
AIエージェント開発に興味を持っても、何から手を付ければいいか迷う人は多い。
初日に環境を構築して簡単なチャットボットを動かしたあと、次の一歩を踏み出せずにいるエンジニアは少なくないはずだ。
現在のAI開発は、単なるプロンプト入力から、自律的に思考して行動するエージェントの構築へと完全にシフトしている。
結論から言うと、単なるプロンプト作成の段階から抜け出し、データ構造の理解から複数エージェントの連携へと進むのが最短ルートになる。
この記事では、基礎を終えた人が商用レベルの自律型システムを作るための6つのステップを詳細に解説する。
順番に学べば必ず実装力は身につくはずだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
前提知識:開発を始める前に必要な準備
エージェント開発を始めるにあたり、Pythonの基礎知識とAPIを利用するためのアカウントが必要になる。
完璧な文法暗記は不要だが、辞書型やリストの操作、APIとの通信の仕組みは理解しておくといい。
特に非同期処理を扱うためのライブラリや、HTTPリクエストを行うライブラリの基本的な使い方は押さえておく必要がある。
開発環境としては、一般的なスペックのPCがあれば十分にクラウドAPI経由で開発可能だ。
ローカルで重いモデルを動かさない限り、高価なGPUを搭載したマシンを用意する必要はない。
まずは開発者アカウントを作成し、少額のクレジットをチャージするところから始めよう。
ステップ1:データ構造とトークン管理の基礎固め
AIとの対話は、実質的にJSON形式のデータのやり取りだ。
単なるテキストのやり取りから卒業し、入出力の型を厳密に定義するスキルを身につける必要がある。
まずはPydanticなどのデータ検証ライブラリを使って、スキーマ定義や関数呼び出しの仕組みを理解しよう。
データ検証ライブラリを使えば、AIが返してきたデータが期待する型と一致しているかを自動で検証できる。
もし型が違っていれば、エラーメッセージをAIに返して修正させる自己修復ループを組むことも可能になる。
AIは魔法の杖ではなく、入力したデータ構造に従って出力するシステムに過ぎない。
入出力の型を定義し、期待通りのデータフォーマットで返答させることこそが、開発者の最初の仕事になる。
ここを疎かにすると、どんなに高性能なAIを使っても期待外れの結果しか返ってこない。
また、LLMには一度に処理できるコンテキスト窓の限界がある。
なぜAIは長文の末尾で文脈を失うのか、なぜAPIコストが急騰するのか、その答えはすべてトークンにある。
専用のライブラリを使って、テキストが何トークン消費するかを計量的に把握する習慣をつけよう。
無駄なプロンプトを削り、必要な情報だけを的確に渡す技術が、コストパフォーマンスの高いシステム構築に直結する。
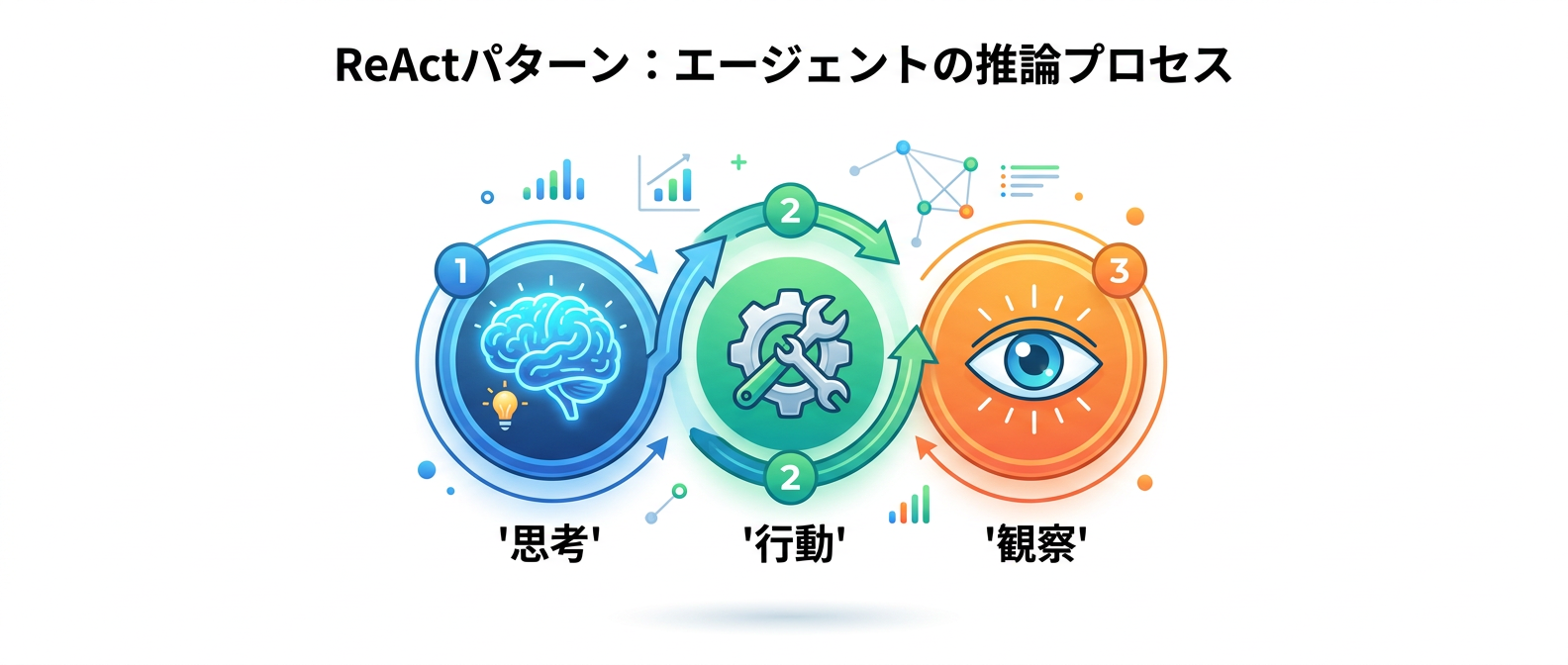
ステップ2:ReActパターンとエージェントアーキテクチャの理解
単なる応答ボットを自律型エージェントへ進化させるには、ReActパターンの本質を学ぶ必要がある。
ここで重要になるのが、推論と行動を組み合わせたプロンプトエンジニアリングの手法だ。
AIに現状を分析する、必要なツールを選ぶ、実行結果を観察するというプロセスを明示的に踏ませる仕組みを構築する。
Claude APIなどを活用して、この考えてから動くプロセスをコードに落とし込むといい。
AI自身に計画を立てさせ、それを実行に移すサイクルを作り出すのだ。
これができるようになると、エージェントの賢さは劇的に向上する。
複雑なタスクを与えられても、自ら手順を分解して一つずつ解決していく姿を見ることができるはずだ。
さらに、ユーザーを待たせずに応答を返すストリーミング処理や、コンテキスト管理の実装方法もここで習得する。
状態を保持しながら連続してタスクをこなす基礎がここで完成する。
自律的な動作の仕組みがわかれば、応用範囲は一気に広がるはずだ。
ステップ3:外部ツール連携とメモリシステムの構築
エージェントにWeb検索やファイル操作、データベース操作などの機能を持たせる段階だ。
ここではツールシステム設計パターンを学び、関数呼び出しを駆使して外部システムと連携させる。
AIが自ら必要なツールを選び、必要な引数を生成し、実行結果を受け取って次の行動を決める流れを作る。
たとえば、ユーザーから最新のニュースを調べて要約してと頼まれた場合を想像してみるといい。
AIが自律的にWeb検索ツールを叩いて結果を取得し、それを要約して返すイメージだ。
これが実装できれば、単なるチャットボットから実用的なアシスタントへと生まれ変わる。
社内のAPIやスプレッドシートと連携させれば、業務効率化の強力な武器になる。
さらに、過去の対話や状態を保持するメモリシステムの実装もここで行う。
会話履歴をすべてプロンプトに詰め込むと、すぐにトークン制限に引っかかってしまう。
重要な情報を要約して記憶させることで、文脈を失わずに長期的なタスクをこなせるようになる。
短期記憶と長期記憶を使い分けるアーキテクチャを設計できれば、より人間に近い対応が可能になる。
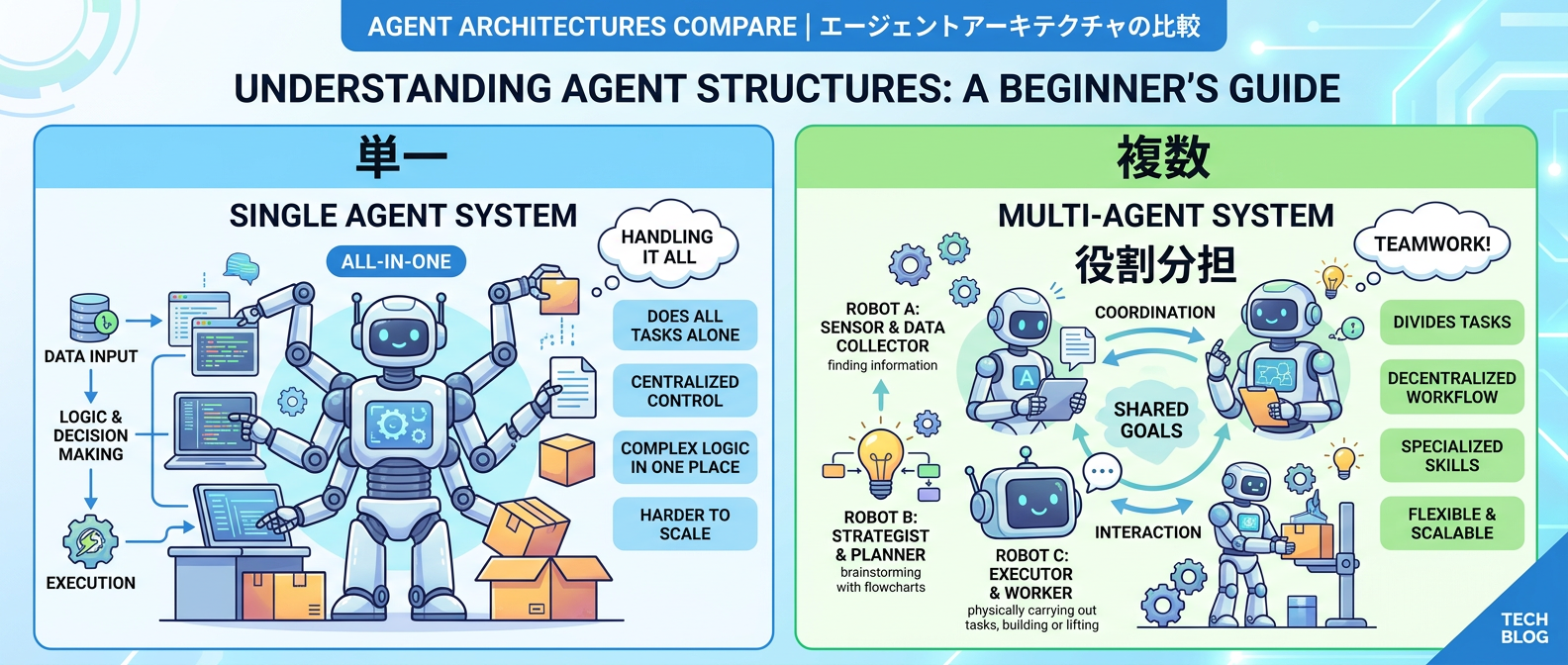
ステップ4:複数エージェントの役割定義と連携
1つのエージェントになんでも任せるのではなく、複数の専門エージェントに分割するアプローチだ。
汎用的な処理を担当するエージェントと、特定業務に特化したエージェントに明確な役割と名前を与える。
タスクを分割して連携させることで、複雑な業務パイプラインを構築できる。
汎用ブレインと、ブログ執筆専門の専門家、コードレビュー専門の専門家を分けるようなイメージを持つとわかりやすい。
名前と役割を明確に分けることで、システム全体の挙動が把握しやすくなるはずだ。
誰がどのタスクを担当しているのか、開発者自身が迷わずに済む。
マルチエージェントフレームワークの概念を学ぶのもこの段階になる。
状態変化をトリガーとした自律的な業務引き継ぎの実装もここで行う。
リアクティブな応答だけでなく、プロアクティブに動くシステムへと進化させる。
このオーケストレーションの連携設計が、商用レベルのアプリケーション開発の要になる。
エージェント同士が議論を交わし、最適な結論を導き出す高度なシステムも夢ではない。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
ステップ5:Slack連携と無限ループ防止
開発したエージェントを実務で使えるように、Slack連携などのチャットツール統合を行う。
イベント駆動型インターフェースを構築し、メンションに反応して動く仕組みを作る。
ローカル環境から安全にイベントを受け取るためのソケット通信の設定など、インフラ周りの知識も少し必要になる。
ターゲットユーザーが普段使っているプラットフォームに展開するスキルも身につけておきたい。
ここで最も注意すべきは、エージェント同士の無限ループだ。
複数エージェントが同じチャンネルにいる場合、互いの発言に反応し続ける危険がある。
向かい合った2枚の鏡のように、意味のない会話が永遠に続く事態は絶対に避けなければならない。
これを防ぐため、ボットからのメッセージを無視する制御ロジックを必ず実装しよう。
チャンネルごとの許可設定などを細かくチューニングしていく。
APIコストの枯渇を防ぐための重要な安全装置になる。
特定のキーワードが含まれている場合のみ反応するような、条件分岐のロジックを組み込むのも有効な手段だ。
ステップ6:本番環境に向けた信頼性設計
最後に、本番環境でも安定稼働する商用レベルのシステムへと仕上げる。
仮想環境管理ツールを用いて開発環境を徹底的に隔離し、ライブラリのバージョン依存によるトラブルを防ぐ。
AI界隈のライブラリ更新速度は異常なまでに速く、昨日動いたコードが今日非推奨になることも珍しくない。
コンテナ技術を活用して、環境のポータビリティを高めるアプローチも非常に有効だ。
どの環境でも同一の挙動を保証する仕組み作りが不可欠だ。
APIのレートリミットやエラーに備えたリトライ機構、フォールバック処理も導入する。
これらは地味だが、システムを運用する上では最も重要な部分になる。
一時的なAPIのダウンタイムでシステム全体が停止しないよう、堅牢なエラーハンドリングを実装する必要がある。
テストやモニタリングの仕組みを整えることで、不確実なAIの出力を確実なシステムに組み込める。
エラーが起きた際にどこで止まったのか、すぐに追跡できるログ設計も忘れずに行うといい。
プロンプトのバージョン管理を行い、出力品質の変化を追跡できる体制を整えれば完璧だ。
ここまで来れば、単なるプロンプト作成者ではなく、立派なAIエージェント開発者だ。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、エージェントの型定義やボイラープレートの作成が一番使いやすかった。
理由はシンプルで、ターミナル上でスキーマを作ってと指示するだけで、面倒な構造化定義を正確に書き上げてくれるからだ。
つまずきポイント
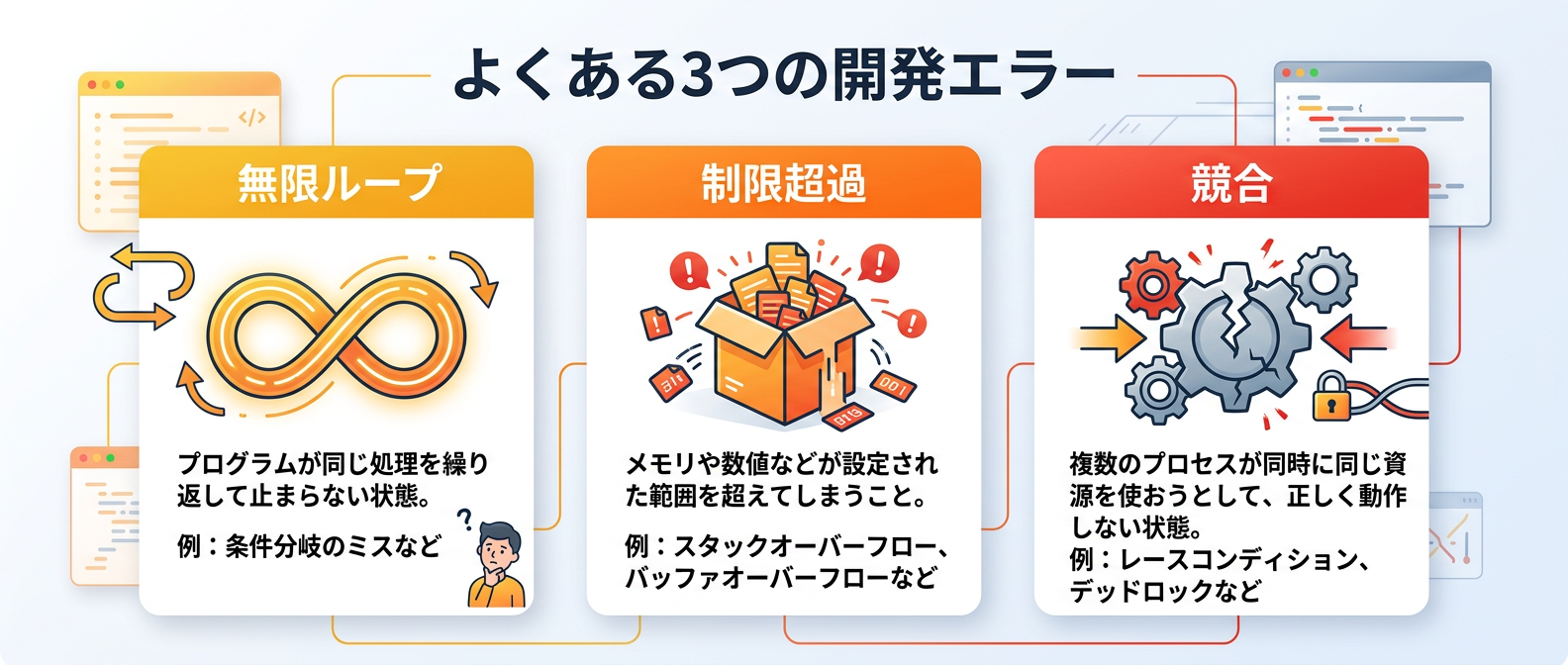
初心者がエージェント開発でハマりやすい罠を3つ紹介する。
事前に対策を知っておけば、無駄な時間を大幅に削減できる。
- 無限ループによるコスト爆発
エージェント同士が会話を始めて止まらなくなる現象だ。
ボットは他のボットを無視する設定を必ず入れよう。
メッセージの送信元IDを判定し、ボット自身や他のボットからのイベントは早期リターンで処理を終了させるロジックが必須になる。
- コンテキスト窓の超過
過去の会話をすべてプロンプトに詰め込むと、すぐに制限に引っかかる。
要約機能を持たせたメモリシステムの実装が必須になる。
直近の数ターンだけをそのまま保持し、それ以前の会話は別のLLM呼び出しで要約テキストに変換して保存するハイブリッドなアプローチが効果的だ。
- ライブラリのバージョン競合
AI界隈は技術の進歩が速く、破壊的変更が日常茶飯事だ。
仮想環境でバージョンを固定する癖をつけよう。
設定ファイルでバージョンを厳密に指定し、定期的に依存関係のアップデートテストを行う運用体制を構築するといい。
エージェント開発向けLLM比較表
ここで、エージェント開発の頭脳となる主要なLLMの特徴をまとめておく。
用途に合わせて最適なものを選ぶといい。
| モデル名 | 得意分野 | 料金の目安 | おすすめ度 |
|---|---|---|---|
| Claude 3.5 Sonnet | コーディング・論理的推論 | 中〜高 | ★★★★★ |
| GPT-4o | 汎用タスク・外部ツール連携 | 中〜高 | ★★★★☆ |
| Gemini 1.5 Pro | 超長文コンテキスト処理 | 中 | ★★★★☆ |
FAQ
AIエージェント開発にPythonのスキルはどの程度必要?
文法をすべて暗記している必要はないが、コードを読んで何をしているか言語化できる能力は必須だ。
特に辞書型やリストの操作、データクラスの定義、非同期通信の基礎は重要になる。
AIが生成したコードの非効率性を見抜くためにも、データ構造の基礎理解は欠かせない。
まずは小さなツールを作りながら学ぶのが効果的だ。
エラーが出た際に、スタックトレースを読んで原因を特定できるレベルのデバッグ能力があれば、開発はスムーズに進むはずだ。
エージェントに外部ツールを使わせるにはどうすればいい?
関数呼び出しという仕組みを利用する。
エージェントが使えるツールの仕様や引数の型をJSONスキーマなどで定義し、LLMに渡す。
LLMがツールを使うと判断したら、その結果を受け取って実際のPython関数を実行し、結果を再びLLMに戻す流れだ。
これで外部システムと連携した自律的な処理が可能になる。
天気APIやデータベース検索など、身近なAPIをラップした関数を作って試してみると理解が深まる。
複数のエージェントを連携させる際の注意点は?
最も注意すべきはエージェント同士の無限ループだ。
互いの発言に反応し続けると、APIコストが枯渇するまで無意味な会話が続いてしまう。
これを防ぐため、ボットは他のボットからのメッセージを無視する制御ロジックを必ず組み込もう。
各エージェントの役割と名前を明確に分けることも重要だ。
タスクの受け渡しフォーマットを厳密に定義し、エージェント間のインターフェースを統一することで、予期せぬ動作を防ぐことができる。
APIコストやトークン制限にはどう対処すべき?
テキストが何トークン消費するかを計量的に把握する習慣をつけることが第一歩だ。
過去の会話履歴をすべてプロンプトに含めるのではなく、重要な情報を要約して保持するメモリシステムを実装するといい。
これでエージェントの精度を保ちながらコストを最適化できる。
無駄に長い入力は文脈の喪失やコストの急騰を招く原因になる。
開発中は安価な軽量モデルを使用し、本番環境でのみ高性能モデルに切り替える運用もコスト削減に直結する。
ローカル環境で開発する際、PCのスペックはどの程度必要?
クラウドAPIを利用してロジックを開発するだけであれば、一般的なPCスペックで十分に開発可能だ。
重い処理はクラウド側で行われるため、特別なハードウェアは必要ない。
ただし将来的にローカルでLLMを動かすなら、大容量メモリを搭載した環境を用意するといい。
機密情報の扱いやコスト削減を見据えるなら高スペックPCの導入も検討の余地がある。
まずは手元のノートPCでクラウドAPIを叩くところからスタートするのが最も効率的なアプローチだ。
まとめ
AIエージェント開発は、データ構造の理解から始まり、複数エージェントの連携へと段階的に進む。
基礎を固めずに応用へ進むと、必ずどこかで壁にぶつかるはずだ。
まずは単一のエージェントを作り、外部ツールと連携させるところから始めよう。
小さな成功体験を積み重ねることで、複雑なシステムを構築する自信とスキルが自然と身についていく。
複数エージェントのオーケストレーション系のフレームワークは色々出ているから、いくつか試してみたいところだ。
役割を明確に分ける設計思想は、僕が開発しているThreadPostのバックエンドアーキテクチャにも通じる部分があって非常に興味深い。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
