
2026年現在、ローカルLLM環境の構築は一部の専門家だけのものではなくなった。
誰もが自分のPCで強力なAIを動かせる環境が整いつつある。
でも、RTX 4080のような強力なGPUを用意しても、VRAMの壁にぶつかって挫折する人は後を絶たない。
この記事では、僕が1人SaaS開発の現場でリサーチして得た、ローカルLLMとAIエージェント構築の最適化テクニックをまとめた。
この記事でわかること
- LangChainを使わないRAGの構築アプローチ
- 日本語ドキュメントの最適なチャンクサイズ
- MoEモデルのVRAM要件の正しい見積もり方
- コンテキストサイズ縮小による速度向上テクニック
- Dockerを使ったAIエージェントの安全な運用方法
結論から言うと、ハードウェアの限界はソフトウェアの工夫と設定の最適化で十分にカバーできる。
「結局どう設定すれば快適に動くのか」と悩んでいる人は、今日から使える11のTipsを厳選したので、環境構築の参考にするといい。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
1. RAG構築の基本と最適化
Tips 1: LangChainを使わず素のPythonで実装する
RAGの仕組みを根底から理解するには、あえてLangChainなどの便利すぎるフレームワークを外すのがおすすめだ。
高度に抽象化されたツールを使うと、裏側で何が起きているのか見えなくなり、エラー時の原因究明が非常に難しくなる。
実は、Pythonの標準機能とOllama、そしてChromaDBのような軽量なベクトルDBを組み合わせるだけで、150行程度のコードで完全なローカルRAGが実装できる。
素のPythonで実装するメリット
- 処理の透明性が完全に確保できる
- エラーの原因究明が圧倒的に簡単になる
- 依存ライブラリを最小限に抑えられる
テキストの読み込みからチャンク分割、ベクトル化、そして検索と回答生成までの全プロセスを自分の目で確認できるのは大きなメリットだ。
ブラックボックス化を防げるので、トラブルシューティングが楽になり、結果的に開発スピードも上がるはずだ。
シンプルな構成を維持することは、長期的なメンテナンス性の向上にも直結する。
Tips 2: 日本語のチャンクサイズは500文字を基準にする
RAGの検索精度を左右する最大の要因が、ドキュメントを分割する際のチャンクサイズだ。
海外のチュートリアルでは800から1000トークンが推奨されることが多いが、これはあくまで英語を前提とした数字だ。
日本語は漢字やひらがなが組み合わさっており、英語に比べて1文字あたりの情報量が圧倒的に多い。
そのため、日本語の技術文書や社内マニュアルを扱う場合は、400文字から600文字、つまり500文字前後を基準にするのがスイートスポットになる。
これより短すぎると重要な文脈が途切れ、長すぎると無関係なノイズが混じって検索精度が劇的に落ちてしまう。
まずは500文字で分割し、そこからドキュメントの性質に合わせて微調整していくといい。
適切なサイズを見つけることが、実用的なRAG構築の第一歩になる。
Tips 3: チャンクの先頭に記事タイトルを付与する
ドキュメントをチャンクに分割する際、ちょっとした工夫で検索精度を飛躍的に高めることができる。
それが、各チャンクの先頭に元の記事タイトルをテキストとして直接埋め込むというテクニックだ。
たとえば「設定画面を開いてボタンを押す」というチャンクだけでは、どのツールの設定なのかAIには全く分からない。
しかし、先頭に「社内システムAの初期設定」というタイトルがあれば、ベクトル検索やキーワード検索の際に文脈が完全に補完される。
メタデータとして裏側に隠すだけでなく、検索対象のテキストそのものに含めるのが最大のポイントだ。
実装も数行のコードを追加するだけで済むので、費用対効果が非常に高い施策と言える。
この一手間で、AIの回答精度が目に見えて向上するはずだ。
2. VRAMとハードウェアの限界突破
Tips 4: MoEモデルのVRAMは「総パラメータ数」で見積もる
最近流行りのMoEモデルを使う際、多くの人が陥る罠がある。
それが「アクティブパラメータ数が小さいから、少ないVRAMでも動くはずだ」という勘違いだ。
MoEモデルのアクティブパラメータ数は、あくまで1回の推論で使用される計算量を示す指標であり、メモリ要件とは全く関係がない。
推論を実行するには、その時点で使われない待機中の部分も含めて、モデル全体をVRAMにロードする必要がある。
つまり、35BのMoEモデルを動かすなら、結局35Bの通常モデルと同等のVRAM容量が必須になるというわけだ。
カタログスペックの数字に騙されず、総パラメータ数を基準にしてハードウェアを用意しよう。
正しい見積もりが、快適なローカルLLM環境の土台になる。
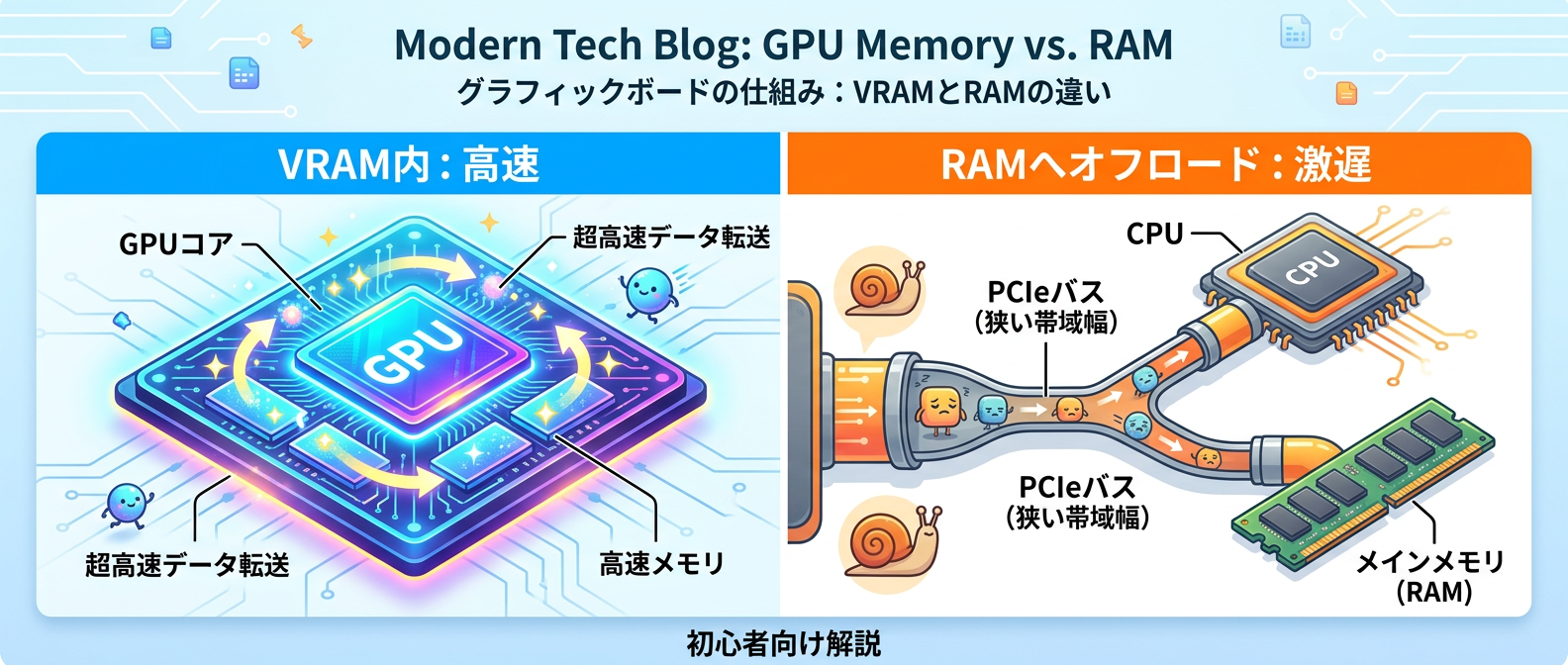
Tips 5: 極端な速度低下はPCIeバス帯域を疑う
ローカルでLLMを動かしていて、推論速度が1秒間に1から2トークンレベルまで極端に落ち込む現象に遭遇することがあるはずだ。
これは、モデルのサイズがVRAMに収まりきらず、システムRAMにオフロードされた時に発生する典型的な症状だ。
この極端な速度低下の犯人は、GPUとCPU間のデータ転送を担うPCIeバスの帯域幅にある。
RTX 4080のようなハイエンドGPUを使っていても、バス帯域の物理的なボトルネックは避けられない。
解決策はシンプルで、VRAM内にモデルを完全に収めるか、より小さい量子化モデルを選ぶしかない。
無理に巨大なモデルを動かすより、VRAMに収まるサイズのモデルを高速に動かす方が、実用性ははるかに高くなる。
自分の環境に合ったモデルサイズを見極めることが重要だ。
Tips 6: コンテキストサイズを縮小してVRAMを節約する
VRAMの容量不足に悩んでいるなら、Ollamaのコンテキストサイズを見直すのが効果的だ。
デフォルトで設定されている大きなコンテキストサイズを半分に減らすだけで、推論速度が10%以上向上することがある。
コンテキストサイズを小さくすると、推論時に生成されるKVキャッシュが消費するVRAMを大幅に節約できる。
その結果、空いたVRAMのスペースにモデルのレイヤーをより多く載せられるようになり、システムRAMへのオフロードを減らせる。
長文の要約や巨大なコードベースの解析などを行わないのであれば、不要なコンテキストサイズは積極的に削るといい。
これだけで、ワンランク上のGPUを使っているような快適さを手に入れられるはずだ。
設定ファイルの数値を書き換えるだけの簡単な作業なので、すぐに試す価値がある。
Tips 7: 最新アーキテクチャの量子化モデルは公式対応を待つ
モデル共有プラットフォームには、非公式に極限まで量子化された最新モデルが日々アップロードされている。
しかし、これらをローカル環境で無理に動かそうとすると、謎のエラーを引き起こすことが多い。
原因は、Ollamaなどの推論エンジンの内部システムが、新しすぎるモデルアーキテクチャをまだ正しく認識できないからだ。
エラーの解決に何時間も溶かすくらいなら、Ollamaの公式タグとして配信されるのを待つのが一番賢い選択だ。
安定した開発環境を維持するためには、公式サポート済みのモデルを選ぶのが鉄則と言える。
最新技術を追うのも大事だが、実用性を重視するなら枯れた技術を使う勇気も必要だ。
公式の対応を待つ間に、既存モデルでのプロンプト改善に時間を充てる方が生産的だ。
しんたろー:
VRAMの壁はローカルLLMを触る上で誰もがぶつかる問題だ。
特にPCIeバスのボトルネックの話は、僕も最初全く気づかずに「なんでこんなに遅いんだ」と頭を抱えた記憶がある。
コンテキストサイズを削るだけで劇的に改善することもあるから、まずは設定を見直すのがおすすめだ。
3. AIエージェントの安全な運用と連携
Tips 8: ツール実行権限を持つエージェントはDockerで隔離する
ローカルのファイル操作やシステムコマンドを実行できるAIエージェントは、業務効率化の強力な武器になる。
しかし、AIが意図しないコマンドを実行してしまうリスクを考えると、そのままホストOS上で動かすのは非常に危険だ。
万が一の誤動作を防ぐため、エージェント本体は必ずDockerコンテナ内に隔離して動かすべきだ。
サンドボックス化のメリット
- ホストOSの重要ファイルへのアクセスを完全に遮断できる
- 誤動作によるシステム破壊を未然に防げる
- 開発環境を常にクリーンな状態に保てる
必要なディレクトリだけをマウントして権限を制限すれば、安全性を確保した上で強力なエージェント機能をフル活用できる。
セキュリティを担保してこそ、AIエージェントの真価を発揮できるというわけだ。
Tips 9: Ollama本体はホストOS上で直接稼働させる
エージェントをDocker内で動かすからといって、LLMの推論エンジンであるOllamaまでコンテナに入れる必要はない。
むしろ、Docker内でOllamaを動かすと、仮想化によるオーバーヘッドやメモリ不足が発生しやすくなり、パフォーマンスが著しく低下する。
特にMac環境などでは、ハードウェアアクセラレーションの恩恵を十分に受けられなくなることが多い。
OllamaはMacやWindows、LinuxなどのホストOSに直接インストールして動かすのが正解だ。
これにより、GPUなどの貴重なハードウェアリソースをロスなくフル活用し、最速の推論速度を引き出すことができる。
役割に応じて配置場所を分けるアーキテクチャ設計が、パフォーマンス最適化の鍵になる。
Tips 10: エージェント用モデルはツール呼び出し対応を厳選する
AIエージェントを構築する際、モデル選びで妥協すると後で必ず後悔することになる。
エージェントとして機能させるには、LLMが外部ツールを呼び出す機能にネイティブ対応しているかが極めて重要だ。
モデルによってはこの機能の精度が低く、指定したフォーマットを守らなかったり、存在しないツールを呼び出そうとしたりする。
ツール呼び出しに確実に対応したモデルを事前に調査して、エージェント専用として選定するといい。
ここを適当に選んでしまうと、プロンプトの調整やエラー対応のコードを書くのに膨大な時間を奪われることになる。
エージェントの頭脳となるモデルは、慎重にテストして決めるのが鉄則だ。
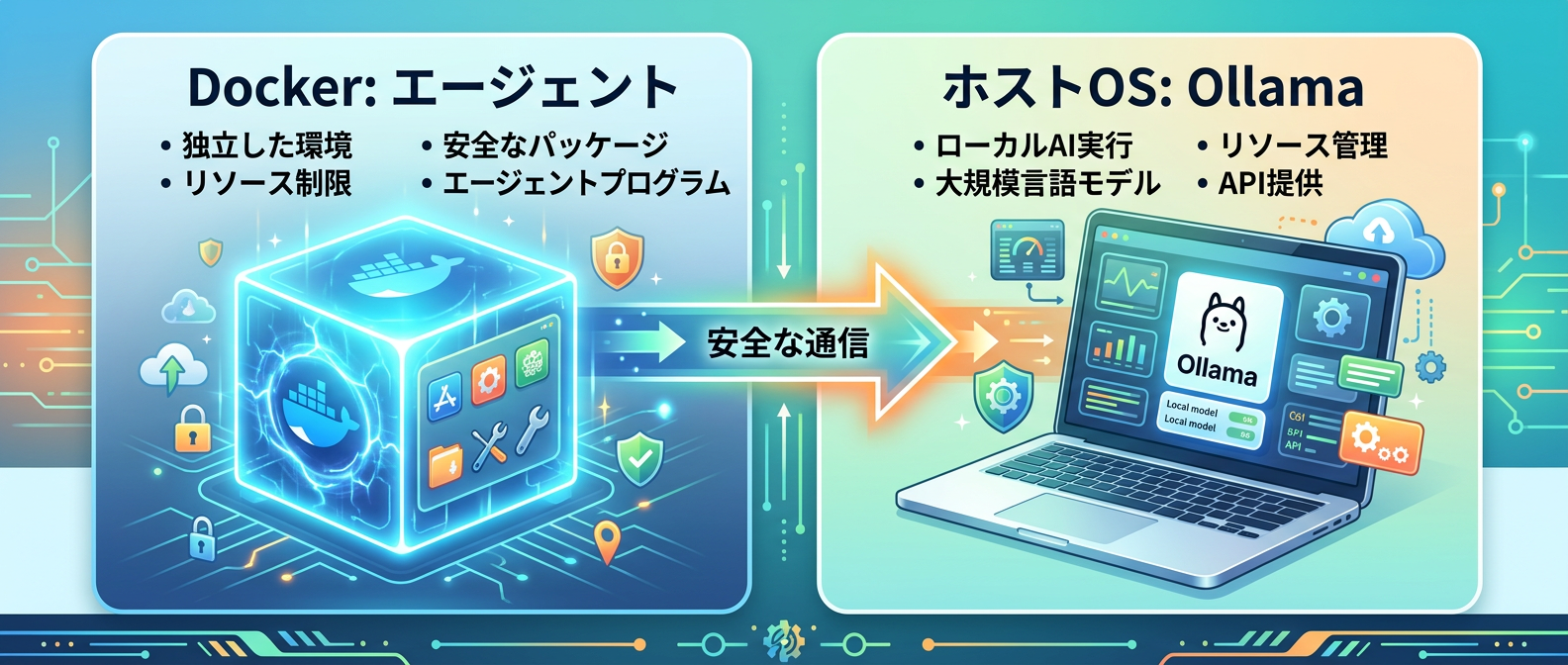
Tips 11: コンテナからホストのOllamaへは専用アドレスを使う
Dockerコンテナ内に隔離したエージェントから、ホストOS上で動くOllamaにアクセスするには、ネットワーク設定の工夫が必要だ。
単にローカルホストを指定しても、コンテナ自身の内部を指してしまうため通信できない。
具体的には、ホストマシンの内部アドレスを指定する特別なドメインと、Ollamaのデフォルトポートを組み合わせて接続先を設定する。
これにより、コンテナの独立性とセキュリティを保ったまま、ローカルLLMのAPIとスムーズに通信できるようになる。
ネットワーク設定の基本中の基本だが、ローカルAI開発の環境構築では必ずつまずくポイントなので、しっかり押さえておこう。
この設定さえクリアすれば、安全で快適なエージェント開発環境が手に入る。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
しんたろーのイチ推しTips
今回紹介した中で一番の推しは、やっぱり「LangChainを使わず素のPythonで実装する」アプローチだ。
Claude Codeを使ってCLIベースで毎日開発していると、シンプルなコードベースのありがたみが身に染みてわかる。
複雑なフレームワークを挟まないからこそ、Claude Codeがプロジェクト全体を正確に把握して、的確な修正提案を出してくれるんだ。
ちなみに、AIエージェントのツールとして紹介したOpenClawもかなり良さそうだ。
サンドボックス環境で動かせるなら、ローカルのファイル操作も安心して任せられる気がする。
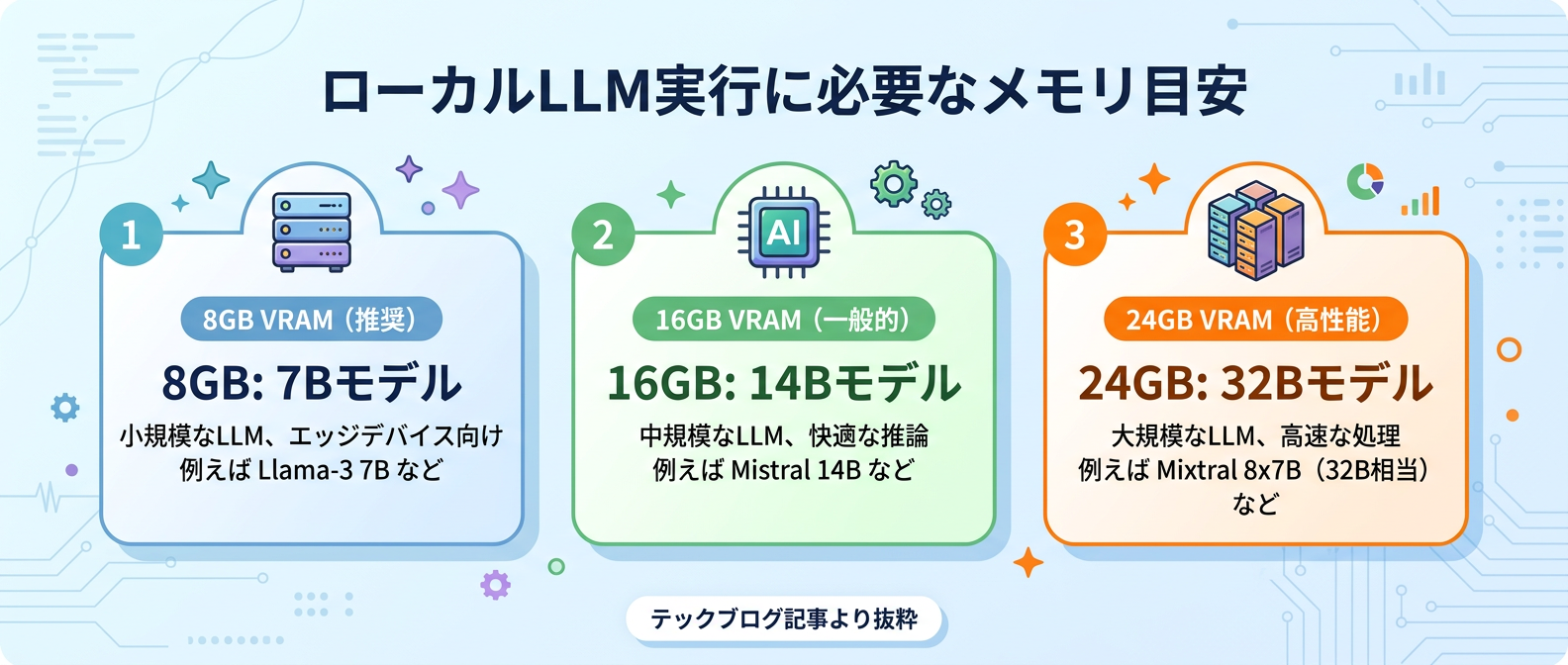
比較表:VRAM容量と快適に動かせるモデルサイズの目安
ローカル環境でLLMを動かす際の、VRAM容量とモデルサイズの目安をまとめた。
自分のPC環境と照らし合わせて、最適なモデル選びの参考にするといい。
| VRAM容量 | 快適に動くモデルサイズ | パラメータ数の目安 | 推論速度の体感 |
| --- | --- | --- | --- |
| 8GB | 小規模モデル | 7B〜8B | 非常に高速で快適に動作する |
| 16GB | 中規模モデル | 14B〜15B | スムーズに動作し実用性が高い |
| 24GB | 大規模モデル(量子化) | 30B〜35B | やや重いがギリギリ実用範囲に収まる |
よくある質問(FAQ)
### Q1: 16GBのVRAMで動かせるLLMのサイズはどのくらいだ?
結論から言うと、4ビット量子化を行った14Bから15Bパラメータのモデルが最適だ。
約9GBから10GBのメモリを消費するため、16GBのVRAMに余裕を持って収まり、高速に推論できる。
35Bなどの大型モデルはVRAMから溢れてシステムRAMにオフロードされるため、推論速度が極端に低下する。
快適な動作を求めるなら、欲張らずに中規模モデルを選ぶのが一番の解決策になる。
### Q2: MoEモデルはアクティブパラメータが小さければ少ないVRAMで動く?
いや、それは大きな誤解だ。
アクティブパラメータ数は1回の推論で使用される計算量を示すだけで、メモリ要件ではない。
推論を実行するには、待機中の部分も含めたモデル全体をVRAMに読み込む必要がある。
そのため、総パラメータ数に応じたVRAM容量が絶対に必要になる。
カタログスペックの計算量に騙されず、全体のサイズを確認してから導入しよう。
### Q3: ローカルでRAGを構築するのにLangChainは必須か?
必須ではないし、むしろ使わない方がいい場合もある。
RAGの仕組みを深く理解し、ブラックボックス化を避けるためには、素のPythonとOllama、ベクトルDBを直接組み合わせるのがおすすめだ。
150行程度のコードで完全なローカルRAGシステムを構築でき、トラブル時の原因究明も簡単になる。
まずはシンプルな実装から始めて、基礎を固めるのが上達の近道だ。
### Q4: AIエージェントをローカルで動かす際のセキュリティ対策は?
AIエージェントはローカルのファイルやコマンドを実行する権限を持つため、Dockerコンテナを使って隔離するのが有効だ。
エージェント本体はDocker内で動かし、LLMの推論を担うOllamaはホストOS側で動かす構成がいい。
ネットワーク経由で接続することで、安全性とパフォーマンスの両方を確保できる。
大事なデータを守るためにも、サンドボックス環境の構築は必須だと言える。
### Q5: 日本語ドキュメントをRAGで検索させる際の最適なチャンクサイズは?
日本語の技術文書などの場合、400文字から600文字がスイートスポットと言える。
日本語は英語に比べて1文字あたりの情報量が多いため、500文字前後が英語の800トークンから1000トークンに相当する。
各チャンクの先頭に元の記事タイトルを付与すると、検索時の文脈が補完されて精度が大きく向上するはずだ。
文字数とメタデータの両方を工夫することで、実用的な検索システムが完成する。
まとめ
今回は、ローカルLLM環境の構築とVRAM最適化のTipsを11個紹介した。
ハードウェアの制約があっても、チャンクサイズの調整やコンテキストサイズの縮小など、ソフトウェア側の工夫で十分にカバーできる。
特に、LangChainに頼らず素のPythonでRAGを組むアプローチは、AI開発の基礎力を高めるのに最適だ。
まずは14Bクラスのモデルを使って、自分のPC環境でどこまで動かせるか確認してみるといい。
試行錯誤の過程そのものが、エンジニアとしての大きな財産になるはずだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
