
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
汎用AIの終焉と「思考する」特化モデルの台頭
OpenAIが次のフェーズへ移行した。
医療向けモデルと画像生成モデルで、同じアプローチが打ち出された。
キーワードは「生成前の思考」だ。
汎用AIにプロンプトを投げる時代は終わる。
これからの主戦場は、特定の業務フローに埋め込まれた、自律的に推論する専門ツールだ。
開発者に求められるのは、プロンプトの工夫ではない。
モデルの「思考プロセス」を制御し、評価し、コストを管理するアーキテクチャへの移行だ。
この変化の波に乗れないシステムは淘汰される。
OpenAIが仕掛ける垂直統合。医療と画像生成の最新動向
OpenAIが米国で医療特化のChatGPTを発表した。
認定を受けた医師、看護師、薬剤師に対して無料で提供される。
米国の医療現場は負担を強いられている。
患者数の増加。膨大な事務作業。医学研究のキャッチアップ。
調査によると、72%の医師がAIを臨床現場で利用している。
昨年から24ポイントの増加だ。
OpenAIは医療従事者と提携し、継続的なモデル評価と改善の基盤を構築した。
その中核となるのがHealthBench Professionalだ。
実際の臨床チャットタスクに基づいたオープンなベンチマークである。
診察の相談、文書作成、医学研究の3つのユースケースをカバーしている。
数百人の医師アドバイザーがモデルの回答をレビューする。
品質、推論の正確性、信頼性を評価し、モデルにフィードバックする体制だ。
医療というドメインに特化した品質保証プロセスが構築された。

画像生成モデルのアップデートも発表された。
GPT Image 2だ。
最大の特徴は、画像を生成する前にモデルが「考える」ことだ。
選択したモードに応じて推論に時間をかけ、その過程でWeb検索を自律的に行う。
1つのプロンプトから最大8枚の一貫性のある画像が生成できる。
キャラクターの顔立ち、オブジェクトの配置、スタイルがすべてのシーンで維持される。
マンガのページ生成や、SNS用の連続したグラフィック作成が可能になった。
描画の精度も底上げされている。
小さなテキスト、アイコン、UI要素、複雑な構図など、従来モデルが苦手としていた要素を克服した。
非ラテン文字の描画も改善されている。
アスペクト比は3:1のウルトラワイドから1:3の縦長まで対応する。
解像度はAPI経由で最大2Kまでサポートされる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
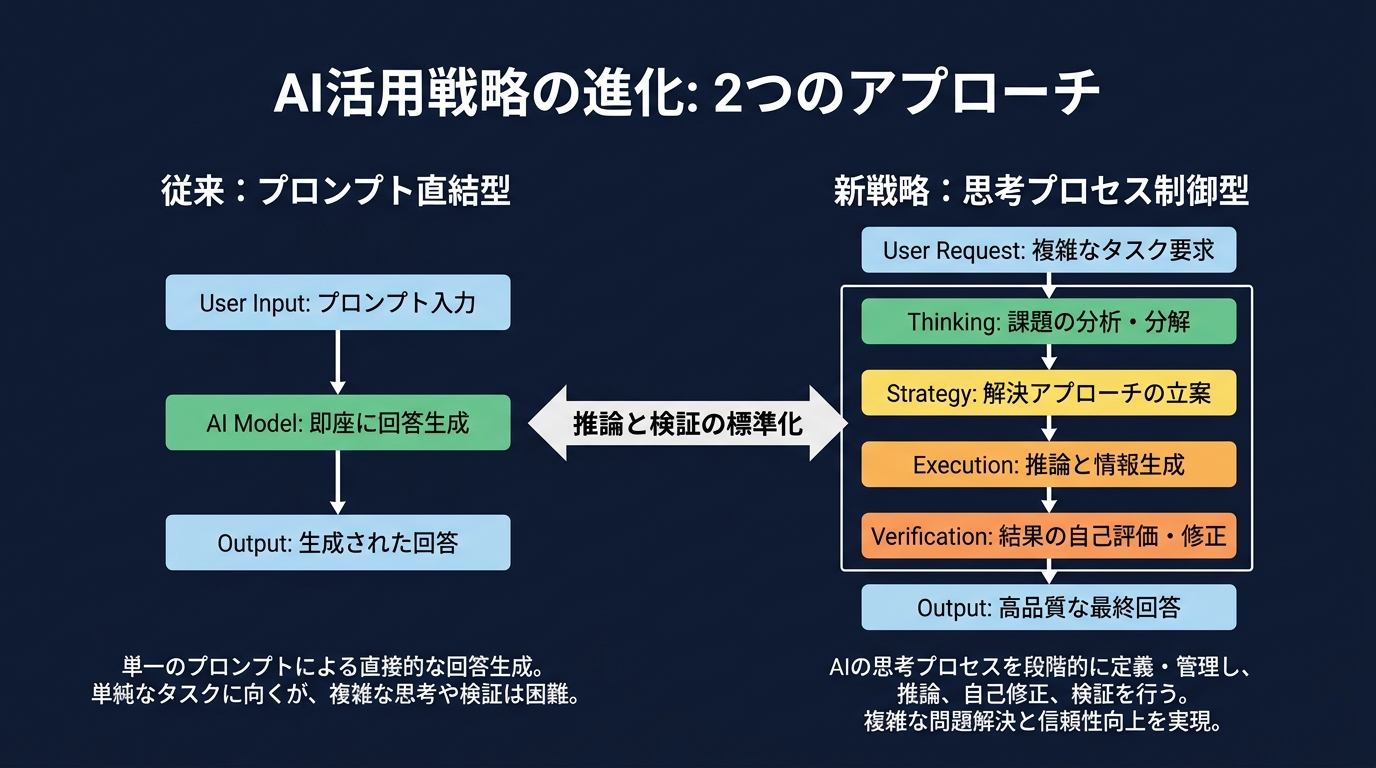
開発者目線で読み解く「思考プロセス」の標準化
推論モデルがもたらすパラダイムシフト
医療と画像生成。根底にある戦略は一致している。
「モデルが生成前に推論・検証を行うプロセス」の標準化だ。
これまでのLLMは、入力に対して確率的に次の単語を予測するだけだった。
ハルシネーションの抑制には限界があった。
医療と画像生成の2つの領域で、モデルに「思考(Thinking)」が組み込まれた。
医療では「医師のレビュー」という外部評価ループを回す。
画像では「推論とWeb検索」という内部検証ループを回す。
目的は「ハルシネーションの抑制と出力の一貫性の担保」だ。
汎用モデルをプロンプトで縛り付けるアプローチの限界を、OpenAI自身が認めた形だ。
しんたろー:
画像生成の裏でWeb検索を走らせるアプローチが気になる。
単純なプロンプトでも、裏でコンテキストを補完して一貫性を担保する仕組みだ。
APIの裏側で何回推論と検証を回しているのかが気になる。
APIコストの逆転現象が意味するもの
開発者にとって、これはアーキテクチャの見直しを意味する。
これまでは、LLMの出力結果だけを見ていればよかった。
これからは、LLMの「思考プロセス」自体を制御し、コストを計算する必要がある。
GPT Image 2のAPI料金構造は示唆に富んでいる。
画像入力トークンは100万あたり$8。出力は$30だ。
テキスト入力は100万あたり$5。出力は$10に設定されている。
実際の画像1枚あたりのコストは、品質と解像度で変動する。
1024x1024の低品質で$0.006。中品質で$0.053。高品質で$0.211だ。
旧モデルと比較すると、高品質の1024x1024は$0.133から$0.211に値上がりしている。
思考プロセスが介在する分、コンピュートリソースを消費し、コストが上昇している。
解像度によるコストの逆転現象も起きている。
1024x1536の大型解像度では、高品質で$0.165になる。
旧モデルの$0.20や$0.25よりも安くなっている。
モデルの推論効率やアーキテクチャの最適化が、特定の解像度で効いている。
用途と解像度に応じたコスト最適化が求められる。
Claude Codeと非同期アーキテクチャ
AIエージェントに画像生成APIや高度な推論APIを組み込む場合、リクエストを投げて待つだけでは済まない。
思考モードがオンになれば、レスポンスまでの遅延が予測不能になる。
数秒で返ってくることもあれば、数十秒かかることもある。
ユーザー体験を損なわないための非同期処理が必須になる。
プログレスバーの表示。スケルトンUIの実装。
バックグラウンドでのジョブキューイング。
推論時間を前提としたUX設計が、アプリケーションの品質を左右する。
単純なAPIラッパーのようなアプリは成立しない。
Claude Codeでバッチ処理を書いていると、APIのレイテンシ変動が厄介だ。
推論時間が読めないモデルを同期処理で呼ぶと、システム全体が詰まる。
キューイングの設計をやり直す必要があると思った。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響。僕らの開発はどう変わるのか
CI/CDへのLLM評価の統合
重要なのは「評価指標の自動化」と「原価の管理」だ。
HealthBenchのような評価指標の存在はヒントになる。
AIを組み込んだプロダクトを作るなら、独自のベンチマークが不可欠だ。
プロンプトを変更した際、出力の品質がどう変化するかを確認する。
CI/CDパイプラインに、LLMの評価プロセスを組み込む。
コードの変更が、AIの回答品質を劣化させていないか自動検知する仕組みだ。
OpenAIが医師を使ってやっていることを、システムで自動化する。
具体的には以下のような実装が求められる。
* 独自ベンチマークデータセットの構築
* LLMを評価者として用いる自動評価パイプラインの構築
* 回帰テストのCI/CDワークフローへの統合
* プロンプトバージョニングと品質スコアのトラッキング
汎用モデルの性能に依存するのではなく、ドメイン特化の評価基準を持つ。
それが、今後のAI開発のスタンダードになる。
トークン消費の予測と原価管理
コスト設計もシビアになる。
GPT Image 2のように、「思考」を伴うAPIはトークン消費が読みにくい。
ユーザーの入力の複雑さによって、モデルが深く考える度合いが変わる。
リクエストごとの原価がダイナミックに変動する。
SaaSを運営する上で、原価のブレは死活問題だ。
* ユーザーあたりのトークン消費上限のハードリミット設定
* 思考モードのオン/オフによるティアリング(料金プラン分け)
* キャッシュの積極的な活用による入力トークン削減
* 解像度と品質の組み合わせによるコスト最小化ルートの探索
これらをアーキテクチャの基本要件として組み込む。
本番環境で、いかに安定して、コスト効率よく運用するか。
エンジニアリングの力が問われている。
UX設計の再構築
推論モデルの導入は、ユーザーインターフェースにも影響を与える。
「AIが考えている時間」をどうデザインするか。
即時応答が当たり前だったWebアプリケーションの世界に、数十秒の待ち時間が発生する。
思考の途中経過をストリーミングで表示する。
あるいは、完全にバックグラウンド処理に回し、完了時に通知を送る。
アプリケーションの性質に合わせて、最適なUXを選択しなければならない。
AIツールの開発は、Web2.0時代の堅牢なシステム設計に戻ってきている。
キャッシュ戦略とキューの管理とコスト監視が大事だ。
魔法の杖ではなく、強力なコンポーネントとして扱うフェーズに入った。

FAQ
Q1: 医療特化のChatGPTは日本からでも利用できますか?
現時点では利用できない。米国で認定された医師、看護師、薬剤師を対象としたサービスだ。日本国内での利用について公式なアナウンスはない。ただし、HealthBenchのような評価手法や、専門家のレビューを介したモデル改善プロセスは、今後のグローバルモデルの品質基準になる。日本の医療AI開発者にとっても、評価指標の設計という観点で注視すべき動向だ。
Q2: 新しい画像生成API(GPT Image 2)は従来より安くなりましたか?
一概には言えない。1024x1024の高画質生成では1枚あたり$0.211となり、旧モデルの$0.133からコストは上昇している。思考プロセスによるトークン消費が影響している。一方で、1024x1536のような大型解像度では旧モデルより安価になるケースもある。用途と解像度に応じたコスト最適化が必要だ。API実装時には、品質とコストのトレードオフを検証するフェーズが必須となる。
Q3: API経由でモデルの「思考プロセス」をどこまで制御できますか?
完全なブラックボックスではないが、細かな制御は難しい。APIのパラメータで思考モードのオン/オフや、推論に割くコンピュート量の目安を指定する形になる。思考の途中で外部のデータベースを参照させたり、特定のロジックを強制したりすることはできない。そのため、モデルが正しい推論を行えるよう、システムプロンプトで前提条件や制約を定義する「コンテキスト設計」の重要性が増している。
まとめ
OpenAIが医療と画像生成で進める「推論の標準化」。
汎用モデルから専門特化のエージェントへと、開発のパラダイムが切り替わった。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
