
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
モデルの寿命は1ヶ月になった
MidjourneyのV8.0モデルがリリースされてから1ヶ月が経過した。
V8.1アルファ版が公開され、数週間後には旧モデルが廃止される。
モデルの進化速度は速い。
最新のAIモデルに最適化してコードを書いた直後、そのモデル自体が消滅する。
これは画像生成に限った話ではない。
Claude Codeで一人SaaSを開発する現場において、このモデルの短命化は現実的な脅威だ。
終わらないモデルアップデートと開発者の現実
AIモデルの更新サイクルは加速している。
MidjourneyはV8.0のテスト期間を1ヶ月で切り上げ、V8.1への移行を発表した。
V8.0モデルは数週間以内に廃止される。
ユーザーは最新モデルへの追従を求められる。
LLMの領域でも状況は同じだ。
毎週のように新しいオープンモデルが登場し、ファインチューニングやRAGの調整が求められる。
この状況に対し、開発現場では2つの動きがある。
1つは、RAGの精度改善技術の細分化と構造化だ。
RAGを構築するのは数時間で終わる。
しかし、実業務で使えるレベルに精度を上げるための技術は74種類に及ぶ。
これらの技術は6つのカテゴリに分類される。
DB構築、検索クエリ生成、検索手法、検索結果の後処理、生成パイプラインの制御、LLMモデルの最適化だ。
モデルの性能だけでなく、データの前処理と検索パイプラインの品質が結果を左右する。
DB構築の段階では、テキストの正規化が影響する。
日本語特有の全角半角の揺れや、長音記号の不統一を排除する処理だ。
検索クエリの生成では、同義語辞書の活用が鍵となる。
同一概念に対する異なる表現を吸収し、検索エンジンに登録することで語彙の不一致を防ぐ。
ユーザーの質問を検索に適した形に書き換えるクエリ変換技術も存在する。
チャンキングの技術も変化している。
固定文字数ではなく、文章の意味的なまとまりに基づいて分割するセマンティックチャンキングが利用される。
分割されたチャンクに親文書の文脈を付与するコンテキスト補完技術も注目されている。
検索時には小さなチャンクで検索し、LLMには大きな親文書を渡す階層的なアプローチも実用化された。
4,000トークンという単位でドキュメントを処理するロングコンテキストLLM向けの手法も台頭している。
検索結果の後処理も存在する。
取得した文書をそのままLLMに渡すのではなく、関連度の低い情報をフィルタリングするリランキング技術が標準になりつつある。
生成パイプラインの制御も高度化している。
LLMに自己検証させ、回答に必要な情報が不足していれば自動で再検索を行う自律的なオーケストレーションが求められている。
もう1つの動きが、ファインチューニング基盤の統合だ。
100種類以上のLLMをコーディングなしで微調整できる統合フレームワークが台頭している。
LoRAやQLoRA、RLHF、DPOといった手法をWebUIから操作できる。
25,000以上のスターを集めるプロジェクトは、モデルごとの個別対応という開発者の負担を解消する。
Hugging Faceに登録されている5,000以上のオープンLLMを、同一のインターフェースで扱える。
モデルの寿命が短くなる中で、開発者の関心は移行した。
「どのモデルを使うか」から「モデルをどう管理し、どうデータを食わせるか」へのパラダイムシフトだ。
最新のAIモデルを追いかけるだけでは、プロダクトは維持できない。
しんたろー:
OpenAIもAnthropicも次から次へと新しいモデルを出してくる。
Claude CodeでAPI呼び出しのロジックを綺麗に書いた翌日に「非推奨です」と言われると気になる。
モデルのバージョンアップに一喜一憂する日々だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
ブラックボックスへの依存からパイプラインの制御へ
AI開発のフェーズは変化した。
モデルの性能向上というブラックボックスへの依存は、技術的負債となる。
MidjourneyのV8.1移行が示す通り、SOTAモデルの寿命は数週間単位だ。
モデルの挙動に強く依存したプロンプトや実装は、次のアップデートで壊れる。
今、開発者はデータ構造とパイプラインの最適化に注力する。
モデルを「計算エンジン」として扱い、その前後のエンジニアリングで品質を担保する。
RAGの実装において、この傾向は顕著だ。
検索の土台となるテキストの正規化処理を怠れば、優秀なLLMを使っても出力に影響が出る。
日本語特有の全角半角の揺れや、長音記号の不統一がある。
これらを前処理で排除することが、検索精度の生命線となる。
同じ概念が表記の違いだけで別物として扱われると、高度な検索手法を使っても精度は上がらない。
チャンキングの設計がRAGの成否を分ける。
固定文字数で機械的に分割する手法は過去のものとなった。
文章の意味的なまとまりに基づいて分割するセマンティックチャンキングがある。
隣接する文の埋め込みベクトル間の類似度を計算し、話題の切れ目を判定する。
これにより、固定長分割で起こりがちな文脈の途中切れを防ぐことができる。
分割されたチャンクに親文書の文脈を付与するコンテキスト補完技術がある。
各チャンクに対してLLMが親文書全体を参照し、短いコンテキスト文を生成して先頭に付与する。
通常のチャンクは分割によって主語や背景情報が失われがちだが、この手法により文脈が補完される。
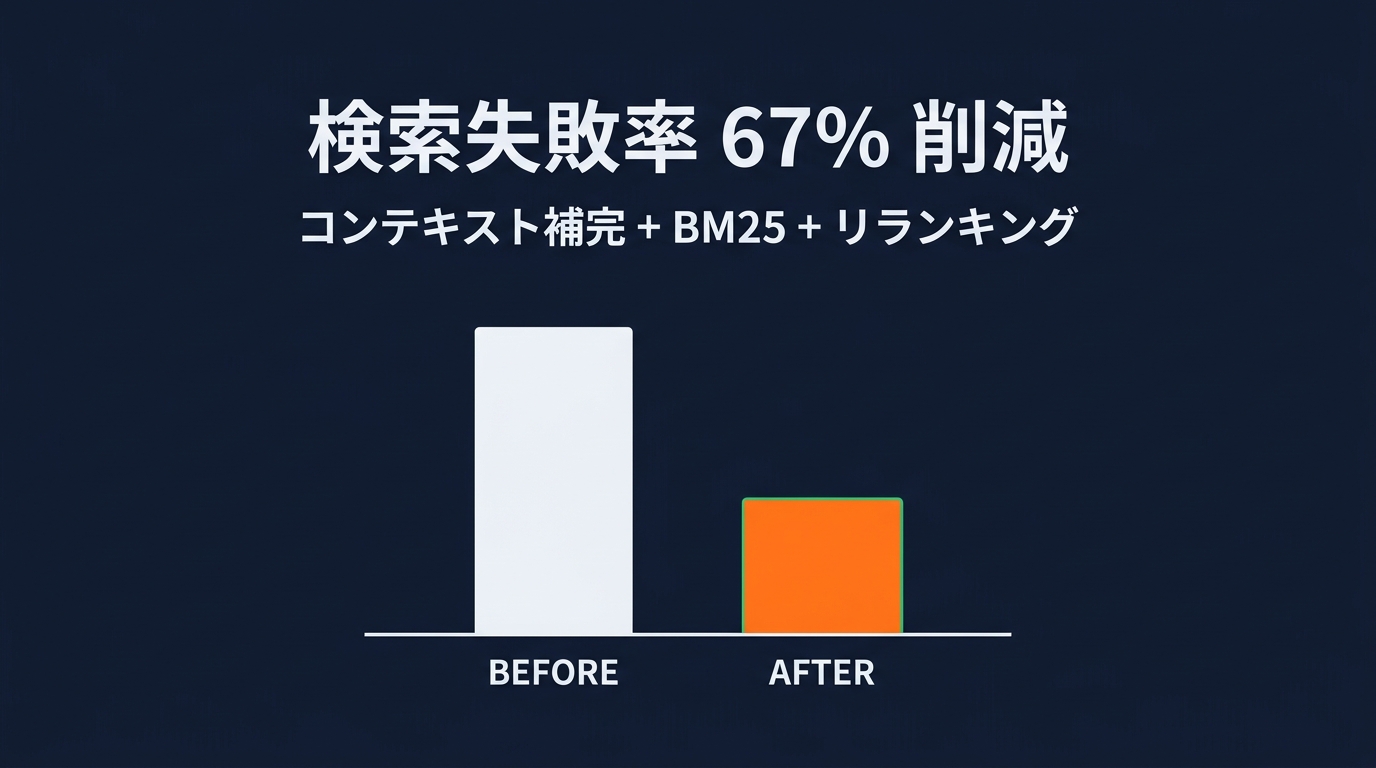
データがこの事実を裏付けている。
コンテキスト補完、BM25、リランキングの3つを組み合わせることで、検索失敗率を67%削減できる。
文書を検索用の小さなチャンクと、LLMに渡す大きなチャンクの2階層に分割する手法も有効だ。
検索時には200トークン程度の小チャンクで部分一致を狙う。
ヒットした小チャンクに紐づく2000トークン程度の親文書をLLMのコンテキストとして渡す。
検索精度と回答に必要な文脈量のトレードオフを解消するアプローチだ。
モデルのバージョンアップを待つよりも、データの前処理を改善する方が費用対効果が高い。
ファインチューニングの領域でも、アプローチは変化している。
毎週新しいモデルが登場する中、特定のモデルに特化した学習スクリプトを書くことは非効率だ。
これまではモデルごとに異なるライブラリやスクリプトを用意し、依存関係の競合に悩まされていた。
しかし、統合フレームワークを使えば、パラメータの設定から学習の実行、評価までを単一のWebUIで完結できる。
100種類以上のモデルを統一的なインターフェースで扱える統合フレームワークの価値はここにある。
モデルの入れ替えコストを下げることで、開発者はデータセットの品質向上に集中できる。
Hugging Faceに登録されている5,000以上のオープンLLMを、個別対応なしで扱える。
Claude Codeを使った開発でも、この視点は欠かせない。
AIにコードを書かせる際も、モデルへの依存度を下げるアーキテクチャ設計を指示する。
モデルの呼び出し部分は抽象化する。
データの前処理や評価ロジックの実装にClaude Codeの生成能力を振り向ける。
これが、変化の激しいAI業界で生き残るための開発スタイルだ。
日本語の表記揺れ問題は闇が深い。
「サーバー」と「サーバ」の違いだけで検索から漏れるのは、AI以前の検索エンジンの時代から変わっていない。
最新のベクトル検索でもここをサボると精度が出ないのは皮肉だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
モデルの入れ替えに耐えうる堅牢なアーキテクチャの構築
日々の開発に落とし込む必要がある。
モデルを「プラグイン可能なコンポーネント」として扱う設計を徹底する。
特定のLLMや画像生成APIに直接依存するコードは捨てる。
間に抽象化レイヤーを挟み、モデルの切り替えを環境変数の変更だけで完結させる。
Midjourneyのように旧モデルが数週間で廃止される事態は、APIの世界でも頻発する。
常に最新モデルでの回帰テストを自動化できる環境が必須だ。
RAGの精度が上がらない場合、ボトルネックを可視化する。
検索クエリの生成、チャンキング、ドキュメントの正規化のどこで情報が欠落しているかを特定する。
具体的なアクションアイテムは以下の通りだ。
* テキスト正規化の徹底: 日本語特有の表記揺れを吸収する前処理パイプラインを構築する
* セマンティックチャンキングの導入: 固定長分割をやめ、意味のまとまりでデータを分割する
* コンテキストの付与: 分割後のチャンクに親文書の背景情報を自動付与する仕組みを入れる
* 同義語辞書の整備: ドメイン固有の用語を吸収する辞書をLLMに自動生成させる
* 抽象化レイヤーの実装: モデルのAPI呼び出しをカプセル化し、直接参照を避ける
* 回帰テストの自動化: モデル変更時にシステムの出力品質を定量評価するテストを組む
* 統合フレームワークの活用: ファインチューニングには特定モデルに依存しないツールを選ぶ
* 検索結果のフィルタリング: LLMに渡す前に、関連度の低い情報を足切りする後処理を入れる
これらの実装は簡単ではない。
しかし、Claude Codeを使えば、既存のRAGパイプラインのリファクタリングや前処理ロジックの追加は早くなる。
例えば、テキストの正規化処理を導入する際、Claude Codeに既存のデータ投入スクリプトを読み込ませる。
全角半角の統一や長音記号の処理を行う関数を生成させ、パイプラインの適切な位置に組み込むよう指示する。
手作業で行えば数時間かかるリファクタリングが、短時間で完了する。
同義語辞書の自動生成スクリプトの作成も、Claude Codeの領域だ。
ドメイン固有のテキストデータを読み込ませ、LLMを使って同義語ペアを抽出するバッチ処理を生成させる。
これを定期実行する仕組みを作れば、辞書のメンテナンスコストは下がる。
データパイプラインのモジュール化を進める。
ドキュメントの読み込み、分割、ベクトル化、検索の各プロセスを疎結合に保つ。
一部のロジックを変更した際の影響範囲を最小限に抑えることができる。
テストコードの自動生成も徹底する。
Claude Codeにモックを使ったAPI呼び出しのテストを書かせ、CI/CDパイプラインに組み込む。
モデルが入れ替わっても、システム全体の挙動が壊れていないことを即座に確認できる体制を作る。
評価指標を用いた定量評価の仕組み作りも欠かせない。
検索結果の再現率を定期的に計測し、どの段階で情報が漏れているかを監視する。
モデルの進化を追いかけるのは疲弊する。
自社プロダクトのコア資産となるデータパイプラインの構築にリソースを集中させる。
モデルの更新はコンポーネントの入れ替え作業に落とし込む。
それが、AIの進化に振り回されずにプロダクトを成長させる道だ。
抽象化レイヤーを作るのは最初は手間だが、後からやっていてよかったと感じる。
Claude Codeに「このAPI呼び出し部分、モデル差し替え可能なインターフェースに書き換えて」と頼むと一瞬でやってくれる。
テストコードまでセットで書かせれば完璧だ。
よくある質問
Q1: モデルの更新が頻繁ですが、プロダクトに組み込む際のベストプラクティスは?
モデルの仕様変更や廃止に備え、APIに直接依存するロジックを最小化する抽象化レイヤーの導入を行う。
特定のモデルの挙動に依存したプロンプトや処理は、次のアップデートで破綻する可能性がある。
常に最新モデルでの回帰テストを自動で実行できる評価基盤を構築し、モデルを交換可能な部品として扱うアーキテクチャ設計を行う。
出力を制御するパイプラインを自社で持つことが安定稼働の鍵となる。
Q2: RAGの精度が上がらない場合、どこから手をつけるべきですか?
まずは検索のボトルネックを特定し、情報の欠落箇所を可視化する。
特に日本語環境では、全角半角や長音記号の表記揺れを統一する正規化処理を行う。
ここを怠ると、高度な検索アルゴリズムを使っても精度は出ない。
次に、固定長でのチャンキングをやめ、セマンティックチャンキングによる文脈の維持を検討する。
検索結果の再現率を評価し、どの段階で必要なデータが漏れているかを定量的に把握する。
Q3: ファインチューニングとRAG、どちらを優先して開発すべきですか?
多くのユースケースにおいて、まずはRAGの構築とデータパイプラインの最適化を優先する。
ファインチューニングは特定のタスクやドメイン知識の定着には有効だが、モデルの更新サイクルが早い現状では、学習コストが無駄になるリスクがある。
RAGの検索精度やデータの前処理基盤は、モデルが入れ替わっても活用できる自社のコア資産となる。
統合フレームワークを使って微調整のコストを下げつつ、堅牢な検索パイプラインの構築に注力する。
モデルの進化に振り回されない開発者になるために
AIモデルの寿命が数週間単位になる中、開発者の戦い方は変わった。
最新モデルの性能に依存するのではなく、データとパイプラインを制する。
強固なアーキテクチャを構築し、変化を前提とした開発スタイルを確立する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
