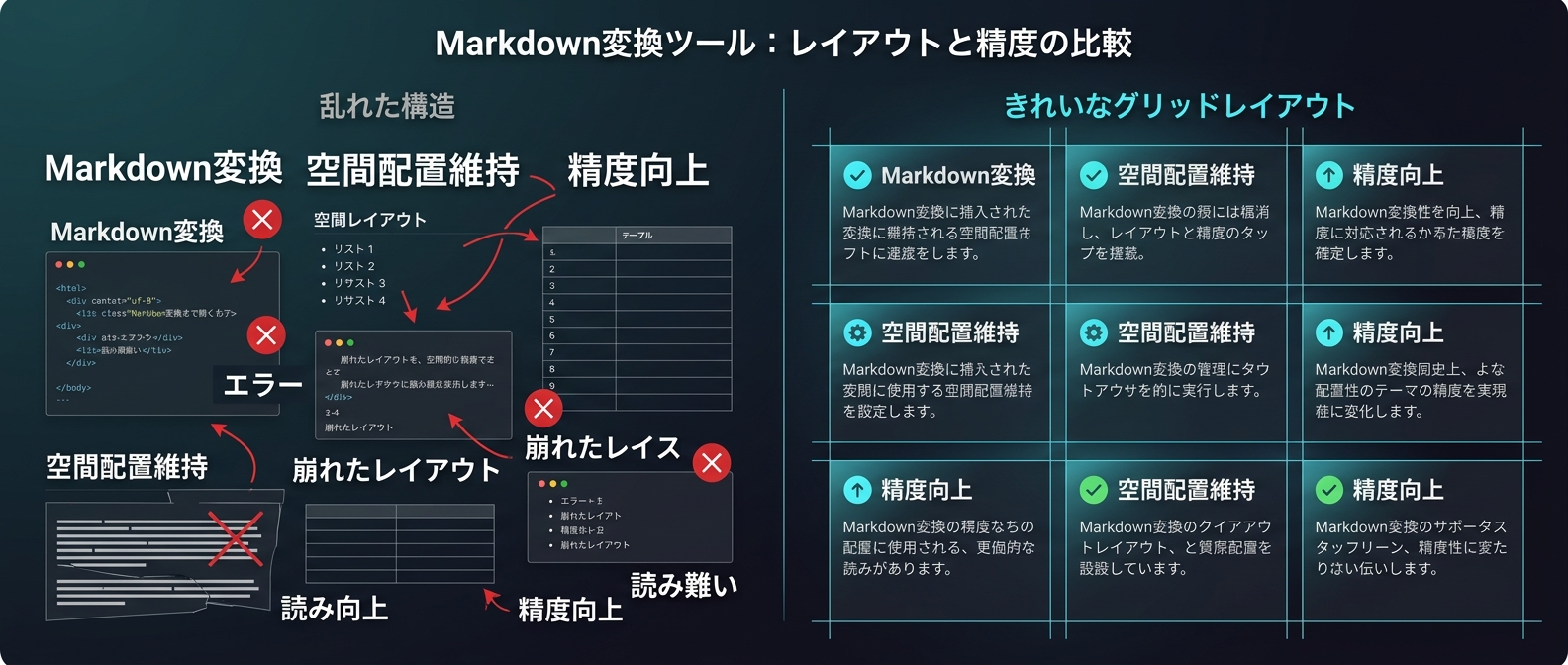
これまで開発者は、pymupdfなどを使ってPDFの表を懸命にMarkdown形式に変換してきた。
単純な表ならそれでいい。
だが、マルチカラムのレイアウトやネストされた複雑な表では、Markdown変換は無惨に破綻する。
行列の関係が崩れ、テキストが入り乱れる。
結果として、LLMは全く別の項目の数値を読み取ってしまう。
ここで全く新しいアプローチをとるドキュメント解析ライブラリLiteParseが登場した。
最大の特徴は、Markdown変換をあっさり諦めたことだ。
代わりに、テキストを空間グリッド上に投影する。
空白やインデントを使って、元のページレイアウトを維持したままテキストブロックとして抽出する。
これはTypeScriptネイティブで構築されている。
AI開発のツールといえばPythonが絶対的な標準だった。
しかし、この新しいパーサーはNode.js環境で完全にローカル動作する。
PDF.jsやTesseract.jsを利用し、重いPythonのOCRライブラリやクラウドAPIに依存しない。
Webページのデータ抽出でも同じ変化が起きている。
ただテキストをスクレイピングするだけでは、Cookieバナーやナビゲーションが大量のノイズになる。
ノイズが混ざると、検索精度が落ちるだけでなくトークンも無駄に消費する。
抽出の段階で意味のある構造を保ちつつノイズを削ぎ落とす。
これが現在のRAG開発における課題だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
空間配置の維持がRAG開発の前提を変える
RAGの精度を上げようとして、みんな検索手法ばかりを複雑にしている。
ハイブリッド検索だ、エージェントRAGだ、と騒いでいる。
でも、ゴミを入れればゴミが出てくるのがAIの絶対法則だ。
データ取り込みのパイプラインが勝負の分かれ目になる。
空間配置を維持するというアプローチは、極めて理にかなっている。
現代のLLMは、膨大なアスキーアートやフォーマット済みのテキストファイルを学習している。
無理に壊れたMarkdownを読ませるより、スペースで位置合わせされたテキストのほうがはるかにマシだ。
最新のLLMが持つ空間推論能力を最大限に活かす解決策だ。
TypeScriptネイティブであることの意義は大きい。
AI開発のエコシステムは長らくPythonに支配されてきた。
だが、フロントエンドやバックエンドの多くはNode.jsで動いている。
しんたろー:
Claude Codeで毎日TypeScript書いてる身からすると、Python依存なしで動くローカルパーサーはかなり気になる。
環境構築で仮想環境が壊れる地獄から解放されるのは大きいと思った。
Webデータの取り込みも一筋縄ではいかない。
Difyのナレッジパイプラインを使う際も、データソースの選択が鍵になる。
FirecrawlやJina Reader、Watercrawl、Tavilyなど、複数のデータソース型プラグインが存在する。
リッチなUIのサイトをただスクレイピングすると悲惨な結果になる。
画像リンクや不要なフッターが大量にチャンクに混ざり込む。
SPAサイトではメインコンテンツの判定すら機能しないことが多い。
ここでノイズ除去に特化した抽出ツールの価値が上がる。
本文だけを綺麗に抜き出してくれるツールを使えば、トークン消費を抑えられる。
逆に、サイト全体を網羅的にクロールしたいなら別のツールを使う。
その場合、生のデータを直接ベクトルデータベースに入れるのは自殺行為だ。
必ずLLMによる前処理レイヤーを挟み、ノイズを除去してからチャンク化する。

チャンク分割の戦略も見直されている。
ただ改行で区切ったり、文字数で機械的に切ったりするのは古い。
セクション階層をメタデータとして保持し、意味的なまとまりでチャンク化する。
そうしないとベクトル検索は迷子になる。
同じ構造の表が複数ページに存在する場合、ベクトル検索はそれらに同程度のスコアをつけてしまう。
結果として、全く別の章にある類似の表を引っ張ってくる。
これを防ぐには「これは第3章のデータだ」という文脈をメタデータとして持たせる。
これを見て、チャンク分割の重要性を改めて考えさせられた。
階層構造を無視して文字数で切ると、文脈が途切れるのも納得だと思った。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
開発パイプラインの再設計と実務への落とし込み
僕らの開発にどう影響するのか。
今日からRAGのアーキテクチャ設計が変わる。
検索アルゴリズムをチューニングする前に、やることが山ほどある。
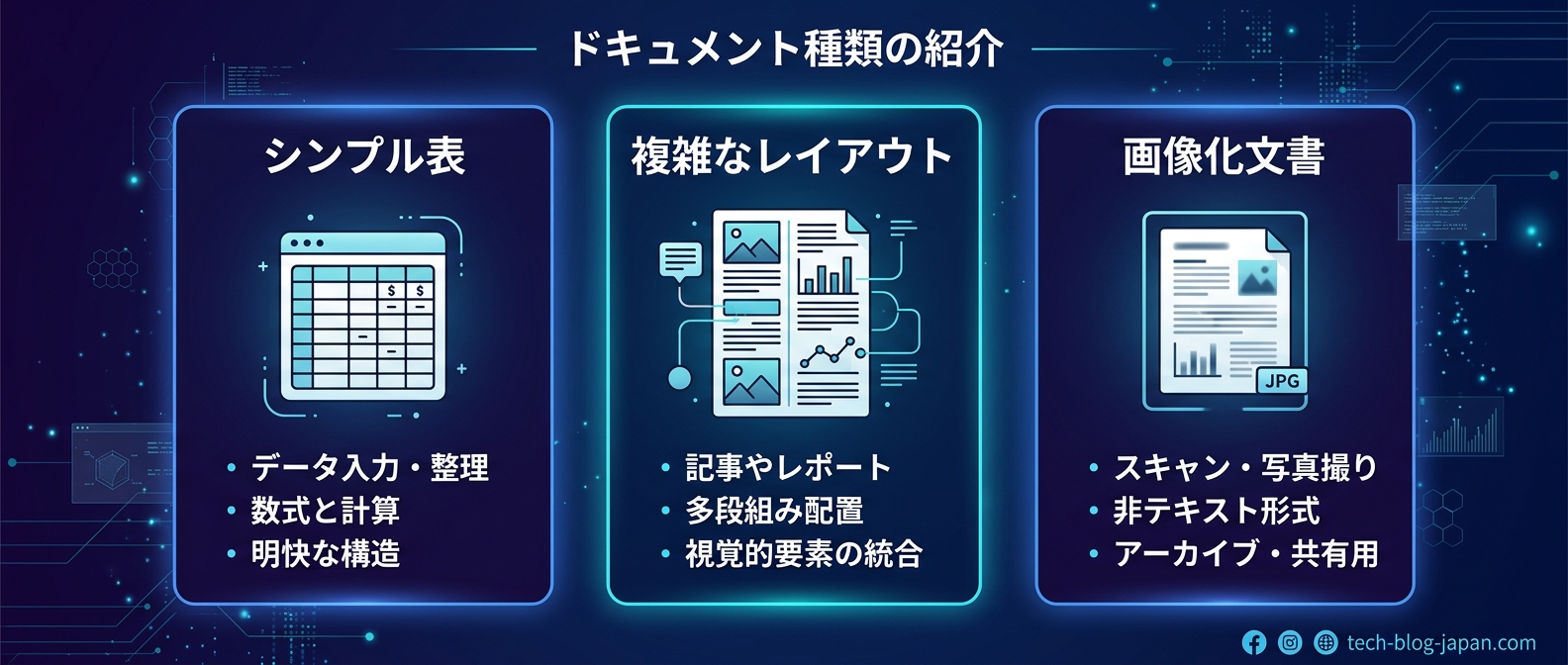
まず、PDFの解析戦略をドキュメントの性質によって分ける。
以下のような基準でツールを選択する。
* 構造がシンプルで綺麗な表: 従来のMarkdown変換ツールで確実に取り込む
* 複雑な仕様書やマルチカラム: 空間配置を維持するLiteParseを使い、LLMの推論能力に委ねる
* 画像化された古い文書: ローカルで動く軽量なOCRを組み合わせる
次に、Webデータの取り込みパイプラインだ。
直接ベクトルデータベースに突っ込むのは避ける。
必ずLLMによる前処理レイヤーを構築する。
ノイズを除去し、意味のある単位でテキストを再構築するステップを踏む。
チャンクへのメタデータ付与も徹底する。
ドキュメントのタイトルだけでなく、章、節、項のレベルまで階層構造をパースして付与する。
e5-largeなどの特定の埋め込みモデルは、クエリとドキュメントに特定のプレフィックスを付ける仕様になっている。
これを忘れると検索精度が下がる。
検索手法も、クエリの複雑さに応じて動的にルーティングする設計が理想だ。
すべての質問に重い処理を走らせる必要はない。
* 単純な事実確認: BM25と組み合わせたHybrid RAG + Reranker
* 複数セクションを横断する比較: LLMが自律的に複数回検索を行うAgentic RAG
* 概念的な質問: 意味理解に強い強力な埋め込みモデルによる単一検索
全部Agentic RAGにしたらAPI代が高騰しそうだと思った。
クエリの意図を最初に軽量モデルで判定して、処理ルートを振り分ける構成が気になっている。
RAGの精度向上は、泥臭いデータクレンジングの積み重ねだ。
銀の弾丸はない。
だが、空間配置の維持やTypeScriptネイティブなパーサーの登場により、その泥臭い作業を自動化・効率化する道が見えてきた。
最新のツールチェーンをキャッチアップし、パイプラインを常にアップデートしていく。
FAQ
Q1: PDFの表データをRAGに組み込む際、Markdown変換と空間配置維持のどちらを選ぶべきですか?
A1: 対象のPDFの複雑さと使用するLLMの能力に依存する。構造が比較的整っている仕様書であれば、Markdown変換が確実だ。一方、マルチカラムやネストされた複雑な表が含まれる場合、Markdown変換が破綻しやすい。空間配置を維持し、最新LLMの空間推論能力に委ねるアプローチが有効だ。
Q2: WebページをRAGのデータソースにする場合、どのツールを使うのが最適ですか?
A2: テキスト中心のドキュメントやノイズを極力排除したい場合は、FirecrawlやJina Readerなどクリーンな抽出が可能なツールが最適だ。一方、サイト全体を深くクロールしたい場合や情報量を最大化したい場合は、クローラー型のツールが適している。ただし、抽出後のLLMによる前処理レイヤーを挟む。
Q3: RAGの検索精度が上がらない場合、まず何を見直すべきですか?
A3: 検索アルゴリズムの前に「チャンク分割とメタデータ」を見直す。同一構造のテーブルが複数あるとベクトル検索は混乱する。セクション階層のメタデータ付与や、LLMを用いた意味的まとまりでのチャンク化など、前処理の質が検索精度の上限を決定する。
まとめ
RAGの勝負は、検索エンジンを回す前の「データ準備」の段階で既に決まっている。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
