
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
音声エージェント、ついに「使えるレベル」に来た
Gemini 3.1 Flash Liveが出た。ComplexFuncBenchで90.8%。200カ国以上で提供開始。数字だけ見ると「またGoogleが発表したか」で終わりそうだが、今回は違う。
モデルの精度と速度が一定のラインを超えると、「試せるもの」から「業務に組み込めるもの」に変わる。その閾値を、音声AIが今まさに越えようとしている。
ただし、モデルが良くなっても「インフラ側」の問題は別の話だ。そこが今回の本題。
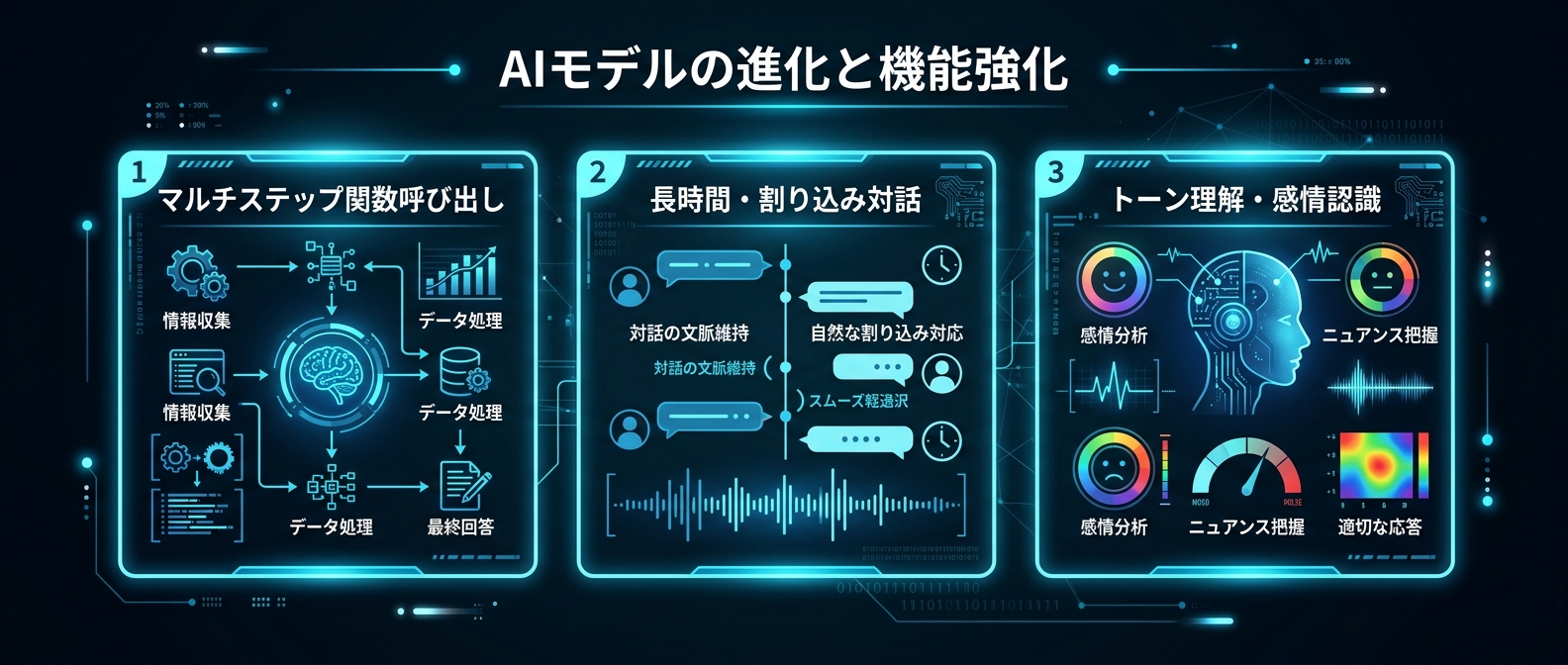
Gemini 3.1 Flash Liveで何が変わったか
3つの改善が核心だ。
1. 複雑なマルチステップ関数呼び出しの精度向上
ComplexFuncBench Audioというベンチマークで90.8%のスコアを記録。これは音声入力を受けながら複数の関数を連続して呼び出す能力を測るもの。前モデルから大きく改善している。
音声エージェントが「予約して、確認メールを送って、カレンダーに追加して」みたいな複合タスクをこなせるかどうか、の指標だと思えばいい。
2. 長時間・割り込みありの対話での精度
Scale AIのAudio MultiChallengeで36.1%(思考モードオン)。このベンチマークは、実際の会話で起きる「えーと」「あ、ちょっと待って」みたいな割り込みや躊躇が入った状態での指示理解を測る。
リアルな会話で崩れないモデル、という方向性が見えてくる。
3. トーン理解の改善
ピッチやペース、話者の感情(苛立ち、混乱)を認識して応答を動的に調整できるようになった。カスタマーサポート用途で特に効いてくる部分。
アクセス方法はシンプル。Google AI StudioのGemini Live APIから開発者向けに提供。エンタープライズ向けにはGemini Enterprise for Customer Experienceとして展開。一般ユーザーはGemini LiveとSearch Liveで体験できる。
Verizon、LiveKit、The Home Depotがすでに導入フィードバックを出しており、「自然な会話品質」を評価している。
また、生成された音声にはSynthIDによる電子透かしが自動で埋め込まれる。ディープフェイク音声対策として、地味に重要な仕様だ。
しんたろー:
ComplexFuncBench 90.8%という数字、最初見たときは「ベンチマークだしな」と思った。
「マルチステップ関数呼び出し」の精度が上がるということは、音声エージェントがバックエンドAPIを連鎖して叩けるようになるということで、これはかなり実用に近い話だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。

「モデルが良くなった」だけでは終わらない話
ここからが本題。
モデル側の進化は確かに速い。でも実際の業務環境に音声エージェントを組み込もうとすると、モデルとは別の泥臭い問題が山積みになる。
Teams統合の現実
たとえばMicrosoft Teamsに音声エージェントを組み込むケースを考えてほしい。
Teamsには公式のBot APIがある。ただし、あれはトランスクリプション・録画・ミーティングノート向けに設計されたものだ。2秒以内の応答、割り込み処理、全参加者のリアルタイム音声認識が必要なエージェントには、構造的に向いていない。
この問題への対処として、MacのTeamsクライアントとLinux GPUサーバーを繋いで音声エージェントを動かすアーキテクチャがある。PulseAudioの仮想オーディオデバイスとWebSocketリレーを自前で構築するアプローチだ。
具体的には:
- teams_speaker(null-sink):Teamsのスピーカー出力を仮想デバイスに流し込む。null-sinkはPulseAudioが自動で「.monitor」ソースを作るので、そこからリアルタイムPCMストリームとして読み取れる
- teams_virtual_mic(null-sink)+ teams_mic_input(virtual-source):TTSが生成した音声をTeamsのマイク入力として送り込む
- WebSocketリレー:MacとLinux間をSSHトンネル越しに繋ぐ
- faster-whisper(CUDA):GPU側でSTTを実行。MacのオンデバイスSTTより高速で正確
ウェイクワードから最初の音声応答まで通常2秒以下を実現できる。
Teamsには完全に透過的に見える。仮想デバイスと通信していることをTeamsは知らない。API申請不要。ボット登録不要。
ただし一つ罠がある。仮想デバイスはシステムのPulseAudioではなく、Chrome Remote Desktop(CRD)のPulseAudioセッション内に作る必要がある。CRDは独自の分離されたデーモンを走らせているので、標準外のソケットパスを検出してそちらに作る必要がある。
Azureのマネージド環境はどこまで楽になるか
もう一方の動きとして、Microsoft Foundry Agent Serviceがある。2025年5月にGA(一般提供)となり、機能拡充が続いている。
特に注目はHosted Agents。開発者がSemantic KernelやLangGraphなど任意のフレームワークで実装したエージェントを、コンテナとしてAzure上にデプロイできる。KubernetesやコンテナオーケストレーションはFoundryが管理してくれる。
ツール連携の充実ぶりも見逃せない:
- MCP(Model Context Protocol):リモートMCPサーバーへの接続
- Computer Use:UIを通じたコンピュータ操作
- Browser Automation:Playwrightを使ったブラウザ操作
- Azure AI Search / File Search:RAGの組み込み
- Function Calling / Azure Functions:カスタム関数との連携
- A2A(Agent-to-Agent)プロトコル:SAP JouleやGoogle Vertex AIとのクロスクラウド連携
30以上のモデルをコード変更なしで切り替え可能。Gemini 3.1 Flash Liveのような高精度音声モデルと、このFoundryのツール連携基盤を組み合わせると何が起きるか。
「音声で指示を受け、バックエンドシステムを自律的に操作して、結果を音声で返す」エージェントが、インフラをゼロから組まなくても作れるようになる。
Teamsの音声パイプライン構成、読んでて「よくここまで考えたな」と思った。
PulseAudioのnull-sink + monitor、ChromeRemoteDesktopのセッション分離まで把握して組み上げる構成だ。
これをClaude Codeでターミナルから対話的に進められたら相当時間が縮まるはずで、そこが気になっている。
2つの流れの交差点
Googleがモデル側で精度と低遅延を解決しようとしている。Microsoftがインフラ側でデプロイと連携の複雑さを吸収しようとしている。
ただし現時点では「モデルとクライアント間のインフラギャップ」は埋まっていない。Teamsのような既存クライアントに低遅延で組み込もうとすると、依然として泥臭いオーディオパイプラインの自前構築が必要になる。
このギャップが埋まるまでの間、先行して組み上げた開発者が優位に立つ。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
実際の開発にどう関係するか
「音声エージェントを作ろう」と思ったとき、何から始めるか
まず整理しておきたいのは、音声エージェント開発の「レイヤー分け」だ。
レイヤー1:モデル(APIで解決)
- STT(音声→テキスト)
- LLM推論(意図理解・関数呼び出し)
- TTS(テキスト→音声)
- Gemini 3.1 Flash LiveならSTT〜LLM〜TTSが一体化したAPIとして提供される
レイヤー2:オーディオパイプライン(自前 or ライブラリ)
- マイク入力のキャプチャ
- VAD(音声区間検出)
- エコーキャンセレーション
- 既存クライアント(Teams等)との音声ストリーム統合
- ここが今の主戦場
レイヤー3:エージェントのホスティング・ツール連携(マネージドで解決しつつある)
- バックエンドAPIとのセキュアな連携
- MCPによるツール統合
- スケーリング・ライフサイクル管理
- FoundryのHosted Agentsで吸収できる部分
知っておいたほうがいいこと
- Gemini Live APIへのアクセスはGoogle AI Studioから。エンタープライズ向けはGemini Enterprise for Customer Experienceが別ルート。用途によって入口が違う
- SynthIDの透かしは自動付与。生成音声を使ったプロダクトを作るなら、これが入ることを前提に設計する
- Teamsへの統合は公式APIでは限界がある。2秒以内応答・割り込み処理が必要なら、オーディオパイプラインを自前で組む選択肢を視野に入れる
- FoundryのHosted AgentsはパブリックプレビューでMCPツールはGA済み。プロダクション投入するなら安定版とプレビューの区別をドキュメントで確認する
- ComplexFuncBench 90.8%の意味:マルチステップ関数呼び出しの精度が高いということは、音声エージェントが複数のバックエンドAPIを連鎖して叩けるということ。単一ツール呼び出しで止まっていたユースケースが広がる
Claude Codeとの関係
PulseAudioの仮想デバイス設定スクリプト、WebSocketリレーの実装、FoundryへのコンテナデプロイのためのYAML定義。どれもターミナル上でClaude Codeと対話しながら進めると、実装の試行錯誤が速くなる。
音声パイプラインの構築は「動くか動かないか」のデバッグが多い。ターミナルから離れずに「この設定だとCRDのソケットパスを取れないんだけど」みたいな相談ができる環境は、地味に効く。
「モデルが良くなった」ニュースを見るたびに「で、インフラはどうするの」と思う癖がついてきた。
Gemini 3.1 Flash Liveの精度向上は本物だと思う。ただ、それを既存の業務ツールに組み込む泥臭さは、モデルが良くなっても消えない。Foundryみたいなマネージド基盤が成熟すれば話は変わるけど、今はまだ「自分でパイプラインを組める人」が先に動ける状況だ。
よくある質問
Q1. Gemini 3.1 Flash Liveは開発環境でどのように利用できますか?
Google AI StudioのGemini Live APIからアクセスできる。複雑なマルチステップの関数呼び出し(ComplexFuncBench Audioで90.8%)に対応しており、音声入力を受けながら複数のバックエンド関数を連続して呼び出す処理が可能だ。トーン理解も改善されており、話者の感情(苛立ち・混乱)を認識して応答を動的に調整できる。生成された音声にはSynthIDによる電子透かしが自動で埋め込まれるため、プロダクト設計時にこれを前提として組み込む必要がある。エンタープライズ向けはGemini Enterprise for Customer Experienceが別ルートで提供されている。
Q2. Teamsに低遅延の音声エージェントを組み込む際の課題は何ですか?
TeamsのBot APIはトランスクリプション・録画・ミーティングノート向けに設計されており、2秒以内の応答や割り込み処理が必要なリアルタイムエージェントには構造的に向いていない。対処法として、PulseAudioの仮想オーディオデバイス(null-sink)を使ってTeamsの音声ストリームをインターセプトし、WebSocketリレーでMacとLinux GPUサーバーを繋ぐアーキテクチャが有効だ。注意点は、仮想デバイスをシステムのPulseAudioではなくChrome Remote Desktop(CRD)のPulseAudioセッション内に作る必要があること。CRDは独自のデーモンと非標準ソケットパスを使っているため、スタートアップスクリプトでこれを自動検出する処理が必要になる。
Q3. Microsoft Foundry Agent ServiceのHosted Agentsとは何ですか?
開発者がSemantic KernelやLangGraphなど任意のフレームワークで実装したエージェントを、コンテナとしてAzure上にデプロイできる機能(現在パブリックプレビュー)。KubernetesやコンテナオーケストレーションはFoundryが管理するため、インフラ設計のコストが大きく下がる。連携できるツールはMCP(GA済み)、Computer Use(プレビュー)、Browser Automation(プレビュー)、Azure AI Search(GA)、A2Aプロトコル(SAP JouleやGoogle Vertex AIとのクロスクラウド連携)など幅広い。30以上のモデルをコード変更なしで切り替えられるため、Gemini 3.1 Flash Liveのような新しい音声モデルへの乗り換えも容易だ。
まとめ
モデルの精度がついてきた。インフラのギャップはまだある。その差を埋めた人が先に動ける。
音声AIの実用化を「まだ早い」と思っていた人は、Gemini 3.1 Flash Liveの数字を一度見直してほしい。ComplexFuncBench 90.8%。200カ国展開。Verizon・The Home Depot導入済み。
モデル側の言い訳はなくなりつつある。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
