
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
答えは「チャット」の先にある。Googleが描く物理AIの正体
Googleが動いた。
単なるチャットボットのアップデートではない。
デジタルな個人データと物理的な空間認識を統合する動きだ。
「メールの要約」から「出張の荷造り支援」へ、AIの役割が変化している。
Google I/O 2026の対話ステージで示されたのは、AIが画面を飛び出し、物理世界を認識する未来だ。
開発者として、この変化をどう捉えるか深掘りする。
デジタル個人データと物理空間の融合。Google I/O 2026の全貌
今回の核はパーソナル・インテリジェンスの拡大だ。
Googleは検索、Geminiアプリ、Chromeの3箇所で個人データを統合した。
AIはGmailやGoogleフォトの内容を横断的に理解する。
過去の購入履歴からスニーカーを提案し、旅行計画には予約メールや写真を参照する。
「コンテキストを教える手間」が省かれる仕組みだ。
Google DeepMindは、AIを物理世界に適応させるエージェンティックAIの研究を加速させている。
ボストン・ダイナミクスとの協力による身体性AIの進化が顕著だ。
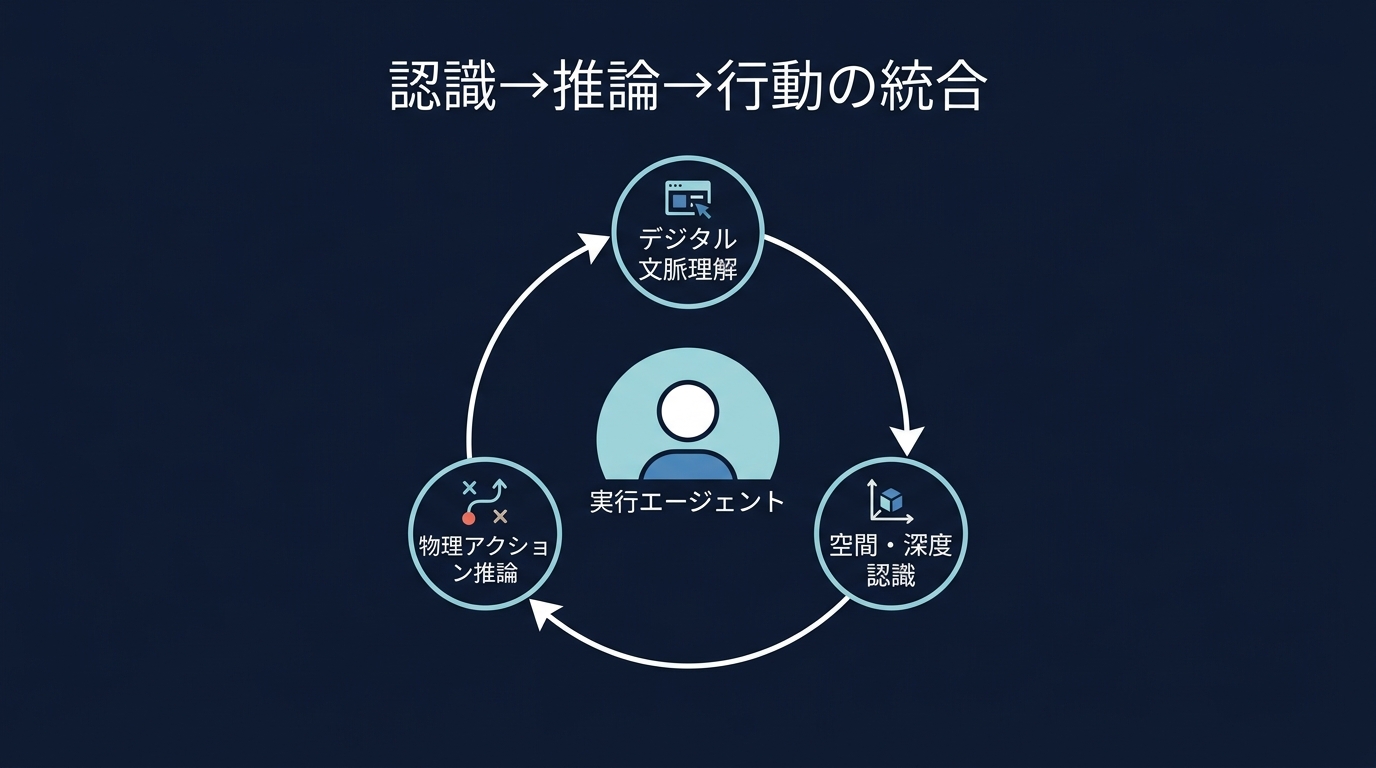
AIは「空間の奥行き」や「物体の配置」を理解し、物理的なアクションを起こす。
MolmoActのようなモデルは、複数カメラの映像から3次元的な空間推論を行い、ロボットの軌道を生成する。
「コップを掴むための角度」といった物理的な推論をAIが実行する。
Googleの戦略は明確だ。
- デジタル空間で個人の文脈を把握する。
- 物理空間で物体の位置をリアルタイム認識する。
- ユーザーの意図を汲み取り、現実世界で行動するエージェントを完成させる。
しんたろー:
Googleがここまで露骨に個人データを統合したことに驚いた。
開発者視点では、OSレベルで最強のRAGが実装されるようなものだ。
ユーザーが何もしなくても「自分専用」になる体験は、一度味わうと戻れない。
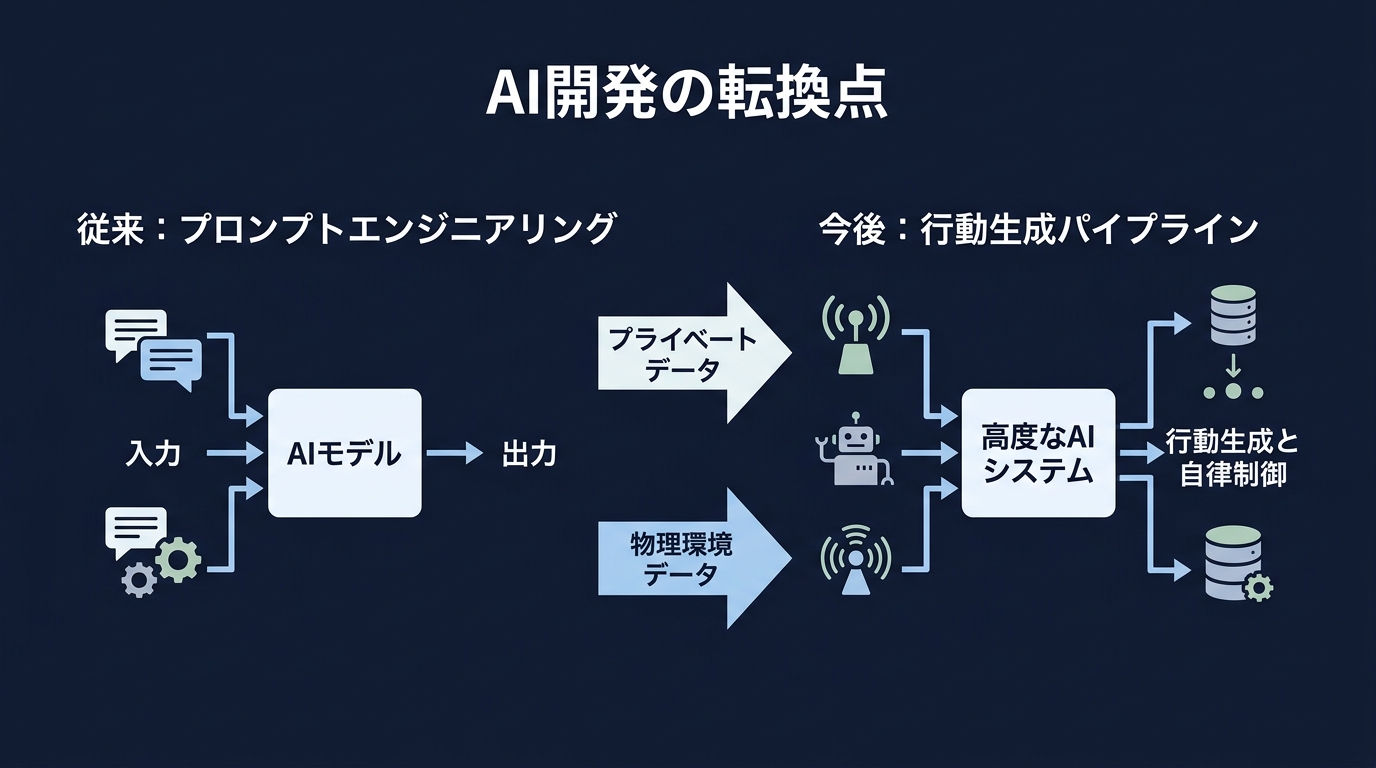
開発者が直面する「行動推論」という新しい壁
Googleの動きは開発者の仕事を変える。
これまでは回答の精度を競うプロンプトエンジニアリングが主役だった。
これからは「安全かつ正確なアクションの実行」を設計するパイプラインが求められる。
Claude Codeはローカル環境のファイルを読み取り、書き換え、テストを実行する。
これはデジタル空間における「自律型エージェント」の姿だ。
Googleは、この自律性を物理世界へ拡張しようとしている。
MolmoActのような空間認識モデルの登場は大きい。
従来のモデルは画像内の物体特定は得意だったが、センチメートル単位の把握は苦手だった。
最新モデルは視覚的な軌跡(Visual Trajectory Tracing)を生成する。
ロボットに「テーブルを片付けて」と指示すると、AIは動画を解析し、物体の深度情報を推論する。
効率的なルートをシミュレーションし、物理的な制御コマンドを出力する。
「認識・推論・行動」のサイクルが単一モデル内で完結する。
僕が開発するThreadPostでも、SNS予約だけでなく、過去の行動データや最新写真と関連付けてAIが判断する仕組みが必要になる。
「AIに何をさせるか」を設計する能力が、今後の差別化要因だ。
空間認識モデルにはbfloat16のような軽量なデータ型や、GPUのメモリ管理がシビアに求められる。
Claude Codeでコードを生成する際も、実行まで見越した設計を指示することが増えた。
デジタルでも物理でも、AIに「手足」を与える設計思想は共通している。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響|今すぐ意識すべきアクション
物理AIはロボット開発者だけの話ではない。
Googleがパーソナル・インテリジェンスのAPIを公開すれば、あらゆるアプリが「ユーザーのすべてを知る」状態から始まる。
開発者が意識すべきポイントは3つだ。
第一に、「コンテキストの設計」だ。
ユーザー入力を待つのではなく、Googleのエコシステムから流れるパーソナルデータをアプリ機能と結びつける必要がある。
「文脈を読み取って提案する」設計への転換だ。
第二に、「プライバシーと透明性の担保」だ。
個人データの統合にはユーザーの拒否反応が伴う。
どのデータにアクセスし、どう処理されるのかを明確に示す必要がある。
Workspaceアカウントでは機能が制限される点に注意し、ビジネス用途ではVertex AIでRAGを組むスキルが必須となる。
第三に、「空間・深度データの活用」だ。
スマホのカメラ情報は2Dから3Dへシフトしている。
MolmoActのようなモデルを扱えれば、ARアプリやスマートホーム連携で優位に立てる。
「物体がカメラから何メートル離れているか」をプログラムで扱えるようにしておく。
まずはHugging Faceで空間認識モデルに触れることを勧める。
PyTorchやTransformersを使い、画像から座標データを抽出するプロセスを理解する。
最後は「データ」と「実行力」の勝負だ。
Googleがプラットフォームを整えるなら、個人開発者はその上で「ニッチで行動に直結する」ツールを作ることに集中すればいい。
Claude Codeに「空間認識モデルで片付けプランを立てるコードを書いて」と頼む日も近い。
FAQ
Q1: Personal Intelligenceは企業向けWorkspaceでも利用可能ですか?
いいえ、現時点では個人用Googleアカウント向けに限定されています。企業や教育機関向けのWorkspaceアカウントは、データプライバシーとセキュリティの観点から対象外です。ビジネス用途で同様の機能を実装する場合は、Google CloudのVertex AI等を利用し、自前でRAGパイプラインを構築する必要があります。
Q2: MolmoActのような物理AIモデルを自分のプロジェクトに組み込む際の注意点は?
MolmoActは視覚的な空間推論を行うため、VRAMの消費が激しい点に注意が必要です。また、モデルの出力は確率的であるため、ロボット等の物理デバイスを制御する場合は、必ず安全性を担保するガードレール層をモデルの出力とデバイスの間に実装することが必須となります。
Q3: GoogleはGeminiで読み取った個人データをAIの学習に使っていますか?
Googleの発表によれば、GeminiやAI Modeは、ユーザーのGmailの受信トレイやGoogleフォトのライブラリの内容を直接学習することはありません。ただし、Geminiに対する特定のプロンプトや、それに対するモデルの回答などの限定的な情報は、機能向上のために利用される場合があります。ユーザーはいつでも設定からアプリの連携をオフにできます。
まとめ
Googleはデジタルな記憶と物理的な現実を、AIという一本の糸で繋ごうとしている。
これは「AIが主体となって動く世界」への招待状だ。
開発者の役割は、新しいインターフェースを使いこなし、ユーザーに新しい体験を届けることだ。
画面の中の文字をいじる時代は終わり、「現実を操作するコード」を書く時代が来ている。
まずは、自分のプロダクトに「ユーザーの文脈」をどう取り込めるか、想像することから始める。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
