
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
冒頭フック
Googleが科学特化型AIの導入を進める一方、国内では約7000億パラメータのモデルの出自を巡る議論が起きている。
フルスクラッチ開発の限界が見える中、今の開発者はゼロからモデルを作る段階ではない。
既存モデルの推論プロセスを改善するADPOのような理論的アプローチと、LoRAによる効率的なドメイン適応が鍵だ。
損失関数のワンライン変更が、開発の常識を変える。
ニュースの概要
AI業界では明確な二極化が進んでいる。
一方は国家主導の巨大モデル活用であり、もう一方は限られた計算資源の中で実用的なモデルを作る現実だ。
ある国の科学技術省と大手AI企業が提携し、生命科学や気象分野でのプロジェクトが始動した。
最先端の科学特化型AIモデルが研究機関に提供される。
8万5000人以上の研究者が利用するタンパク質構造予測モデルの進化版や、アルゴリズム設計を最適化するエージェントが現場に投入されている。
AIは科学的発見を加速させるインフラとして機能している。

国内のAI開発の現実は複雑だ。
約7000億パラメータを誇る国産の大規模言語モデルが、海外のオープンソースモデルをベースにしていたことが判明した。
初期段階で出自やライセンスの明示が不十分であり、開発コミュニティで議論を呼んだ。
日本企業の主要モデルの約6割が、海外のオープンソースモデルをベースにした2次開発だ。
フルスクラッチ開発を阻む3つの壁が存在する。
* 計算資源の壁: 1750億パラメータクラスのモデルをゼロから学習させるには、数千基の最新GPUと数ヶ月の期間が必要だ。
* データの壁: インターネット上のテキストのうち日本語は5%から6%程度であり、データが不足している。
* 人材の壁: 分散学習の最適化や、学習中の損失スパイクを防ぐデータパイプラインを構築できるエンジニアは希少だ。
国内の自然言語処理の最前線では、既存モデルを使いこなすことに焦点が移っている。
国内最大規模の学会では、ADPOと呼ばれる新しいファインチューニング手法が評価を集めた。
これは、AIの応答を評価する際の「生成と評価の不整合」を解消するアプローチだ。
損失関数の計算式を変更するだけで、数学や対話タスクの性能が向上する。
巨大な計算資源で殴り合うのではなく、理論的なアプローチでAIの性能を引き出す。
国家レベルの巨大プロジェクトが進む裏で、開発者が向き合うのは「既存モデルの使い倒し方」と「技術の透明性」だ。
しんたろー:
7000億パラメータのモデルを自前で動かすのはSFの世界だ。
損失関数を1行いじるだけで性能が上がるなら、それは僕らの戦場だ。
リソースの殴り合いではなく、ロジックで勝負できるのは夢がある。
開発者目線の解説
この流れは開発に直結する。
「作らない開発」が本格化しているからだ。
巨大な基盤モデルをゼロから作るフェーズは一部の巨大企業に任せ、既存モデルに特定のドメイン知識を注入し、推論の質を上げるフェーズに移行した。
その最前線にあるのがADPOや、LoRAといった効率的な学習技術だ。
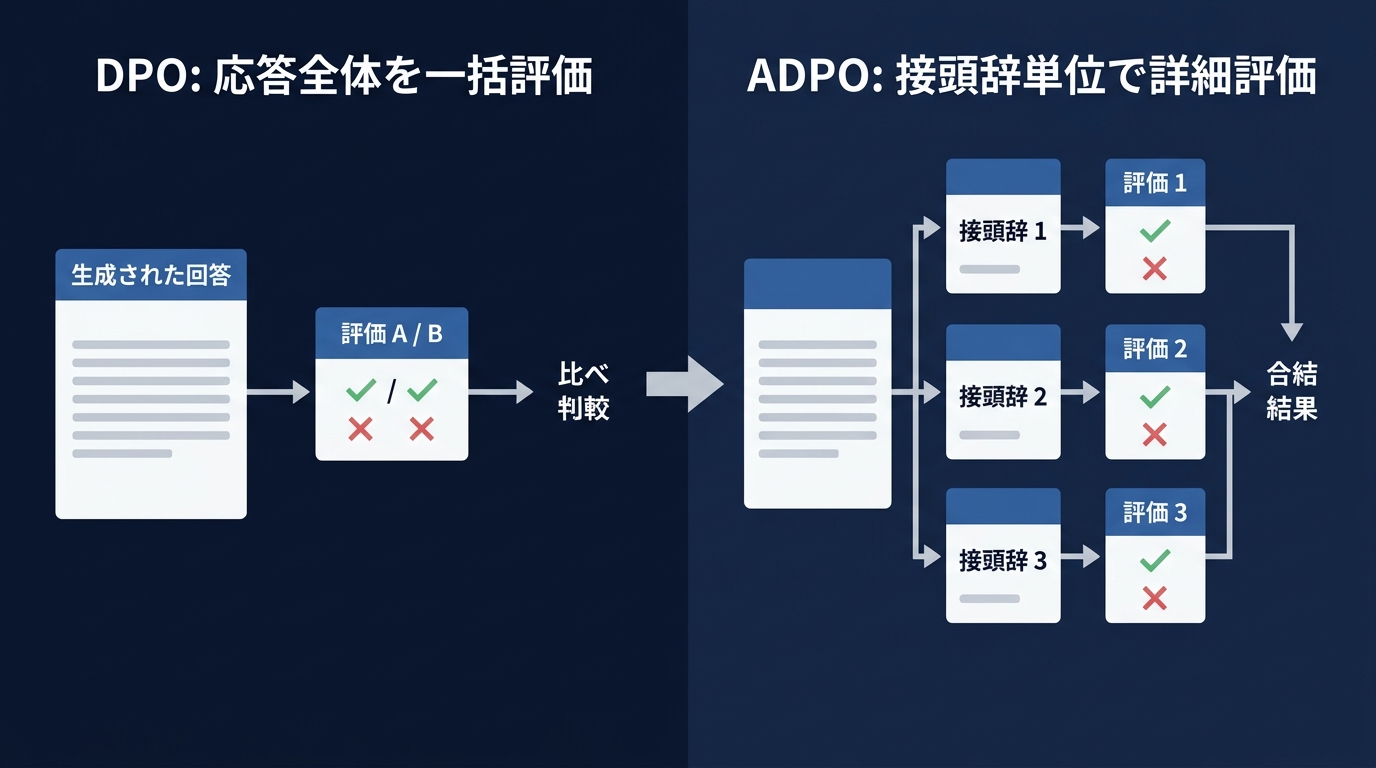
従来のファインチューニング手法であるDPOは、AIの応答全体を一括で比較していた。
しかし、AIはテキストを1トークンずつ自己回帰的に生成する。
全体を一括で評価する手法と、1トークンずつ生成する仕組みの間に不整合があった。
ADPOは、接頭辞単位で細かく評価するように設計し直した。
損失関数における対数シグマの位置を、合計の外側から内側に移動させる変更だ。
たったこれだけのワンラインの変更で、数学的推論や対話の精度が向上する。
計算資源の暴力ではなく、数学的なアプローチでAIの性能の限界を突破する。
Claude CodeのようなAIコーディングアシスタントを使えば、論文レベルの数式を実装に落とし込むのも容易だ。
AIに最新の論文のロジックを読み込ませ、PyTorchのコードに翻訳させる。
理論のキャッチアップから実装までのリードタイムは短縮されている。
特定のタスクに特化させるためのLoRAの活用も必須スキルだ。
モデル全体のパラメータを更新するのではなく、小さな差分行列だけを学習させる。
限られた計算資源でも、AIに専門的な日本語の知識や、特定の業界のルールを教え込むことができる。
科学特化型モデルの社会実装が進めば、APIを叩くだけで高度なアルゴリズム設計やデータ解析が行えるようになる。
APIを叩くだけでは差別化は生まれない。
ベースとなる強力なモデルを選び、LoRAで独自のドメイン知識を注入し、ADPOのような手法で推論プロセスを最適化する。
この一連のパイプラインを設計できるかどうかが、開発者の価値を決める。
技術的な最適化と同じくらい重要なのが「透明性」だ。
強力なオープンソースモデルを利用することは合理的な選択だ。
問題は、何をベースにして、どのような追加学習を行ったのかを隠すことだ。
ベースモデルのライセンスを遵守し、出自を明示する。
エンジニアリングの倫理が、今後のAI開発における信頼獲得の条件になる。
技術力を誇示するために出自を曖昧にする行為は、プロジェクトの寿命を縮める。
さらに、AIの内部で何が起きているのかを解明する「メカニズム解析」への注目も高まっている。
位置符号化の理論的理解を深める研究では、モデルがテキストの順番をどう認識しているかが証明されつつある。
推論時にパラメータを調整するだけで、再学習なしに長いテキストを処理できる技術も報告されている。
AIをブラックボックスとして扱うのではなく、内部構造を理解しようとする姿勢が求められる。
Claude CodeにADPOの論文の数式を投げたら、一瞬で実装案が返ってきた。
理論のキャッチアップからコードに落とすまでのリードタイムが短い。
昔なら数式の意味を理解するだけで週末が潰れていた。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実務への影響
実務で意識すべきアクションアイテムは3つある。
1つ目は、ベースモデルの選定とライセンス確認の徹底だ。
高性能なオープンソースモデルは魅力的だが、商用利用の可否やクレジット表記の義務はモデルごとに異なる。
開発の初期段階で、必ずconfig.jsonやライセンスファイルを確認する。
後から「実はあのモデルがベースでした」と発覚するリスクは、プロジェクトを根底から破壊する。
透明性の確保は、コンプライアンスの問題だけでなく、信頼に直結する。
2つ目は、LoRAを用いた小規模なファインチューニングの検証環境を作ることだ。
すべてのタスクに数千億パラメータの巨大なモデルは必要ない。
特定の業務フローや、ニッチな専門用語の理解であれば、小規模なモデルに質の高いデータでLoRAを適用する方がコストパフォーマンスが良い。
クラウドの安価なGPUインスタンスを使って、数十件の小さなデータセットでの追加学習を試す。
モデルがどのように特定の知識を獲得していくのか、その手触りを得る。

3つ目は、推論プロセスの最適化手法へのキャッチアップだ。
ADPOのような、損失関数の微調整による性能向上はトレンドになる。
モデルのパラメータを物理的に増やすのではなく、学習の「させ方」を工夫する。
最新の論文や研究発表を定期的にチェックし、自分のプロジェクトに応用する。
AIの出力のブレをプロンプトエンジニアリングだけで抑え込むのには限界がある。
評価ロジックを根本から見直し、理論的に正しい手法を取り入れることで、システムの安定性は高まる。
AIの出力フォーマットをいかに安定させるかは常に課題だ。
プロンプトの微調整を繰り返すよりも、モデルの評価関数レベルでアプローチした方が、メンテナンスコストは下がる。
AIをブラックボックスのまま扱うのではなく、中で何が起きているのかを理解する。
解釈性やメカニズム解析への関心を持つことが、トラブルシューティングで役立つ。
技術の進化は早いが、基礎となる数学やアーキテクチャの理解は裏切らない。
ThreadPostの裏側でも、AIの出力フォーマットが崩れる問題には悩まされている。
プロンプトをこねくり回すより、評価関数レベルでアプローチした方が根本解決になる。
今度の休みにでも、検証環境を作って挙動を見てみる。
FAQ
Q1: 国産LLMを作る際、フルスクラッチとファインチューンどちらを選ぶべき?
A1: 現在の計算資源と高品質な日本語データの希少性を考慮すると、フルスクラッチは現実的ではない。強力なベースモデルに対し、LoRAを用いて日本語ドメイン知識を注入する手法が、コスト対効果および性能面で合理的だ。ベースモデルのライセンス遵守と出自の明示が不可欠となる。
Q2: ADPOはDPOと何が違うのか?なぜ性能が良いのか?
A2: DPOは応答全体を比較するが、LLMはトークン単位で生成するため、評価と生成のプロセスに不整合が生じる。ADPOは接頭辞単位で報酬を設計し、損失関数の計算式を微調整することでこの不整合を解消した。実装が容易でありながら、数学や対話タスクで高い性能を示す。
Q3: 科学特化型のAIモデルは一般的なWeb開発にも応用できるのか?
A3: 直接的な応用は難しいが、背後にあるアプローチは参考になる。コーディングエージェントによるアルゴリズム最適化の仕組みは、システム開発の効率化に直結する。専門領域に特化したモデルを複数組み合わせるマルチエージェントの考え方は、複雑なビジネスロジックをAIで処理する際の武器になる。
まとめ
巨大モデルの力に圧倒されつつも、開発者が戦うべきは「いかに賢く使いこなすか」の領域だ。
理論の理解と実装のスピードが、価値を決める。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
