
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
APIの請求書を見るたびにため息をついていた話
月額のAPI課金を計算するたびに、「このコスト、なんとかならんのか」と思っていた。
OCRだけで数千円。画像処理が増えるたびに青くなる。
そこに、国立国会図書館がとんでもないものを無料公開した。GPU不要・CPU動作・日本語高精度のOCRツール「NDLOCR-Lite」だ。同じタイミングで、Microsoftが1-bit LLM「BitNet」の推論フレームワークをOSSで公開し、VSCodeのCopilotがエージェントアーキテクチャの設計を外部に晒した。
3つのニュースが同時に起きている。

何が起きているのか、全部まとめる
NDLOCR-Lite:国会図書館発、無料OCRの衝撃
2026年2月24日、国立国会図書館のNDLラボが「NDLOCR-Lite」を公開した。
もともとNDLには「NDLOCR」という高精度OCRがあった。ただしGPU必須でサーバー向け。個人開発者が気軽に使えるものではなかった。
NDLOCR-Liteはその軽量版だ。一般的なノートPCのCPUだけで動く。GPUは要らない。Pythonさえ入っていれば動く。GUIアプリ版ならPythonも不要だ。
インストールは3通り。
- gitでクローン → pip install → src/から実行
- uvでインストール → システムコマンドとして使える(推奨)
- GUIアプリ版 → GitHubのReleasesからダウンロード、ドラッグ&ドロップで動く
使い方はシンプルだ。画像ファイルを渡せばテキストが返ってくる。PDFも複数ページ対応している。出力先のファイル指定もできる。
日本語OCRの選択肢と比較するとこうなる。
- Google Cloud Vision: 精度は最高クラス。でも従量課金。個人開発では「課金が怖くて気軽に使えない」
- Tesseract: 無料。ただし日本語精度が厳しい。フォントや画質によっては壊滅的
- NDLOCR(重量版): 精度は文句なし。GPU必須でノートPCでは動かない
- NDLOCR-Lite: 無料 × GPU不要 × 日本語高精度
この組み合わせ、今まで存在しなかった。
しんたろー:
「国会図書館がこんなもの出すのか」と思った。
「無料 × GPU不要 × 日本語高精度」の三角形が今まで空白地帯だったわけで、そこをまさか公的機関が埋めてくるとは。うちのThreadPost、画像処理のコストが地味に気になってたから、これは真剣に組み込みを検討したい。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
BitNet:1-bit LLMが「普通のPC」を変える
同じ流れで、Microsoftが「BitNet」の推論フレームワークをOSSとして公開した。
LLMの重みは通常、32bitや16bitの浮動小数点数で表現される。GPT-4クラスのモデルなら、この数値が数百億個存在する。だからVRAMが爆発する。だからGPUが要る。
BitNetのアプローチは極端だ。重みを-1、0、1の3値のみで表現する(厳密には1.58bit)。
「そんなザックリな数字で賢いAIが動くの?」という疑問は正しい。実験結果では、7Bパラメータのモデルで性能を維持しながらメモリ削減と推論速度向上を両立しているという。
仕組みとしては、学習中は通常の浮動小数点で計算しつつ、推論時の重みだけを1-bit化する。そのズレを学習でカバーする設計だ。
BitNetが成熟すると何が起きるか。普通のラップトップでそれなりに賢いAIが動く。llamaやollamaでもローカルLLMは動くが、重くて遅い。BitNetが普及すれば、その制約が大幅に緩和される可能性がある。
VSCode Copilotのplanモード:エージェント設計の「答え」が公開された
3つ目のニュースは、ある意味一番実用的だ。
VSCodeのCopilotとCopilot CLI、同じ名前でも内部のアーキテクチャが全然違う。その差が明らかになった。
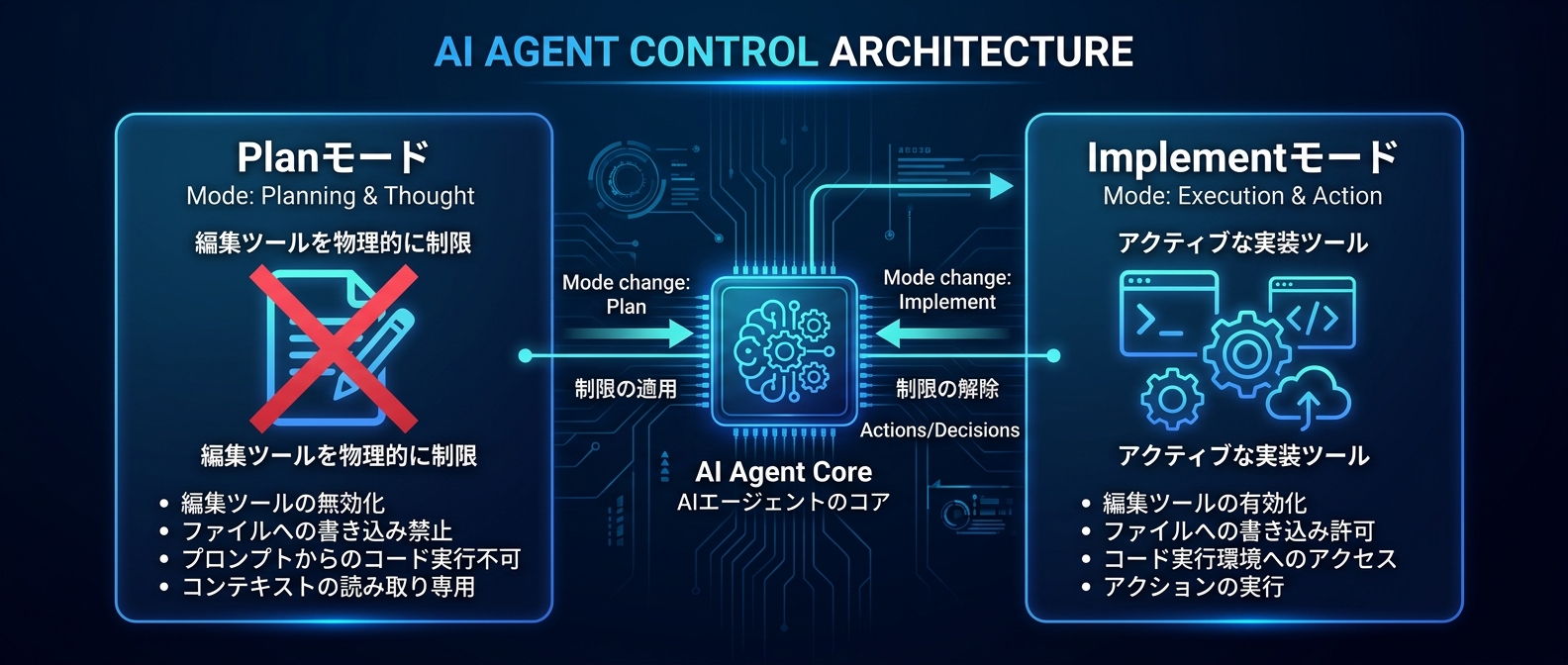
特にplanモードの設計が面白い。VSCodeでは「PLANNING AGENT」という計画立案専用のエージェントが別途存在する。システムプロンプトの冒頭で「あなたはPLANNING AGENTとして、ユーザーと協力して詳細で実行可能な計画を作成します」と明示されている。
そして決定的な違いがここだ。VSCodeのplanモード中、エージェントにはファイル編集ツールが渡されていない。物理的に制限されている。「うっかり実装し始める」という事態が構造的に起きない設計だ。
CLIはプロンプトで「実装しないでね」と指示するだけ。ツールは全部渡している。つまりやろうと思えば実装できる。
開発者として「だから何?」を考える
ローカルAIへの回帰が加速している
NDLOCR-LiteとBitNetを並べると、同じ方向性が見える。クラウドの巨大モデルへの依存から、ローカル・エッジで実用的に動く軽量モデルへの回帰だ。
個人開発者にとって、これは何を意味するか。
API課金の構造から解放される可能性がある。OCRをGoogle Cloud Visionに依存していたなら、NDLOCR-Liteで代替できる。LLMをOpenAIに依存していたなら、BitNetが成熟すればローカルで動かせる未来が来る。
ただし、これは「今すぐ全部置き換えられる」話ではない。
NDLOCR-Liteの制限は正直に書く。走り書きの手書きは厳しい。数百ページの大量バッチ処理には向かない。REST APIは自前で作る必要がある。
BitNetも現時点ではC++のビルドが必要で、対応モデルが限られている。「pip installで動く」レベルにはまだ達していない。
使いどころを選ぶ必要がある。選択肢が増えたという事実は大きい。
エージェント設計の「安全な制御」が見えてきた
VSCodeのCopilotが晒したアーキテクチャは、自作エージェントを作るすべての開発者にとって参考になる。
ポイントは「プロンプトで指示するだけでなく、物理的にツールを制限する」という設計思想だ。
VSCodeのplanモードには3つの特徴がある。
- 計画立案フェーズでファイル編集ツールを物理的に渡さない → 暴走が構造的に起きない
- ワークフローを4フェーズで定義 → Discovery → Alignment → Design → Refinement
- 計画ドキュメントの書き方まで指定する「plan_style_guide」が存在する → 計画の質を制御
特に3番目が面白い。「計画を立てさせる」だけでなく、「どんな計画を立てるか」まで制御しようとしている。
Claude Codeで自律的なコーディングをしていると、「意図しないファイルが書き換えられた」という経験は誰でもある。プロンプトで「このファイルは触るな」と書いても、エージェントは時々無視する。
VSCodeの設計を見ると、プロンプトによる指示ではなく、ツールの物理的な非渡しが根本的な解決策だとわかる。
Claude Codeで開発してると、エージェントが「あ、ここも直したほうがいいですよね」って勝手に別ファイル触り始めることがある。
VSCodeのplanモード設計を見て「なるほどそういうことか」となった。ツールを渡さないという物理的な制限、自作のエージェント設計にそのまま使える発想だ。planフェーズとimplementフェーズを明示的に分けて、planフェーズでは編集系のツールを渡さない。この設計パターン、頭に入れておきたい。
2つのアプローチが並行して成熟している
AIの課題解決に向けて、現在2つの方向性が同時進行している。
方向性A: モデル自体を軽量化してローカルで動かす
→ NDLOCR-Lite、BitNet。クラウド依存を減らす。コスト構造が変わる。
方向性B: クラウドの強力なモデルをシステム側で厳格に制御する
→ VSCodeのCopilotアーキテクチャ。ツール権限の物理的制限。エージェントの安全な制御。
この2つは矛盾しない。むしろ補完関係にある。
軽量モデルをローカルで動かすなら、そのエージェントをどう安全に制御するかという問題が必ず出てくる。方向性Aが進むほど、方向性Bの設計思想が重要になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響:今すぐ知っておくべきこと
OCR周りのコスト見直しができるタイミング
NDLOCR-Liteが使えるシナリオを具体的に整理する。
- 領収書・書類のテキスト化: 紙のスキャン → OCR → データベース登録。確定申告系のアプリや経費管理ツールで直接使える
- ホワイトボード・手帳の写真からテキスト抽出: カメラ撮影 → OCR → タスク管理アプリ連携
- モバイルアプリのバックエンド: カメラで撮影 → サーバーに送信 → NDLOCR-Lite実行 → テキスト返却。Google Cloud Visionの従量課金から解放できる
- 技術書・ドキュメントのデジタル化: スキャンPDF → テキスト抽出 → 検索可能なデータベース構築
ただし、NDLOCR-Lite自体にはREST APIがない。Webアプリに組み込む場合は自前でラッパーを書く必要がある。FastAPIで自前のAPIサーバーを立てるのが現実的な実装パターンだ。
走り書きの手書きはGoogle Cloud Visionのほうが精度が高い。用途によって使い分けが必要だ。
エージェント設計に取り入れるべきパターン
自作のAIエージェントを開発しているなら、VSCodeのplanモード設計から学べることがある。
- planフェーズとimplementフェーズを明示的に分ける: 同じエージェントに両方やらせない
- planフェーズでは編集系ツールを渡さない: プロンプトでの指示ではなく物理的な制限
- 計画の優先度を明示する: 「このモードの指示は上記のすべての指示より優先される」という宣言
- 計画ドキュメントのフォーマットを固定する: 何を書くかではなく、どう書くかまで制御する
Claude Codeを使った開発でも、「計画フェーズ」と「実装フェーズ」を意識的に分けてプロンプトを設計することで、意図しないファイル変更を減らせる。
BitNetは「今すぐ使う」より「動向を追う」フェーズ
BitNetは現時点では実用段階に達していない。C++のビルドが必要で、対応モデルが限られている。個人開発に組み込むには早い。
ただし、Microsoftが公式の推論フレームワークをOSS化したという事実は重要だ。研究レベルの話が実用段階に入ってきたサインとして読む。
「pip installで動くようになったタイミング」が、ローカルLLMのコスト構造を根本から変える転換点になる。そのタイミングを見逃さないために、今から技術の動向を把握しておく価値がある。
BitNetは正直まだ「様子見」だけど、NDLOCR-Liteは今すぐ使えるレベルだと思う。
「無料 × GPU不要 × 日本語高精度」がこのタイミングで揃ったのは、個人開発者にとってタイミングが良すぎる。OCR周りのAPI課金が気になっている人は、まずGUIアプリ版で精度を確認してみるのが一番早い。
よくある質問
Q1. NDLOCR-Liteを自分のWebアプリに組み込むにはどうすればいいですか?
NDLOCR-Lite自体にはREST APIが用意されていない。そのため、Webアプリに組み込む場合は2つのアプローチがある。
1つ目は、PythonのサブプロセスでCLIコマンドを呼び出すラッパーを自作する方法。シンプルだが、プロセス起動のオーバーヘッドがある。
2つ目は、ソースコードの「ocr.py」を直接インポートして、FastAPIなどで自前のAPIサーバーを構築する方法。これにより完全無料のOCR APIエンドポイントを持てる。サーバーのセットアップコストはかかるが、Google Cloud Visionの従量課金から完全に解放される。モバイルアプリのバックエンドとして使うなら、画像をサーバーに送信 → NDLOCR-Lite実行 → テキスト返却、という構成が現実的だ。
Q2. 1-bit LLM(BitNet)は今すぐローカルPCで簡単に試せますか?
現時点では「簡単に」とは言い難い。Microsoftが公式の推論フレームワークをOSS化しているが、環境構築にC++のビルドが必要で、対応モデルも限られている。
技術的な背景を理解しておくと動向が追いやすい。BitNetは学習中は通常の浮動小数点で計算し、推論時の重みだけを-1・0・1の3値に量子化する。このアプローチにより、メモリ使用量と推論速度を大幅に改善できる。
将来的には「pip install」で動くようになることが期待されている。そのタイミングが、ローカルLLMの実用性が一段階上がる転換点になる。今は技術の動向を把握しておく段階で、実際のプロダクション投入はもう少し先の話だ。
Q3. 自作のAIエージェントが勝手にコードを書き換えてしまうのを防ぐには?
VSCodeのCopilotが採用しているplanモードの設計が直接的な答えになる。
最も重要なのは「プロンプトで指示するのではなく、ツールを物理的に渡さない」という設計思想だ。計画立案フェーズでは、ファイル編集ツール(edit等)をエージェントに渡さない。渡すのは計画を保存するための「memoryツール」のみ。これにより、プロンプトで何を書こうと、エージェントはファイルを編集できない。
加えて、planフェーズとimplementフェーズを別のエージェントとして分離する設計も効果的だ。同一エージェントに「計画も実装も」やらせると、フェーズの境界が曖昧になる。役割を物理的に分けることで、意図しない暴走を構造的に防げる。Claude Codeを使った開発でも、このフェーズ分離の発想はそのまま応用できる。
まとめ
無料 × GPU不要 × 日本語高精度が揃った。
国会図書館が個人開発者のOCRコストを解決して、MicrosoftがローカルLLMの未来を示して、VSCodeがエージェント設計の答えを晒した。3つが同じタイミングで動いている。
「クラウドAPIに課金し続けるしかない」という前提が、静かに崩れ始めている。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
