
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
ついに「考える音声」がやってきた。開発者が待ち望んだ真のリアルタイムAI
OpenAIがGPT-Realtime-2を発表した。これは音声認識のアップデートではない。GPT-5クラスの推論能力が、そのまま音声インターフェースに統合された。
これまでの音声AIは、耳は良くても頭脳が追いついていなかった。これからは低遅延で、かつ複雑な論理思考を伴う音声対話がAPIで叩けるようになる。
音声・翻訳・書き起こしの3本柱。新しいリアルタイムAPIの全貌
今回発表されたのは、役割が明確に分かれた3つの新しいモデルだ。中心となるのがGPT-Realtime-2だ。
これは音声で直接やり取りしながら、高度な推論を実行できるモデルだ。GPT-5クラスの知能を備え、難しいリクエストに対しても文脈を維持したまま会話を継続できる。
次にGPT-Realtime-Translateだ。これはライブ翻訳に特化したモデルで、70以上の入力言語を理解し、13の出力言語へリアルタイムに翻訳する。
話者のペースに合わせて翻訳が生成されるため、同時通訳のような体験が実装できる。
そしてGPT-Realtime-Whisperだ。これはストリーミング形式で話しているそばから文字に起こしていく。
ユーザーが話し終わるのを待つ必要がない。
これらのモデルを統合することで、会話の流れの中で思考し、翻訳し、記録し、行動する多層的な音声インターフェースが実現する。
特に注目すべきは、GPT-Realtime-2の技術的なスペックだ。コンテキストウィンドウは128,000トークンへと拡張された。
これにより、長時間の会議や複雑な技術相談でも、文脈を失わずに会話を続けられる。さらに、並列ツール実行機能が強化されており、ユーザーと話しながら裏側で複数のAPIを同時に叩くことが可能になった。
また、モデルが自律的にフィラー(えーと、あの、など)を生成するようになった。AIが考え中であることをユーザーに自然に伝え、沈黙による不安を解消する。
利用料金についても明確な区分がある。GPT-Realtime-TranslateとGPT-Realtime-Whisperは分単位の利用時間に基づく課金だ。
一方で、知能を司るGPT-Realtime-2は、テキストモデルと同様にトークン消費量に基づいた課金体系となっている。
しんたろー:
音声APIは今まで「つぎはぎ」感が強かった。Whisperで取って、GPTで考えて、TTSで出す。このラグが苦痛だった。全部入りで、しかもGPT-5クラスの知能が乗るなら、もう戻れないな。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線で読み解く「推論レベルの動的制御」という新概念
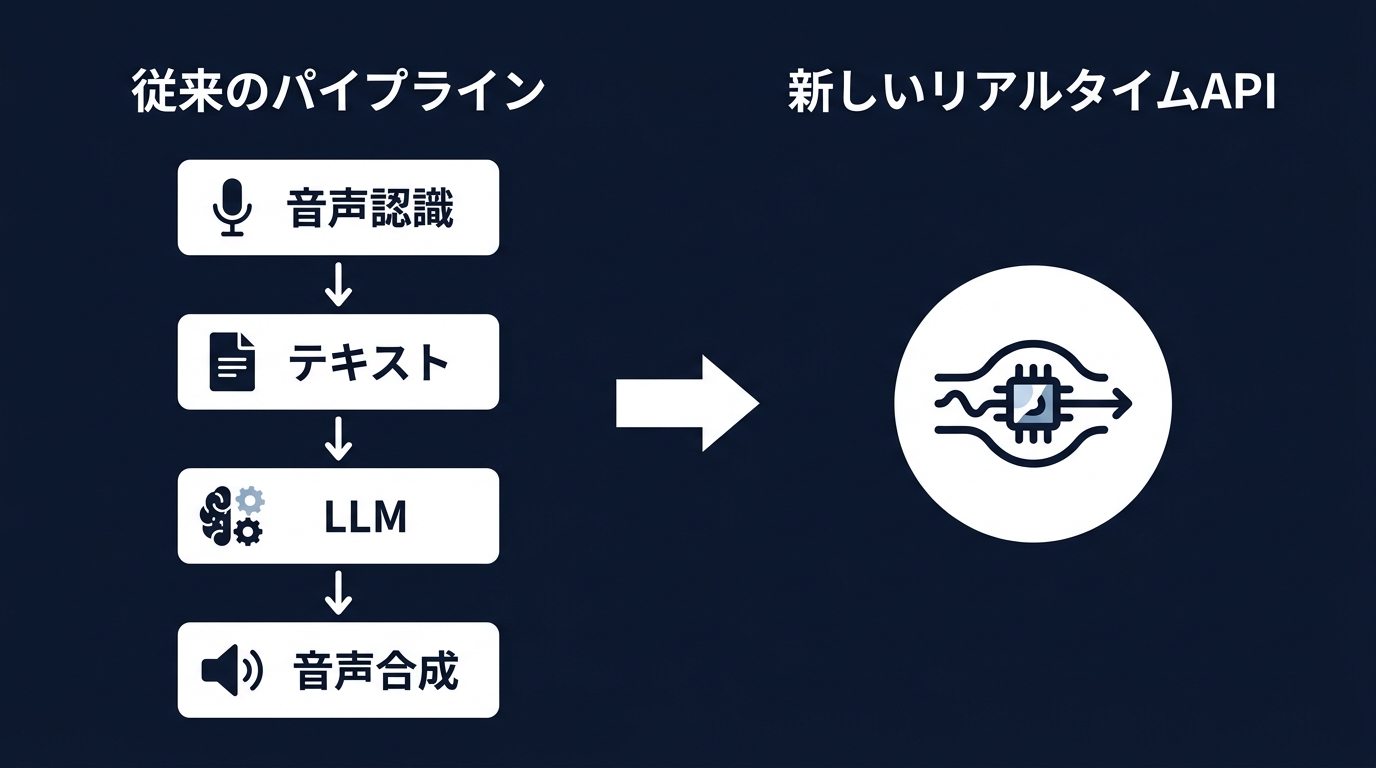
今回のリリースで衝撃を受けたのは、推論強度を5段階で制御できるようになった点だ。minimal、low、medium、high、xhighの5段階だ。
これまでの音声APIは、モデルの知能は固定だった。簡単な挨拶でも、複雑なコードのデバッグ相談でも、同じリソースを使っていた。
GPT-Realtime-2では、タスクに応じてエンジンを切り替えられる。
例えば、単純な予約受付の電話ならlow設定で十分だ。これにより低遅延と低コストを両立できる。
しかし、ユーザーが複雑な条件を出し始めたら、動的にhighやxhighへ引き上げる。
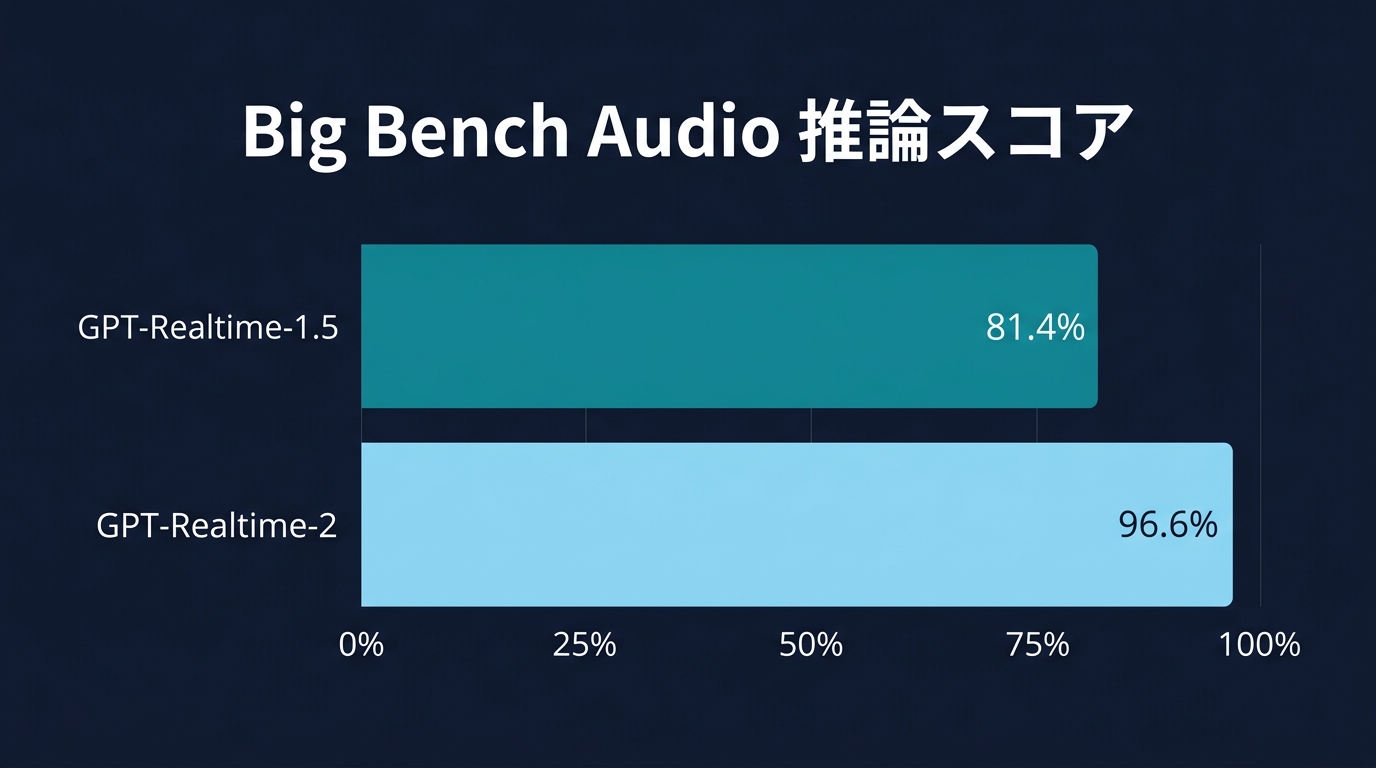
ベンチマークの結果を見ても、その差は出ている。high設定にすると、Big Bench Audioという音声推論のテストで96.6パーセントというスコアを記録した。
前モデルのGPT-Realtime-1.5が81.4パーセントだったことを考えると、進化が見て取れる。
この「推論強度の動的制御」は、プロダクトの収益性に直結する。常にフルパワーで動かせばコストが嵩む。
開発者は、APIを呼び出す際のプロンプトや状況に応じて、この強度をどうスイッチさせるかという新しい設計スキルを求められる。
また、音声のトーン制御がより細かくなった。問題解決の時は冷静に、ユーザーが困っている時は共感的に、タスクが完了した時は明るく。これをプロンプトで細かく指定できる。
もはや「声の付いたLLM」ではなく、「人格を持ったエージェント」を実装する感覚に近い。
普段使っているClaude CodeのようなCLIツールでも、いずれこうした音声推論が統合されるかもしれない。コードを書きながら「そこの関数、もっと効率的な書き方ないかな?」と聞けば、AIが「えーと、そうですね……」と考えながら最適なリファクタリング案を音声で返してくる。
推論強度の使い分けは、1人SaaS開発者にはありがたい。全部xhighで回したら破産するけど、必要な時だけブーストできるのは賢い設計だ。ThreadPostの音声エディタ機能とか、これで実装したら面白そう。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
音声アプリ構築のパラダイムシフト。今すぐ理解すべき3つのパターン
今回の発表でOpenAIは、音声AIの活用パターンを3つに定義した。これが今後の開発の標準的なフレームワークになる。
1つ目はVoice-to-Actionだ。ユーザーが声で指示を出し、AIがそれを解釈してツールを動かし、タスクを完了させるパターンだ。
2つ目はSystems-to-Voiceだ。システム側の状況変化を、AIが文脈を汲み取って音声でガイドするパターンだ。
3つ目はVoice-to-Voiceだ。これは言語の壁を超えるライブ対話だ。カスタマーサポートなどで、海外の顧客と自国のスタッフがそれぞれの言語で、違和感なくリアルタイムに会話する。
これらのパターンを実装する際、開発者は従来の「音声認識→テキスト→LLM→テキスト→音声合成」というカスケード型の設計を捨てることになる。単一のストリームの中で、全ての処理が完結するからだ。
これにより、これまで開発者を悩ませてきた「割り込み処理」の難易度が下がる。AIが話している最中にユーザーが口を挟んでも、モデル自身がそれを検知して適切に反応を中断し、新しい指示に切り替える。
ただし、注意点もある。セッション管理だ。リアルタイムAPIは接続時間が長くなりがちだ。
ユーザーが黙っている間もセッションを維持すれば、コストが積み上がる。いつ接続を切り、いつ再開するか。このステート管理の設計が、従来のテキストチャットよりも複雑になる。
割り込み処理がモデル側で完結するのは助かる。以前、自分で実装しようとしてコードがスパゲッティになった記憶がある。音声のステート管理、これは新しい開発の定石を勉強し直さないとな。
GPT-Realtime-2に関するよくある質問
Q1: GPT-Realtime-2の推論強度はどのように使い分けるべきですか?
推論強度はminimalからxhighまでの5段階で設定可能だ。デフォルトのlowは、応答速度が最優先される場面に適している。ユーザーの意図が曖昧だったり、複数のツールを組み合わせて複雑な計算や検索を行う必要がある場合は、high以上に設定する。論理的な正確性が向上する。高設定は計算リソースを多く消費するため、タスクの難易度に応じてAPI呼び出し時に動的に切り替えるロジックを組むのが、コストとUXのバランスを取るコツだ。
Q2: 従来のWhisper APIとGPT-Realtime-Whisperは何が違いますか?
決定的な違いはストリーミング性能だ。従来のWhisperは、一度録音した音声ファイルをサーバーに送って処理するバッチ型が主流だった。対してGPT-Realtime-Whisperは、ユーザーが発声している最中にリアルタイムで文字起こしを行う。これにより、AIはユーザーが話し終わるのを待たずに「次に何をすべきか」の準備を開始できる。この数秒の差が、会話のテンポを「機械的」から「人間的」に変える要因になる。
Q3: 音声モデルの利用料金はどのように計算されますか?
モデルによって課金体系が異なる。GPT-Realtime-TranslateとGPT-Realtime-Whisperは、利用時間(分単位)に基づく従量課金制だ。どれだけ長く接続していたかがコストに直結する。一方で、メイン頭脳であるGPT-Realtime-2は、テキストモデルと同様にトークン消費量(入力・出力の合計)に基づいて課金される。開発時は、無駄な長時間接続を避けるセッション管理と、適切な推論強度の選択を組み合わせることで、コストを最適化する設計が不可欠だ。
音声AIエージェントの夜明け。僕らは何を作るべきか
今回の発表で、音声は単なる「入力手段」から、「知能の出口」へと進化した。GPT-5クラスの推論が音声に乗ったことで、作れるプロダクトの幅は広がった。
キーボードを叩く暇もないほど忙しい現場。画面を見ることができない移動中。あるいは、複雑な操作を声だけで完結させたいプロフェッショナルなツール。
GPT-Realtime-2は、それら全てを可能にする。コストやセッション管理といった新しい課題はある。この低遅延と知能を一度体験してしまえば、後戻りはできない。
自分もThreadPostに、どうこの知能を組み込むか考えている。音声で投稿のアイデアを壁打ちし、AIがリアルタイムで構成を練り、推敲まで済ませてくれる。そんな「書く」という行為を音声で加速させる未来は、すぐそこだ。
音声で思考し、即座に行動するAIエージェントを、君のプロダクトに組み込む準備はできているか。今日から、音声アプリ開発の新しいルールが始まる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
