
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIが「審判」から「立法者」へ変わる
MetaはAI活用の舵を切った。
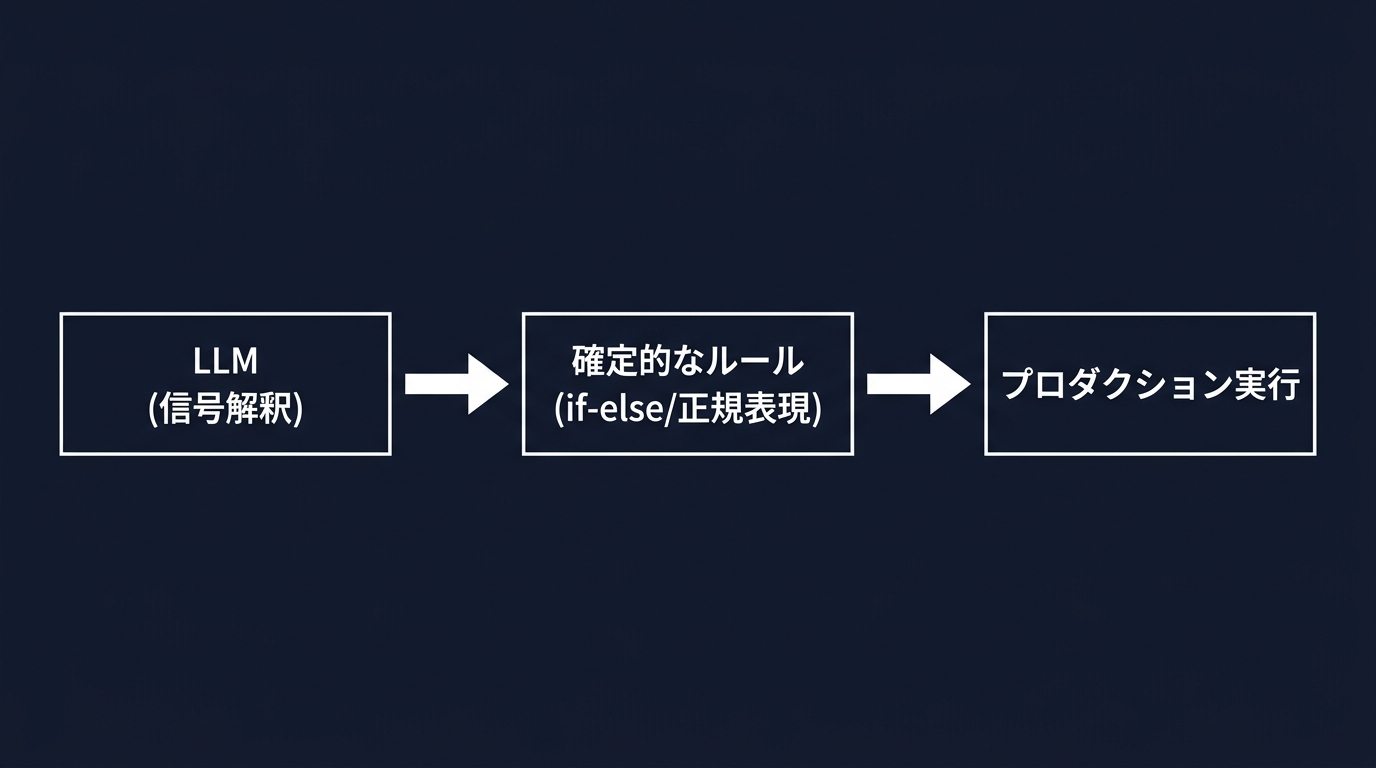
LLMに直接判断を任せず、LLMに「確定的ルール」を書かせる。
判断の精度は人間より13%向上し、違反検出率は10%上がった。
このパラダイムシフトは開発者の設計思想を変える。
「AIが答える」から「AIがロジックを生成し、人間がそれを運用する」へ。
この自動化への道筋は、制御の再獲得だ。

膨大なデータ資産をLLMと確定的なルールで統治するMetaの戦略
Metaのインフラでは、天文学的な数のデータ資産が生まれている。
テーブル、カラム、ログのキー、APIのフィールド、機械学習の特徴量。
これら全てに、適切なプライバシー保護のルールを適用する。
例えば「age」というフィールド名がある。
ある文脈では「ユーザーの年齢」であり、厳重な保護が必要だ。
別の文脈では、単なる「キャッシュの有効期限(TTL)」に過ぎない。
これを人間が手作業で分類するのは物理的に不可能だ。
Metaは、プライバシー保護インフラ(PAI)にAIを組み込んだ。
LLMをそのままプロダクションの判定ラインに立たせることはしない。
彼らが採用したのは、ハイブリッドなパターンだ。
ノイズの多い信号をLLMに解釈させ、そこから確定的なルールを抽出する。
そのルールを人間がレビューし、バージョン管理されたコードとしてデプロイする。
このプロセスの核心は、LLMの役割を「実行」ではなく「蒸留」に限定したことにある。
プロダクション環境で動くのは、低遅延で監査可能なif-else文や正規表現だ。
AIの推論能力を活かしつつ、システムの予測可能性を担保する。
コンテンツモデレーションの現場では変化が起きている。
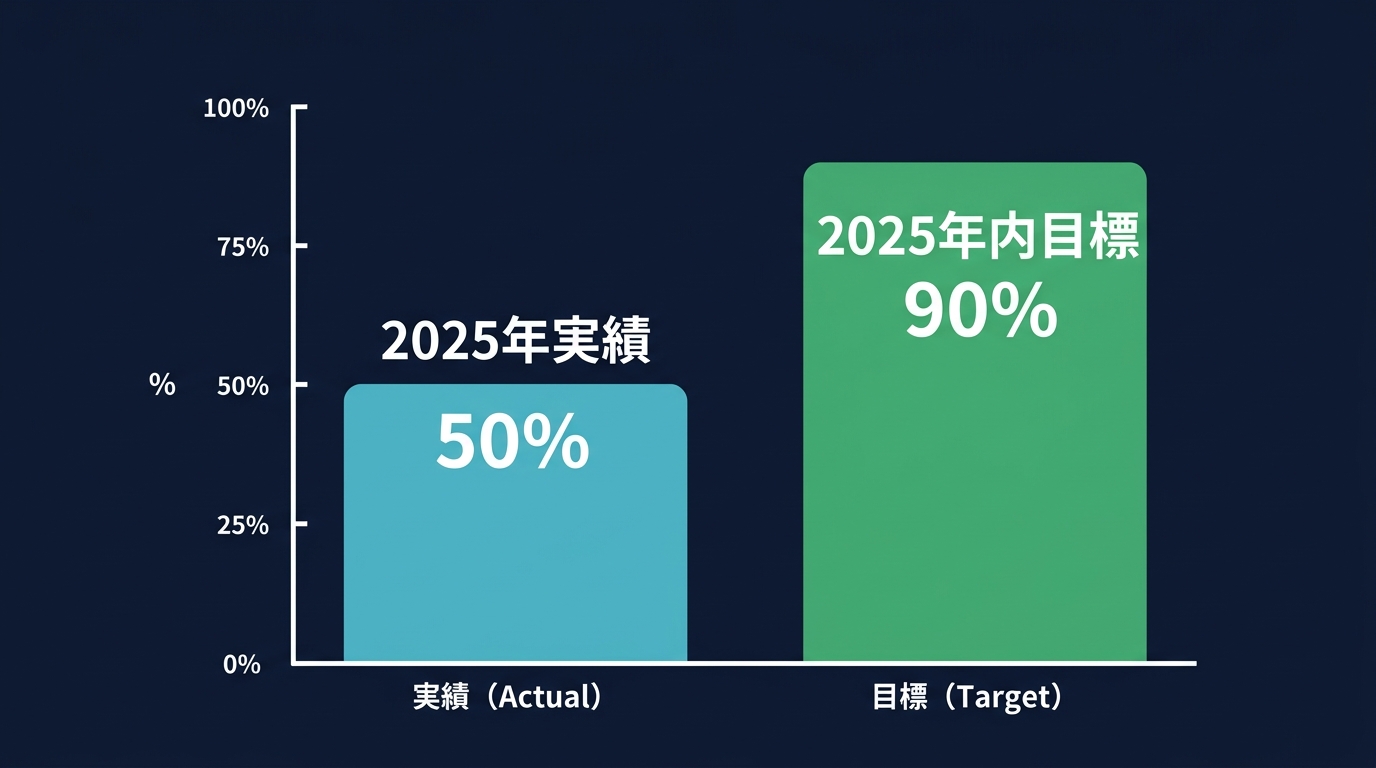
2025年、Metaは人間による審査リクエストの約50%をLLMに置き換えた。
年内には、特定のコンテンツタイプでこの割合を90%以上に引き上げる計画だ。
この移行により、年間数十億ドルのコスト削減が見込まれている。
Metaはコストよりも「品質」を強調し、人間よりエラーが少ないと報告する。
自社開発の「Muse Spark」というモデルへ移行し、GoogleのGeminiからの脱却も進めている。
現場の従業員からは懸念の声も上がっている。
適切なコンテンツが誤って削除されたり、シャドウバンされたりする事例だ。
急速な自動化に対し、監視体制が追いついていないという内部指摘もある。
Metaは、エージェント型AIの野望を加速させるために「Dreamer」チームを吸収した。
Dreamerは、日常の言葉で誰でもAIエージェントを作れるようにするスタートアップだ。
2024年末に5億ドルの評価額で5,600万ドルを調達した。
Metaのビジョンは明確だ。
「数十億人が、自分のニーズに合ったソフトウェアを自ら構築できる世界」を作る。
インフラの自動化と、ユーザーによるエージェント構築。この両輪がMetaのAI戦略だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、
海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者がLLMを「ルール生成エンジン」として扱う理由
Metaの事例から学ぶべきは、LLMの使い所だ。
プロダクションのど真ん中にLLMを置くと、コスト、遅延、そして不確実性が生じる。
プライバシーやセキュリティが絡む領域では、その「揺らぎ」が致命傷になる。
Metaの「ハイブリッド・パターン」は、この問題を解決している。
LLMは、曖昧でノイズの多いデータから「意味」を汲み取るのが得意だ。
その「意味」を、人間が理解できる決定論的なロジックに変換させる。
これは、僕がClaude Codeを使って開発している時の感覚に近い。
Claudeに直接ユーザーのデータを処理させるのではなく、処理するための「堅牢な関数」を書かせる。
人間はその関数が正しいかを確認し、テストを通し、プロダクションへ流す。
この設計にすると、不具合が起きた時のデバッグが楽になる。
「AIがなぜそう判断したか」をブラックボックスの中で探る必要はない。
生成されたコードやルールを読めば、そこに全てのロジックが書いてあるからだ。
この手法は「スケーラビリティ」の面でも有利だ。
LLMを毎回呼び出すコストは高いが、一度生成したルールを実行するコストはほぼゼロだ。
Metaのような巨大インフラで、全ての判定にLLMを使っていたら破産する。
開発者として意識すべきは、LLMを「コンパイラ」や「トランスパイラ」として捉える視点だ。
自然言語のポリシーや曖昧なデータ構造を、厳格なコードへコンパイルさせる。
このパイプラインを構築できるかどうかが、AIネイティブ時代のエンジニアの腕の見せ所だ。
僕のThreadPost開発でも、投稿のカテゴライズやフィルタリングにこの考えを入れている。
LLMに毎回「この投稿はスパムか?」と聞くのは効率が悪い。
LLMに「今回のスパムの傾向を分析して、判定用の正規表現リストを更新しろ」と命じる。
実行時のパフォーマンスを犠牲にせず、AIの知能をシステムに組み込める。
Metaが「LLM everywhere(どこでもLLM)」を目指していない、と明言しているのは興味深い。
彼らが求めているのは、あくまで「制御可能な自動化」だ。
しんたろー:
Metaのこの「ルールに落とし込む」執念、エンジニアリングの鑑だ。
LLMの推論結果をそのままAPIで返すのは楽だけど、運用で死ぬ。
Claude Codeに「この条件で動く堅牢なバリデーションロジックを書いて」と頼むのが、一番速くて安全だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務に即導入できる「AIによるガバナンス自動化」のステップ
開発にこのMeta流の戦略を取り入れる。
ポイントは、AIの判断を「直接実行」させないための中間レイヤーの設計だ。
以下の3つのフェーズでパイプラインを構築する。
1つ目は、シグナルの収集と解釈だ。
生のデータ、メタデータ、過去の判定結果など、あらゆる「曖昧な信号」をLLMに渡す。
ここでLLMは、人間が気づかないようなパターンや文脈を特定する。
2つ目は、ルールの蒸留と生成だ。
特定されたパターンを、if-else、正規表現、あるいは特定のポリシー記述言語に変換する。
ルールには必ず「なぜこのルールが生成されたか」の根拠をコメントとして含ませる。
3つ目は、人間によるレビューとデプロイだ。
生成されたルールを管理画面やGitのプルリクエスト形式で人間が確認する。
承認されたルールだけが、プロダクションの判定エンジンに反映される仕組みだ。
この流れを作ることで、AIの「高速な学習」とシステムの「高い信頼性」を両立できる。
データ構造が頻繁に変わるスタートアップの開発において、このアプローチは強力だ。
手動でバリデーションを書き直す手間を省きつつ、AIの暴走を防ぐことができる。
モデレーションの自動化を検討しているなら、Metaの「Muse Spark」への移行も示唆に富む。
外部の汎用モデルに依存せず、自社のドメイン知識に特化した軽量モデルを運用する。
コストを抑えつつ、自社サービス固有のニュアンスを理解させることが可能になる。
Dreamerのようなエージェント技術の統合も見逃せない。
「自然言語でソフトウェアを作る」という流れは、開発者にとって武器だ。
定型的なロジック構築をAIに任せ、システム全体のアーキテクチャと「何を作るか」に集中できる。
Metaの戦略を模倣するなら、まずは「AIに判断を任せている箇所」をリストアップすることだ。
ルール化して切り出せる部分はないか、監査が必要な箇所はどこか。
そこをハイブリッド構造に変えるだけで、プロダクトの安定性は良くなる。
今すぐ全てのLLM呼び出しをルール生成に変える必要はない。
プロダクションの核心部分には「確定的なロジック」を置く。
この原則を守るだけで、AIネイティブ時代のインフラ構築で迷うことはなくなる。
プロダクションでLLMが「ごめん、今の分かんなかったわ」って返すのは、ユーザーからしたら最悪だ。
確定的なルールなら、挙動が安定する。
この「AIを立法者にする」設計、うちのThreadPostの自動投稿フィルターにも応用してみる。
MetaのAI戦略と実装に関するFAQ
Q1: LLMを直接プロダクションで使わず、ルールに変換するメリットは何ですか?
最大のメリットは監査可能性と低遅延だ。
LLMは確率的で推論コストが高く、挙動の予測が困難だが、一度確定的なルールに落とし込めば、実行速度が向上する。
誰が、なぜその判断を下したかをログやコード上で完全に追跡可能になる。
特にプライバシーやセキュリティに関わる領域では、この説明責任が不可欠だ。
Q2: なぜMetaはモデレーションでLLMの利用を急いでいるのですか?
コスト削減と精度の向上の両面が理由だ。
人間によるモデレーションは膨大なコストがかかり、言語の壁やニュアンスの理解に限界がある。
Metaのテストでは、LLMの方が人間よりもエラー率が13%低く、違反検出率が10%高いという結果が出ている。
急激な移行による誤判定が現場の課題となっており、技術と運用のバランスが問われている。
Q3: 開発者がこのMetaの手法を学ぶために、まず何をすべきですか?
LLMに「コード」や「設定ファイル」を出力させる練習から始める。
単なる回答を求めるのではなく、「この条件を満たすJSONを生成して」や「このパターンを検知する正規表現を書いて」と命じる。
その出力をプログラムでパースして実行するパイプラインを作ってみることだ。
これが、Metaが実践している「AIによる自動化」の最小単位の練習になる。
結局「AIに何をさせるか」の解像度の差だ。
MetaはAIを「魔法の箱」ではなく「高度なコード生成器」として見ている。
この視点の切り替えだけで、エンジニアとしての価値が変わる。
AIを制御下に置く勇気が、真の自動化を生む
Metaの戦略は、AIへの過度な依存からの脱却であり、AIの力を最大化する選択だ。
LLMに直接ハンドルを握らせるのではなく、LLMに道路標識(ルール)を書かせる。
その標識に従って、確実なシステムが走り続ける。
個人開発者や小さなチームこそ、この「ルール生成エンジンとしてのAI」を使い倒すべきだ。
1人でSaaSを作るなら、全ての判断を自分でやるのは無理がある。
かといって、AIに丸投げして信頼性を失うわけにもいかない。
Metaが示したこのハイブリッドな道は、北極星になる。
AIにロジックを書かせ、人間がその意図を承認し、確実なコードとして動かす。
このサイクルを回すことが、AIネイティブ時代の開発の正解だ。
あなたのプロダクトの「ブラックボックス」を、AIにルール化させる。
それが、スケールしても壊れない、強靭なシステムへの第一歩になる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
