
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIの「出自」と「規律」が書き換わる日
2026年5月。AIの信頼性をめぐる戦いは新しいフェーズに入った。
OpenAIが発表した一連のアップデート。C2PAへの完全準拠とGoogleのSynthIDとの提携だ。
これらはバラバラのニュースに見えて、一つの大きな「信頼のアーキテクチャ」を形作っている。
AIが生成したコンテンツに「デジタルな刻印」を刻み、外部からの悪意ある命令を「無視」する力を実装する。
信頼性はエージェント型AIを構築する上での前提条件となった。

透明性を担保する多層防御の全貌
OpenAIはコンテンツの出自を証明する標準規格であるC2PAに自社の生成ツールを完全準拠させた。
DALL-E 3やSoraで出力される全てのコンテンツに、暗号化されたメタデータとデジタル署名が付与される。
このメタデータには、いつ、どのモデルで、どのような編集を経て生成されたかが記録される。
プラットフォーム側がこの情報を読み取ることで、ユーザーはAI生成物か否かを即座に判断できる。
改ざんが困難な「デジタル証明書」の仕組みだ。
さらに、OpenAIはGoogleのSynthIDを導入した。
SynthIDは画像や音声のピクセル、波形の中に、人間に知覚できないレベルでデジタルの「透かし」を埋め込む。
画像がトリミングや圧縮されても、この透かしは消えない。
メタデータが剥がされても、コンテンツ自体がAI製であることを主張し続ける。
一般ユーザー向けに、画像がOpenAI製かを確認できる検証ツールのプレビュー版も公開された。
情報の責任の所在を明確にするためのインフラが整いつつある。
しんたろー:
C2PAとSynthIDの二段構え。これは賢い。
メタデータはSNSにアップした瞬間に消されることも多い。
コンテンツそのものに情報を埋め込むSynthIDとの併用は安心感がある。
うちのThreadPostでも、AI生成した画像に自動でこの署名を載せる実装が気になる。
開発者目線で読み解く「命令の階層化」
今回のニュースで注目すべきは、AIモデルに命令の優先順位を教え込む仕組みだ。
AIはこれまで、システムプロンプト、開発者の設定、ユーザーの入力、外部ツールからの情報をフラットに扱いがちだった。
これがプロンプトインジェクションという脆弱性を生んでいた。
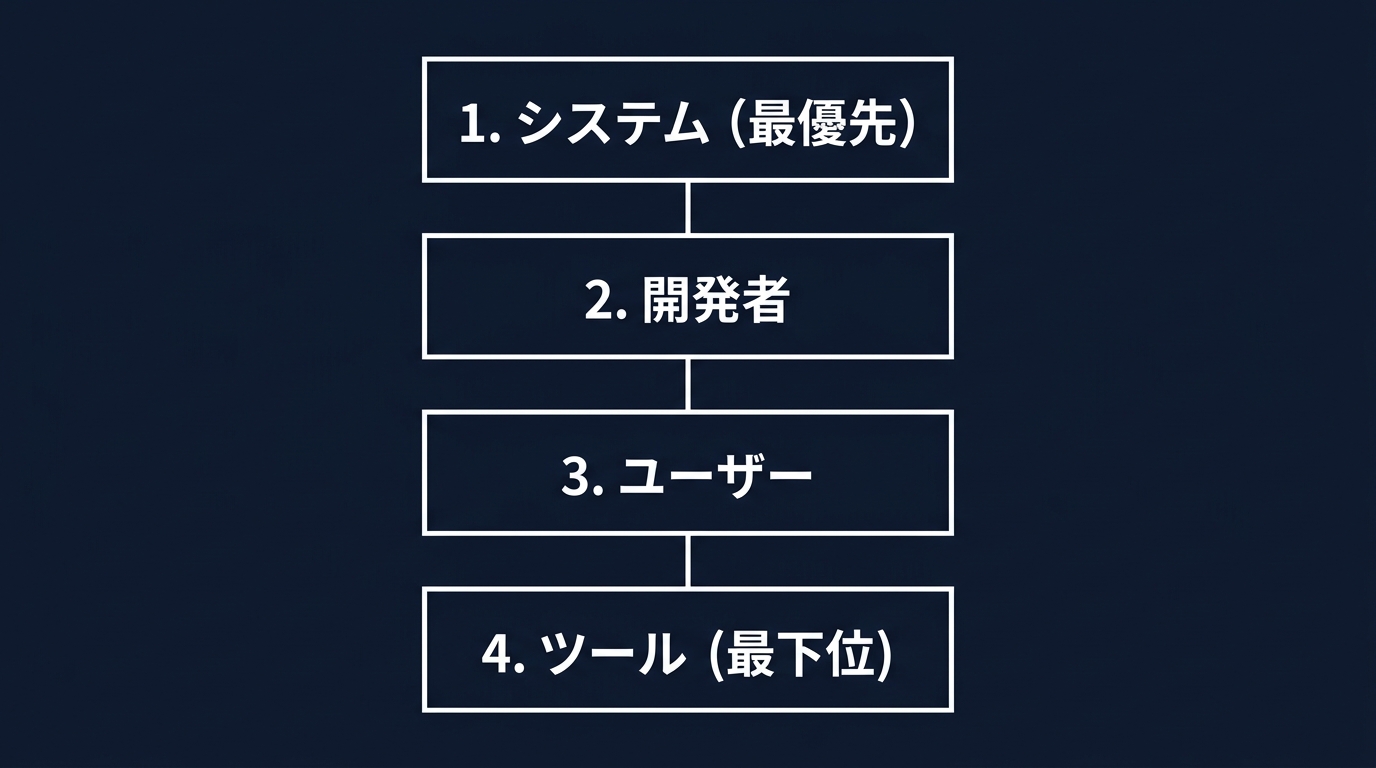
OpenAIが定義した序列は以下の通りだ。
- システム(最優先):運営側の安全規約や役割。
- 開発者:アプリ開発者が設定した動作ルール。
- ユーザー:利用者が入力したリクエスト。
- ツール(最下位):外部APIやドキュメントから取得した情報。
この序列をモデルに叩き込むことで、ツールから取得したデータ内の命令を無視する判断が可能になる。
単にプロンプトで指示するのとは次元が違う強固さだ。
Claude Codeのような自律型エージェントの開発において、この命令の階層化は重要だ。
エージェントは自分でファイルを読み、コマンドを叩き、外部と通信する。
モデル自体が外部の指示よりも開発者の指示を優先する規律を持てば、エージェントが暴走するリスクは下がる。
システム > 開発者 > ユーザー > ツール。
この優先順位をモデルが「本能」として持っているのはデカい。
今までは開発者が必死に外部入力を信じるなとプロンプトをこねくり回していた。
それがモデルの標準機能になれば、開発の工数は減り、セキュリティは上がる。
Claude Codeを使ってても、外部ライブラリの怪しいコードを実行しようとしてヒヤッとすることがあるからね。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響:僕らの開発スタックはどう変わる?
今後、自社アプリで画像を生成する場合、C2PAメタデータを正しく付与し、維持する実装が求められる。
C2PAに対応していないAIアプリは、信頼できないという空気が醸成されていく。
命令階層を意識したアーキテクチャへの移行も必要だ。
命令をどの階層に位置づけるかを明確に分離してモデルに伝える必要がある。
API側でも、システムメッセージとユーザーメッセージの区別を厳格に扱う設計が重要だ。
レッドチーミングの自動化も進む。
AIの脆弱性は開発者が予期しない組み合わせで現れる。
CI/CDパイプラインの中に、自動化されたレッドチーミングツールを組み込むのが当たり前になる。
例えば、新しい機能をデプロイするたびに、別のAIがプロンプトインジェクションを仕掛け、命令の階層が守られているかをチェックする。
動くコードを書くのと同じくらい、騙されないコードを書くことが重要視される。
レッドチーミングをCI/CDに入れるのは一昔前なら大企業の仕事だった。
今は個人開発者でもツールを使えば自動で回せる。
僕もThreadPostの開発で、ユーザーが入力したSNS投稿案に怪しい命令が混ざってないか監視する仕組みを考えてる。
AIにAIを監視させるエコシステムを組めるかどうかが、プロの開発者の分かれ道になりそう。
FAQ:AIの信頼性向上に関する疑問に答える
Q1: C2PAとSynthIDはどちらを導入すべきですか?
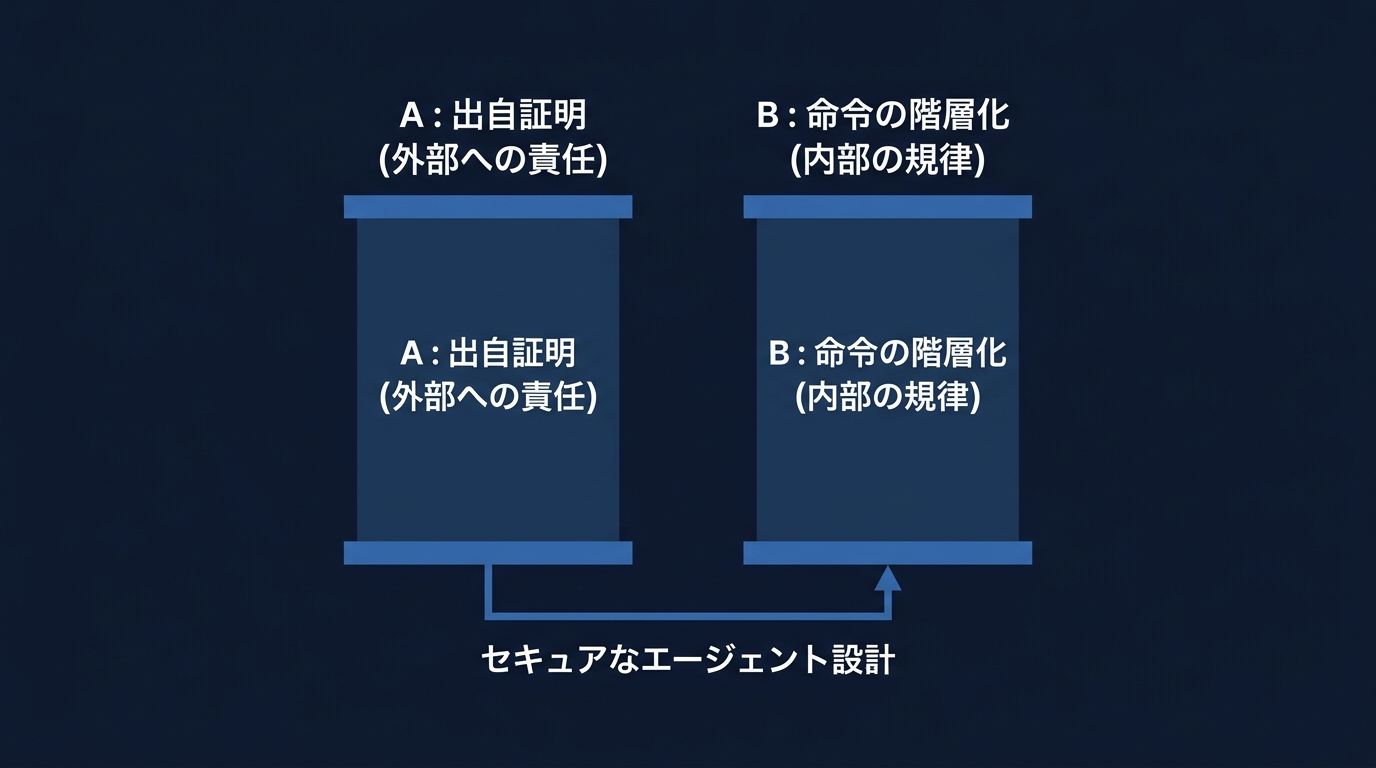
A1: 両方の併用が現在のベストプラクティスだ。
C2PAは説明責任を果たすためのメタデータであり、情報の透明性を担保する。
しかし、スクリーンショットやトリミングで容易に削除される弱点がある。
一方、SynthIDはコンテンツ自体に不可視の信号を埋め込むため、物理的な加工に対しても耐性がある。
メタデータで誰が作ったかを示し、透かしでAI製であることを保証する。
Q2: 命令の優先順位はどう実装すればいいですか?
A2: 単にプロンプトで指示を書くだけでは不十分だ。
APIを利用する際に、システムプロンプトの枠組みを固定し、ユーザー入力を完全に分離して流し込む中間層を設ける設計が有効だ。
ツール実行結果をパースする際も、その内容を直接モデルに命令として解釈させず、一度システム側の検証ロジックを通すガードレールを実装する。
Q3: レッドチーミングはどの段階で実施すべきですか?
A3: 設計段階から継続的に行うべきだ。
開発の最後に一回だけテストするのでは、根本的な設計ミスに気づけない。
特にエージェントが外部APIやドキュメントを読み込む場合、脆弱性は予期せぬタイミングで現れる。
自動化されたレッドチーミングツールを開発フローに組み込み、コードが変更されるたびに継続的にスキャンを実行する。
信頼という名の最強の機能
AI開発の主戦場は性能から信頼へ移った。
どれだけ賢い回答ができるかよりも、どれだけ安全に、意図通りに動くかが重要だ。
それが開発者がユーザーから選ばれるための武器になる。
C2PAによる出自の証明と、階層化された命令による強固なセキュリティ。
これらを自分の開発スタックにどう組み込むかを考えることが、次世代のAIアプリケーションを作る第一歩だ。
僕もClaude Codeと一緒に、もっと安全で、もっと信頼されるプロダクトを作っていく。
信頼性は地味だが、一番強い機能だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
