
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
音声生成は「読み上げ」から「演技」の時代へ
AIの音声出力が単なるテキストの読み上げだった時代は終わった。最新の音声生成モデルは、自然言語による演出指示を受け取り、感情と文脈を伴う「演技」をする。
70以上の言語に対応し、ブラインドテストでEloスコア1,211を記録した最新モデルの登場は、AIキャラクター開発の前提を塗り替える。これは単なる音声品質の向上ではない。
開発者が「何を話すか」と「どう話すか」を完全に分離して制御できるアーキテクチャへの移行だ。この分離がもたらす開発体験の変化と、実務での活用法を解剖する。
感情とペースを操る最新音声モデルの衝撃
AI音声生成の領域で進化が起きている。最新のテキスト音声変換モデルは、従来の単調な読み上げを超え、きめ細かな感情表現と発話ペースの制御を実現した。
特筆すべきは、オーディオタグと呼ばれる自然言語コマンドによる演出制御機能だ。テキスト入力の中に「ささやき声で」「少し急いだペースで」といった指示を埋め込むことができる。
これにより、開発者はAIの発話をディレクションできるようになった。この最新モデルは70以上の言語をサポートしている。
さらに、複数の話者が交差するような対話生成にも対応する。第三者によるブラインドテストのベンチマークでは、Eloスコア1,211という評価を獲得した。
これは数千回の人間によるブラインドテストの結果であり、高品質な音声生成と低コストな推論を両立している。エンタープライズから個人の開発者まで、映画レベルの没入感を持つ音声体験を構築できる環境が整った。

生成された音声には不可聴の電子透かしが埋め込まれる。これはフェイク音声の拡散を防ぐための技術的な安全弁だ。
人間の耳には聞こえないが、専用のツールを使えばAIによって生成された音声であることを識別できる。高品質な生成能力と、社会的な責任を担保する識別技術がセットになっているのが、最新のAI音声基盤の特徴だ。
このモデルの登場により、AIキャラクターは「台本を読む機械」から「感情を持つ役者」へと進化した。開発者はAPIを通じて、発話のトーン、息継ぎのタイミング、感情の起伏をチューニングできる。
単なるテキストの音声化ではなく、オーディオ体験そのものをプログラマブルに設計できる時代だ。音声データの生成から配信までのパイプラインが、新しい次元へと引き上げられた。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
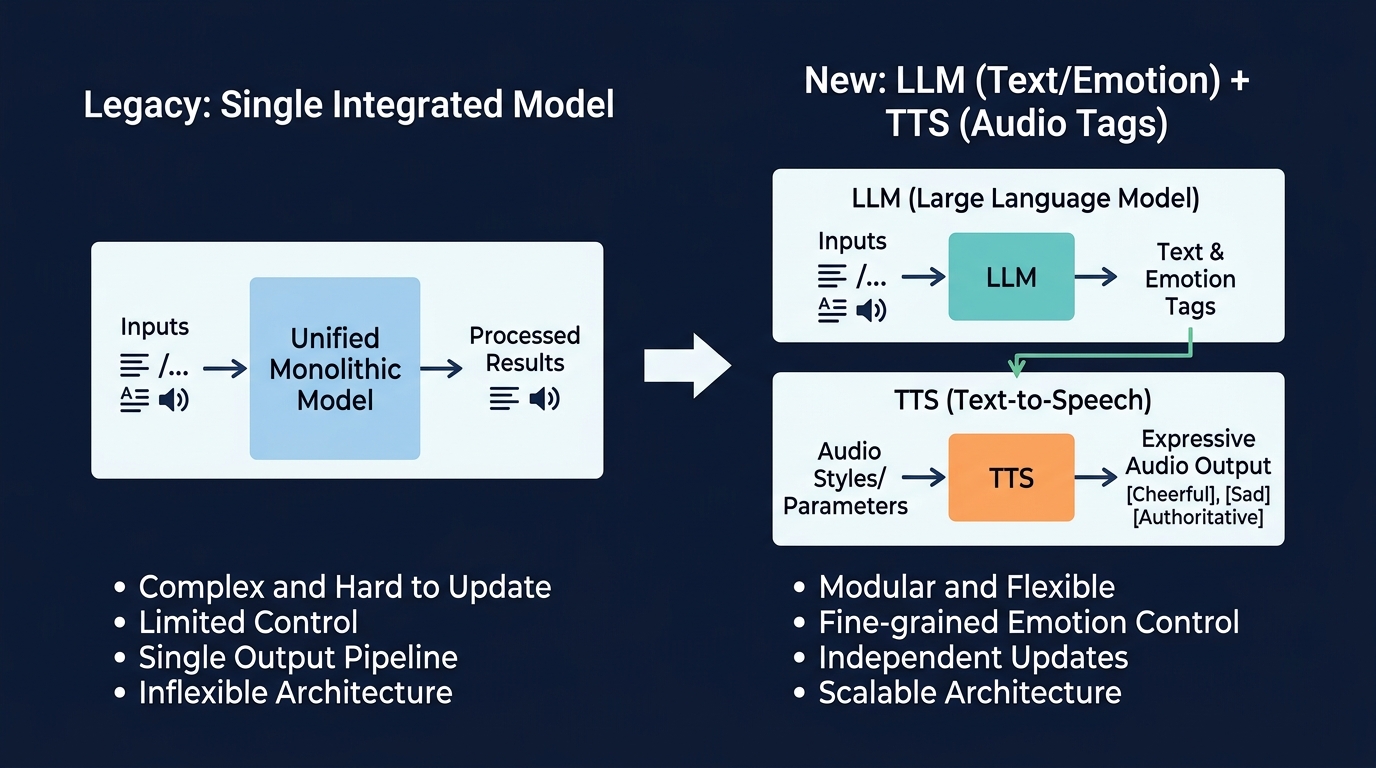
なぜLLMとTTSの分離が重要なのか
従来のAIキャラクター開発には限界があった。一般的なRPGのNPCは、会話ツリーとあらかじめ用意された返答の仕組みで動いている。
これは「台本通りに動いている」という感覚が残る。過去のゲーム開発では、声優が録音した数百の音声ファイルをアセットとして保持する必要があった。
これには膨大なストレージ容量が必要で、アップデートのたびにコストがかかっていた。大規模言語モデルの登場でテキストは動的に生成できるようになったが、初期の音声合成は平坦な声しか出せなかった。
言語モデルが気の利いたテキストを生成しても、最終的な音声出力が平坦であれば、ユーザーの没入感は削がれる。巨大なマルチモーダルモデルにテキスト生成と音声出力の両方を担わせると、推論コストが跳ね上がる。
ここで重要になるのが、LLM(何を話すか)とTTS(どう話すか)の完全な分離だ。言語モデルにはテキストの生成と、それに付随する感情のメタデータの出力に専念させる。
そのメタデータをオーディオタグとして最新の音声モデルに渡し、最終的な演技を行わせる。この分離アーキテクチャにより、開発者はシステム全体の柔軟性を高めることができる。
例えば、推論速度を優先するなら、ローカル環境で軽量な言語モデルを動かす。そこで生成されたテキストと演出指示だけを、高品質なクラウドベースの音声モデルに送信する。
低遅延なローカル推論と高品質なクラウド生成のハイブリッド構成が標準になる。テキスト生成モデルの進化と音声生成モデルの進化を、それぞれ独立して取り入れることができる。
しんたろー:
Claude CodeにAPI通信のボイラープレートを書かせている。LLMにプロンプトで「感情タグをデータ構造として返せ」と指示するだけで、音声側の演出が動的に変わる仕組みは、実装していて面白い。
音声生成技術の進化に伴い、生成物の識別という課題も浮上している。クラウドベースの最新モデルは、生成される全ての音声に不可聴の透かしを埋め込んでいる。
これはAPIを提供する企業側で制御されており、開発者が透かしを外すことはできない。一方で、オープンソースや研究ベースで公開されている最新の音声モデルは、異なるアプローチをとる。
ローカル環境で構築できる音声認識やリアルタイム音声合成のパイプラインでは、透かしの強制は存在しない。開発者はモデルの重みを直接操作し、独自の音声データセットでファインチューニングを行うことができる。
このクローズドな透かし技術とオープンな生成環境の乖離は、システム設計に影響を与える。商用サービスとして展開する場合、プラットフォームの規約や法的なコンプライアンスを満たすために、透かし入りのクラウドAPIを選択する場面が増える。
逆に、閉じた環境での実験や、極限までレイテンシを削りたい場合は、オープンなモデルをローカルで動かす選択肢が有利になる。開発者は、音声の品質やコストだけでなく、生成物の出所証明という観点からもアーキテクチャを選定する。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
没入型AI体験を作るための演出パイプライン設計
開発者はこの進化を実務に落とし込む必要がある。最も重要なのは、言語モデルへのプロンプトエンジニアリングを「演出指示」のレベルまで引き上げることだ。
キャラクターの設定を与えるだけでなく、出力するテキストにオーディオタグを自動挿入させるシステムプロンプトの設計が求められる。パイプライン構築において、以下の要素を組み込む。
- 感情タグの自動生成: 言語モデルに「悲しみ」「喜び」「焦り」などの感情パラメータをテキストと同時に出力させる
- ペースの動的制御: 文脈に応じて発話の速度を変化させる指示をプロンプトに含める
- ストリーミング処理の実装: 音声データの生成を待たずに、細かなデータ単位で受信して再生する仕組みの構築
- ローカルバッファリング: ネットワーク遅延による音声の途切れを防ぐため、クライアント側でのメモリ管理
- フォールバック設計: クラウドAPIのタイムアウト時に、ローカルの軽量音声モデルに切り替える仕組み
- 音声認識の統合: マイク入力からの文字起こしモデルと連携したフルパイプラインの構築
- コンテキスト情報の付与: ゲーム内の時間帯や場所の情報を言語モデルに渡し、音声のトーンに反映させる
- データ変換処理: クライアント側で受信した音声データを再生可能なフォーマットに変換するユーティリティの実装
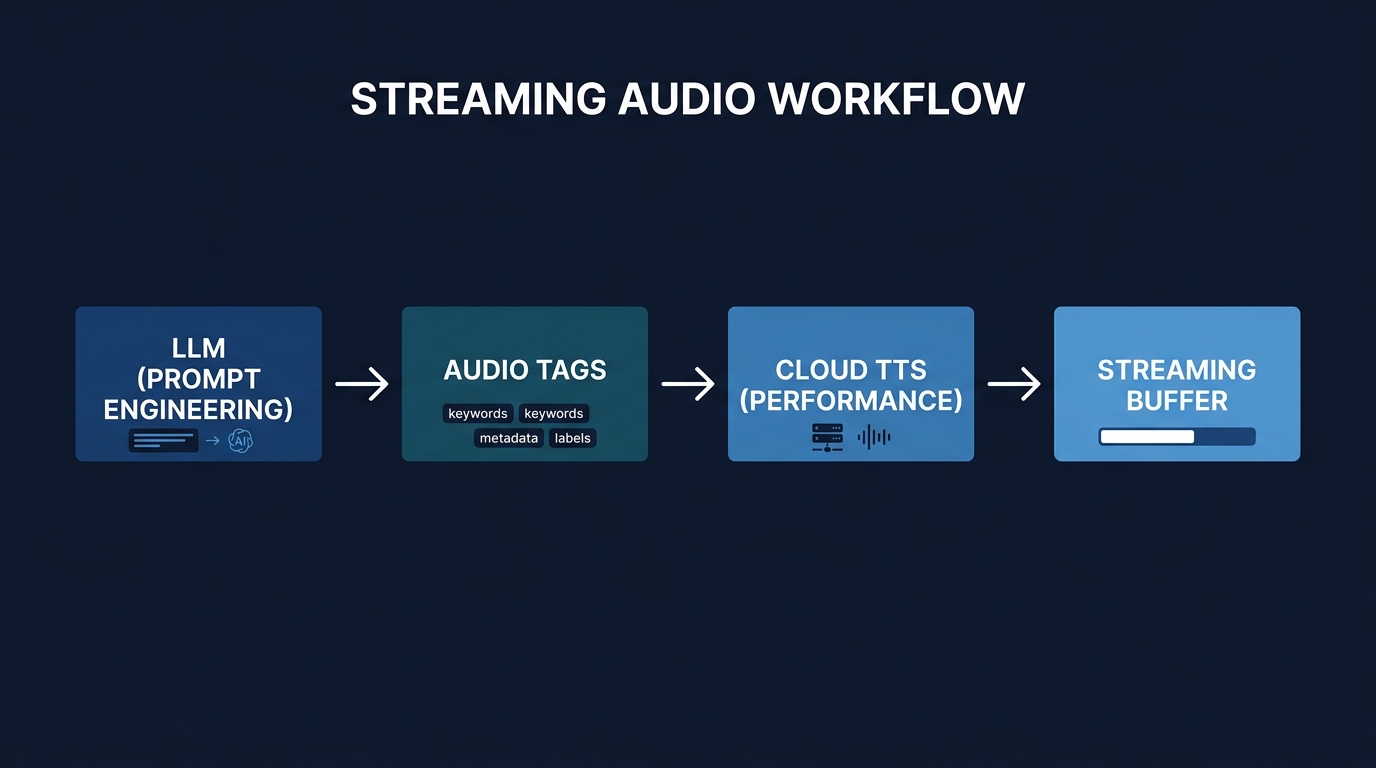
これからのAIキャラクターは、これらの要素が絡み合って命を吹き込まれる。特にストリーミング処理とバッファ管理は、ユーザー体験を左右するクリティカルな部分だ。
高品質な音声でも、返答までに数秒のラグがあれば、会話のテンポは死んでしまう。通信の確立からデータの受信、再生の開始までをミリ秒単位で最適化する。
テキストが数単語生成された時点で音声モデルにリクエストを投げ、返ってきた音声データをリングバッファに溜め込んでいく。ネットワークの揺らぎを吸収するためのバッファサイズの最適化が、開発者の腕の見せ所だ。
バッファが小さすぎると音声が途切れ、大きすぎると遅延が目立つ。ゲームエンジンで実装する場合、メインスレッドをブロックせずに非同期で音声データを処理する堅牢な設計が不可欠だ。
演出パイプラインの構築は状態管理が複雑だ。音声の再生完了イベントと、次のテキスト生成のタイミングを同期させる処理はバグの温床になりやすい。Claude Codeを使って状態遷移のテストコードを自動生成させている。
システム全体を通してのコンプライアンス確認も必須となる。生成された音声に透かしが含まれている場合、それをゲームエンジンやブラウザで再生する際に、意図せず透かしが破壊されないか検証が必要だ。
音声ファイルのフォーマット変換や圧縮処理の過程で、識別情報が失われてしまうと、プラットフォーム側の監査で弾かれるリスクがある。ゲーム開発ではアセットの容量削減のために音声圧縮は必須だが、ここに技術的なトレードオフが生じる。
非圧縮のフォーマットでストリーミングするか、透かしに耐性のある独自の圧縮アルゴリズムを採用するか。技術的な品質と法的な安全性を両立する設計が、プロの開発者には求められる。
音声データの圧縮と透かしの保持のトレードオフは悩ましい。クライアントのメモリを節約するために圧縮率を上げると、透かしが消える可能性がある。この検証作業は、自動化テストのパイプラインに組み込んでいる。
開発者が知っておくべき3つの疑問
Q1: 最新の音声モデルのオーディオタグは、LLMの出力に直接埋め込めますか?
はい、可能です。最新のテキスト音声変換モデルは、テキスト入力内に自然言語コマンドを埋め込むことで、発話のスタイルやペースを動的に制御できます。開発者は言語モデルのシステムプロンプトに「感情やペースを指定するタグをテキストに含める」という指示を組み込むことで、返答内容に応じた感情豊かな音声を自動生成させることができます。
Q2: ローカルLLMとクラウドTTSを組み合わせる際の注意点は?
最大の課題はレイテンシです。ローカル環境で生成したテキストをクラウドの音声APIに送る際、ネットワーク遅延が発生します。これを解決するには、テキスト生成の完了を待たずに、細かなデータ単位で音声をリクエストするストリーミング処理の実装が不可欠です。クライアント側でデータ変換やバッファリングを適切に行い、音声の途切れを防ぐ設計が求められます。
Q3: AI生成音声の透かしは、ゲームやアプリ開発で問題になりますか?
現時点では、不可聴な透かし技術が採用されているため、ユーザーのオーディオ体験を損なうものではありません。ただし、著作権やプラットフォームの規約上、AI生成物であることを明示する必要がある場合、この透かしは法的なコンプライアンスを担保するツールとなります。商用利用時は、各社の利用規約で透かしの保持や明示が義務付けられているか、確認が必要です。
単なるテキスト出力からの脱却
AIの音声出力は、何を話すかの生成から、どう表現するかの演出へとフェーズが移行した。言語モデルと音声モデルを分離し、オーディオタグで感情を制御するパイプラインの構築が、今後のAI体験の質を決定づける。
技術の進化を単なるニュースで終わらせず、自分のプロダクトにどう組み込むか。没入感のある演出パイプラインの構築は、開発者の腕の見せ所だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
