
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIの「賢さ」の定義が、モデル単体から「仕組み」へとシフトした。
AI開発の世界で、大きな地殻変動が起きている。
これまでは「どのモデルが一番賢いか」という議論が中心だった。
今は違う。
コンテキストを効率的に回し、推論を動的にルーティングする「インフラとロジックの統合設計」が勝負の分かれ目だ。
GitHubのアップデートは、共通のキーワードを示している。
トークン効率の最大化とレイテンシの削減だ。
開発者はこの流れの中にいる。
AIエージェントの性能を左右するのは、モデルのパラメータ数ではなく、「推論の最適化戦略」だ。

複数ソースから読み解く、AIエージェントの「頭脳」の進化
AI開発トレンドには、3つの技術的進化がある。
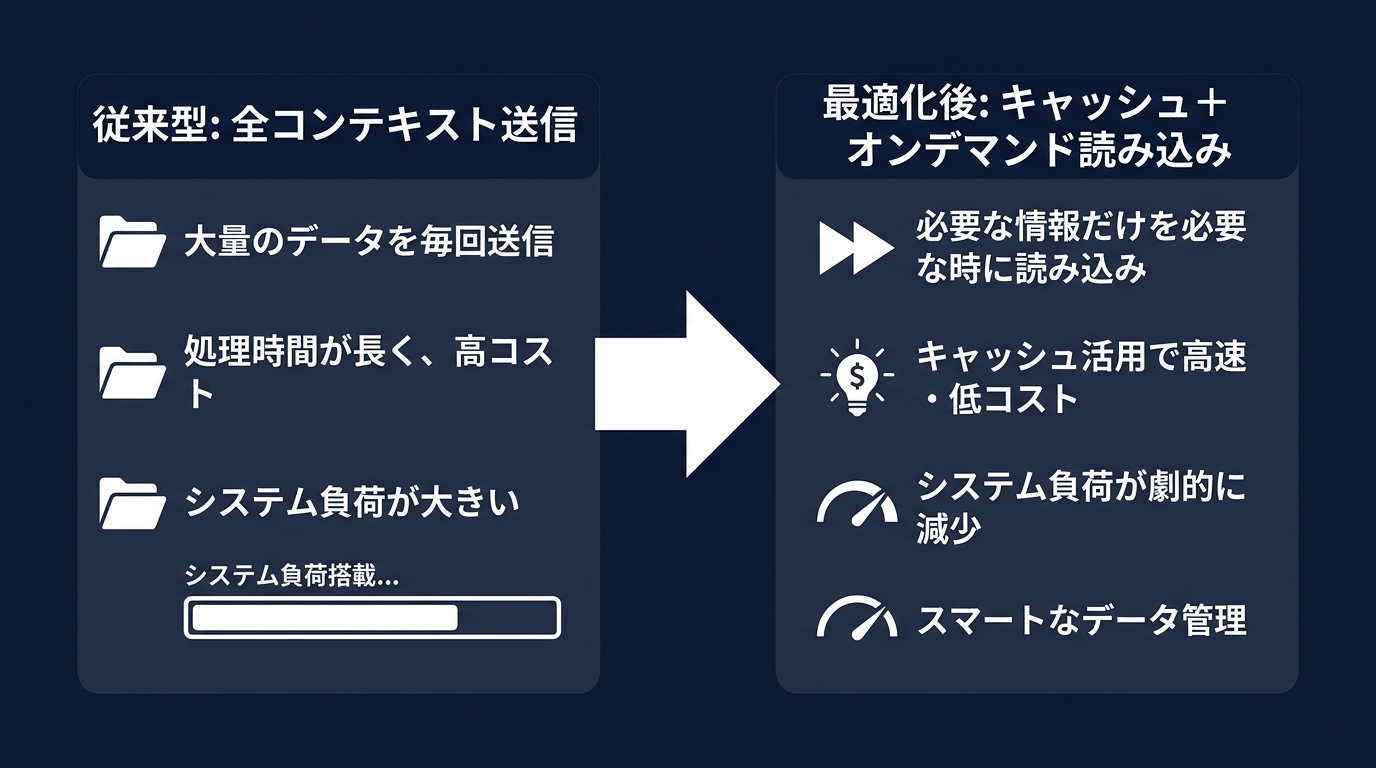
1つ目は、プロンプトキャッシュの活用だ。
開発者がAIと長いセッションを続ける際、毎回同じ命令やリポジトリ情報を送る必要はない。
最新の仕組みでは、プロンプトの接頭辞をキャッシュし、モデルの状態を再利用する。
同じ情報を何度も計算し直す必要はなくなった。
2つ目は、ツールのオンデマンド読み込みだ。
エージェントが使えるツールが増えるほど、JSONスキーマなどの定義がコンテキストを圧迫する。
必要な時だけ必要なツールの定義をロードする仕組みが導入された。
「全部入り」のプロンプトから、「必要な分だけ」のプロンプトへ移行している。
3つ目は、モデルの自動選択(Autoルーティング)だ。
簡単なコード説明、特定箇所の修正、複数ファイルにまたがるリファクタリングを同一のモデルで処理するのは非効率だ。
タスクの意図をAIが判断し、最適なモデルへ動的に処理を振り分ける。
この「ルーティング」の精度が、AIツールの使い心地を決定づける。
しんたろー:
これまでは「とりあえず最強モデル」を選択していた。
最近の自律型エージェントの動きを見ると、コンテキストの管理が重要だと感じる。
賢いモデルを「どう賢く使うか」のレイヤーが気になる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線で見る「推論最適化」の裏側
Claude CodeのようなCLIツールを触ると、この「最適化」の重要性がわかる。
ターミナルからコードを修正し、テストを回し、デプロイまで持っていく。
この一連の流れで、毎回コンテキスト全体を再計算していては仕事にならない。
注目すべきは、キャッシュの概念だ。
ユーザーの質問に対して、過去の類似したやり取りや検索結果をメモリ上に保持する。
さらに、「先読み(プレフェッチ)」という考え方がある。
ユーザーが次に何を質問するかを予測し、バックグラウンドで関連ドキュメントを検索する。
ユーザーが質問を投げた瞬間に、回答に必要なコンテキストが揃っている状態を作る。
「待機時間をゼロにする」ための工夫が、AI開発の最前線だ。
また、分散システムにおけるレート制限の管理も、エージェント開発では避けて通れない。
複数のワーカーが同時にAPIを叩く際、トークン消費量を正確に同期する必要がある。
ここでは、共有ストアを使ったCAS(Compare-and-Swap)操作のような、伝統的な分散システムの知見が活用されている。
最新のAI開発は、プロンプトエンジニアリングの域を超えた。
インフラ、キャッシュ戦略、分散システム、AIモデルの融合が、今取り組むべき領域だ。
1人SaaS開発では、インフラのオーバーヘッドが開発スピードに直結する。
キャッシュの設計次第で、1日のデバッグ回数が変わると思った。
派手な新モデルの発表よりも、こうした地味な最適化の話に飯の種が詰まっている。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
僕らの開発にどう影響する?今日から意識すべきアクション
「モデルに渡す情報をいかに削り、いかに再利用するか」を設計の第一義に置く。
具体的なアクションアイテムを挙げる。
- コンテキストの階層化
すべてをプロンプトに入れるのではなく、「常に必要な情報」「特定の条件下で必要な情報」「検索して持ってくる情報」を明確に分ける。
最新のツール検索の仕組みを、自分のアプリでも実装する。
- キャッシュコントロールの意識
API側が提供しているキャッシュ機能を活かすプロンプト構造にする。
変更頻度の低い情報をプロンプトの前方に配置するだけで、コストと速度が改善する。
- 非同期でのコンテキスト準備
ユーザーの入力を待つのではなく、会話の流れから「次に来る可能性が高い情報」をバックグラウンドで取得し、キャッシュしておく。
この「先読み」の実装は、UXを向上させる。
- レート制限の状態管理の高度化
単一のプロセスで制限をかけるのではなく、RedisやNATSのような共有ストアを使い、リビジョン番号を用いた条件付き更新で正確なトークン管理を行う。
これにより、スケーラブルなAIエージェントの基盤を作る。
これらの技術は、すぐに「当たり前」の作法になる。
今のうちに手を動かして、自分なりの「推論最適化パターン」を持つことが、将来的な差別化につながる。
ユーザーが求めているのは「賢くて速い」ことだ。
賢さはモデルが解決するが、速さは開発者の腕の見せ所だ。
ThreadPostの開発でも、このあたりのレイテンシ削減には気を使っている。

AI開発の現場でよくある質問(FAQ)
Q1: なぜモデルのルーティングやキャッシュが重要なんですか?
すべてのタスクに最強のモデルを割り当てると、コストとレイテンシが爆発するからだ。
最新の自動ルーティングは、タスクの難易度や緊急度に応じて計算リソースを動的に配分する。
簡単な質問には軽量モデルで即答し、複雑なロジック修正には推論モデルを当てる。
この使い分けによって、ユーザーは「速さ」と「質の高さ」を最適なコストで同時に手に入れる。
Q2: 分散環境でLLMのレート制限を実装する際の注意点は?
複数ワーカーが同時にAPIを叩く場合、プロセスごとの制限だけでは不十分だ。
共有ストアを使い、CAS(Compare-and-Swap)操作で「現在の使用量」をアトミックに更新・判定する。
最新のキーバリューストアを使う場合は、読み込みから書き込みまでの間に他者が値を更新していないかをリビジョン番号で確認するループ処理が不可欠だ。
これを怠ると、API制限を超過してシステムが止まる原因になる。
Q3: 「先読み(プレフェッチ)」はどのようなアプリで有効ですか?
リアルタイム性が求められる音声AIや、膨大なドキュメント検索を伴うチャットボットで有効だ。
ユーザーが話し終える前に、会話の文脈から次のトピックを予測して検索を済ませておくことで、検索による数秒の待機時間をゼロに近づける。
ただし、予測が外れた場合のキャッシュ汚染を防ぐため、TTL(有効期限)の管理や、古いデータを捨てるLRUポリシーの設計が不可欠だ。
まとめ:AIは「道具」から「自律的なシステム」へ
AI開発の主戦場は「モデルの出力結果」から「推論のプロセス全体」に移った。
プロンプトキャッシュ、ツール検索、自動ルーティング、先読み。
これらはすべて、AIを効率的な思考システムにするための工夫だ。
開発者に求められているのは、これらの技術を組み合わせて、ユーザーがストレスを感じない体験を構築することだ。
Claude Codeのようなツールが教えてくれるのは、「速さは正義である」という真理だ。
AIの進化を追いかけるのは大変だが、刺激的な時代だ。
ThreadPostの開発を通じて、この「推論の最適化」を極めていく。
最後に勝つのは「ユーザーを待たせない」やつだ。
どんなに賢くても、返信に30秒かかったら人間は離れていく。
0.1秒を削るために泥臭いキャッシュ戦略を練る。これこそが開発者の醍醐味だ。
ちなみに、このキャッシュ設計で頭を抱えている時間は、もはや趣味の領域に達している。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
