
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
70言語をリアルタイムで。音声AIの「つなぎ合わせ」が終わる日
DeepMindがGemini 3.5 Live Translateを発表した。
70種類以上の言語を、ほぼ遅延なしで相互に翻訳するモデルだ。
これまで音声認識・翻訳・音声合成を個別に構築していたパイプラインが過去のものになる。
End-to-Endのモデルが、人間の呼吸を読み、感情を乗せて別の言語で話し出す。
開発者にとって、これは「何を作るか」の前提が変わる出来事だ。

音声翻訳の歴史を塗り替える「Gemini 3.5 Live Translate」の全貌
Googleの翻訳は20年前に始まった。
毎月1兆語以上が翻訳され、数十億人に利用されている。
その最新の到達点がGemini 3.5 Live Translateだ。
70以上の言語を自動判別し、流暢な音声をリアルタイムに生成する。
従来のシステムは、話し手が言葉を終えるのを待つ「ターン制」だった。
このモデルは話し手が喋っている最中から、ストリーミング形式で翻訳音声を生成し続ける。
文脈の理解と即時性をモデル内部で調整している。
スピーカーから数秒遅れるだけで、通訳が隣にいるような体験を実現する。
抑揚、ペース、ピッチも再現する。
話し手の感情やニュアンスを維持したまま、別の言語として出力する。
騒がしい環境でも音声を拾うノイズ耐性も備えている。
多言語が混ざった入力も、モデルが自動で処理する。
このモデルはGoogle Meetでの同時通訳や、Google Translateアプリで展開される。
ビジネス向けユーザーから順次展開され、年内に広く利用可能になる。
開発者向けにはGemini Live APIを通じて提供される。
配車サービスの現場では、ドライバーと乗客のコミュニケーションを支えるテストも始まっている。
月間1,000万件以上の通話が行われる現場で、この技術が実戦投入されている。
しんたろー:
70言語対応でEnd-to-End。
今までWhisperなどを組み合わせて作っていたパイプラインが全否定された気分だ。
複雑なつなぎ込みのデバッグから解放されるなら、開発者は別の場所に時間を使える。
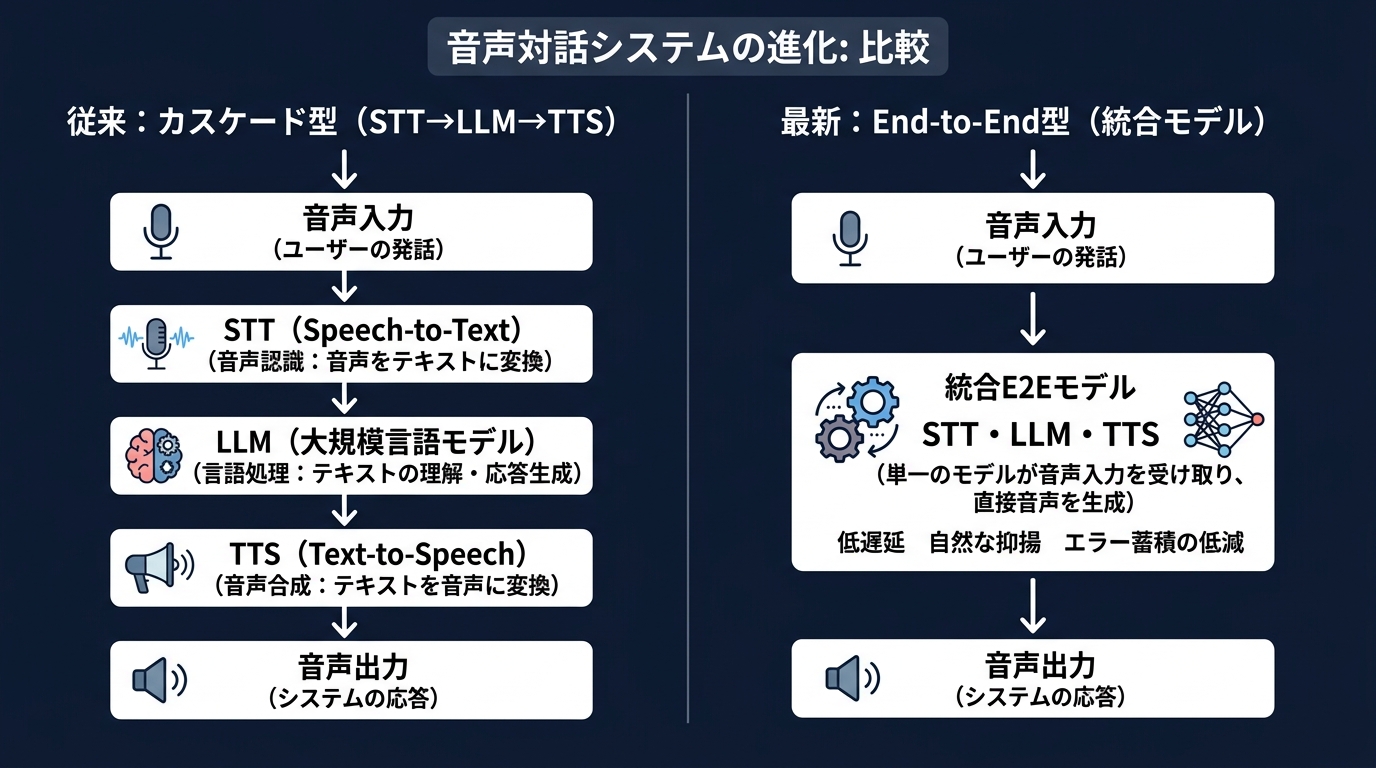
開発者目線で見る「カスケード型」から「End-to-End型」へのパラダイムシフト
今回の発表で注目すべきは、End-to-End(E2E)への完全移行だ。
これまでの音声AIアプリは、カスケード型が主流だった。
- STT(音声認識): 音声をテキストに変換する
- LLM(言語モデル): テキストを翻訳・加工する
- TTS(音声合成): テキストを音声に戻す
この3つの工程をつなぎ合わせるのが開発者の仕事だった。
しかし、この構造にはレイテンシと情報の欠落という弱点がある。
各工程でデータをやり取りするたびに、コンマ数秒のロスが生まれる。
STTでテキスト化した瞬間に、話し手の「怒り」や「悲しみ」といった非言語情報が削ぎ落とされていた。
Gemini 3.5 Live Translateは、この壁を壊した。
音声を入力として受け取り、直接、別の言語の音声を出力する。
中間でテキストを介在させないため、感情の同期が可能になった。
開発の難易度は「モデルの選定」から「ストリーミング体験の設計」へ移る。
APIを叩く回数が増えればエラーの確率も上がり、トークンコストも嵩む。
Gemini 3.5のような統合モデルが主流になれば、SDKを一つ読み込むだけで済む。
AgoraやLiveKitといったストリーミング基盤とGeminiを組み合わせる流れが加速する。
低レイヤーの音声処理はプラットフォームに任せ、ユーザーが自然に会話を始められるUXの細部に集中できる。
リソースをビジネスロジックのテスト駆動開発に全振りできる環境が整いつつある。
モデルのつなぎ合わせで消耗するのは飽きた。
Gemini 3.5のデモを見たが、あの「間」のなさは異常だ。
複雑なストリーミング処理をSDKに丸投げして、ビジネスロジックに集中したい。
Claude Codeに「Gemini Live APIのラッパー書いて」と頼むだけで、通訳エージェントが作れる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
僕らの開発はどう変わる?今すぐ意識すべき3つのアクション
モデルの性能を追いかけるフェーズは終わり、体験をどう実装するかのフェーズに入った。
第一に、リアルタイム・ストリーミングの抽象化に慣れることだ。
Gemini Live APIを直接叩くのもいいが、LiveKitやPipecatのようなマネージドな基盤を活用するほうが賢明だ。
インフラ層の複雑さを肩代わりしてくれるツールを使いこなし、早くプロトタイプを回す。
第二に、安全性と信頼性への対応だ。
Googleは今回のモデルに、AI生成音声であることを識別するSynthIDという透かし技術を導入している。
商用アプリを作る際、生成された音声がどう扱われるべきか、ユーザーにどう安心感を与えるかというガバナンスへの対応が信頼性を決める。
第三に、特定のユースケースにおけるUXの深掘りだ。
汎用的な翻訳機はGoogle自身が出している。
戦うべきは特定の文脈だ。
多言語での技術会議に特化した、専門用語に強い通訳エージェントなどが考えられる。
Gemini 3.5というエンジンを、どの車体に載せて、誰をどこへ運ぶのかというドメイン知識とUX設計が開発者の付加価値になる。
動画生成やアバター作成との組み合わせも選択肢に入る。
Geminiの低レイテンシ音声出力がAPIで取れるようになれば、リアルタイム・アバター対話も現実味を帯びる。
生成の質ではなく、応答の速さがユーザーの没入感を左右する。

インフラが強くなればなるほど、アイデアと実装速度が試される。
ThreadPostの開発でも、ユーザーが何もしなくていい状態を目指している。
音声AIも設定不要、ラグなし、自然であるべきだ。
これを実現するための武器が一つ増えた。
FAQ:Gemini 3.5 Live Translateに関する疑問
Q1: 従来のWhisper + LLM + TTSの構成と何が違うのか?
最大の違いはデータ処理の構造です。
従来の構成(カスケード型)は各工程を順番に実行するため、前の工程が終わるまで次が始まりません。
Gemini 3.5はEnd-to-Endモデルであり、音声を直接処理して翻訳音声を生成します。
文脈の理解と即時性をモデル内部で同時に最適化しているため、自然なリズムを実現できます。
Q2: 開発者がGemini Live APIを導入する際、最も注意すべき点は?
レイテンシとコストのバランス、そしてAPIの制限です。
リアルタイムストリーミングは、通常のテキストベースのAPIよりも通信量やサーバー負荷が高くなります。
プロトタイプ段階ではLiveKitなどのプラットフォームを経由して、実際の通信環境での挙動を検証することが不可欠です。
また、自動で挿入されるSynthID(透かし)の仕様が、自社のサービスポリシーに適合するかを確認する必要があります。
Q3: 動画生成やアバター作成にGemini 3.5は使えるか?
Gemini 3.5 Live Translate自体は音声翻訳に特化したモデルです。
現時点では、直接動画を生成したり、高度なリップシンクを行ったりする機能は含まれていません。
ただし、Geminiが生成した高品質で低レイテンシな音声を、HeyGenなどのリップシンクエンジンに流し込むワークフローは強力です。
今後は、この統合音声モデルを核として、リアルタイムな多言語アバター動画を実現するスタックが主流になります。
まとめ:つなぎ合わせる時代から、体験を編む時代へ
Gemini 3.5 Live Translateの登場は、音声AI開発の難所を一つ消し去った。
STTやTTSのモデル選定に悩み、レイテンシを削るためにコードをこねくり回す時間は終わる。
これからは、この統合モデルをどう使い、どんな驚きをユーザーに届けるかが問われる。
技術の進化は速い。
昨日までの正解が、今日にはレガシーになる。
だからこそ面白い。
より高く、より遠い場所を見据えて開発を続ける。
音声AIの「つなぎ合わせ」から「統合モデル」への転換期だ。
あなたのプロダクトをどう進化させるか、ThreadPostで議論する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
