
出た。ついに来た。
Claude CodeのデフォルトモデルがOpus 4.6になり、100万トークンのコンテキストウィンドウが標準搭載された。
本を何十冊も丸暗記できる記憶力だ。
しかも追加料金は0円に設定されている。
これでプロジェクトの全ファイルを投げ込めば、AIが勝手に全部理解して完璧なコードを書いてくれる。
そう思った開発者は、確実に痛い目を見る。
100万トークンは「ゴミ箱」ではない。
無計画なデータ投入は、プロジェクトを崩壊させる。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
物理的制約の崩壊と1Mコンテキストの衝撃
まずは事実と数字を整理する。
AnthropicがClaude Codeをアップデートした。
目玉はOpus 4.6とSonnet 4.6の100万トークン対応だ。
これまで200Kトークンを超えると発生していた割増料金が完全に撤廃された。
900Kトークンのリクエストでも、9Kトークンのリクエストでも、単価は全く同じだ。
デフォルトモデルも変更された。
何も設定しなくても、起動時から最も賢いOpus 4.6が立ち上がる。
コンテキストの壁が壊れ、画像やPDFの読み込み上限も100枚から600枚に跳ね上がった。
Anthropicの公式発表によると、長文検索精度のベンチマークであるMRCR v2では78.3%というスコアを叩き出している。
フロンティアモデルの中でトップの数値だ。
同発表によれば、長時間のコーディングセッションでも、過去の文脈が失われる「圧縮イベント」が15%減少した。
物理的な制約は完全に消え去った。
巨大なモノリスリポジトリでも、一度に全ファイルを読み込ませることは可能になった。
だが、ここからが本題だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
しんたろー:
1Mコンテキスト追加料金なしはバグレベルの価格破壊。
でもこれ、初心者が「とりあえず全ファイル読み込み」を乱発してAPIコスト溶かす未来しか見えない。
ツールが進化しても、使う側の設計力が試されるフェーズに入ったな。

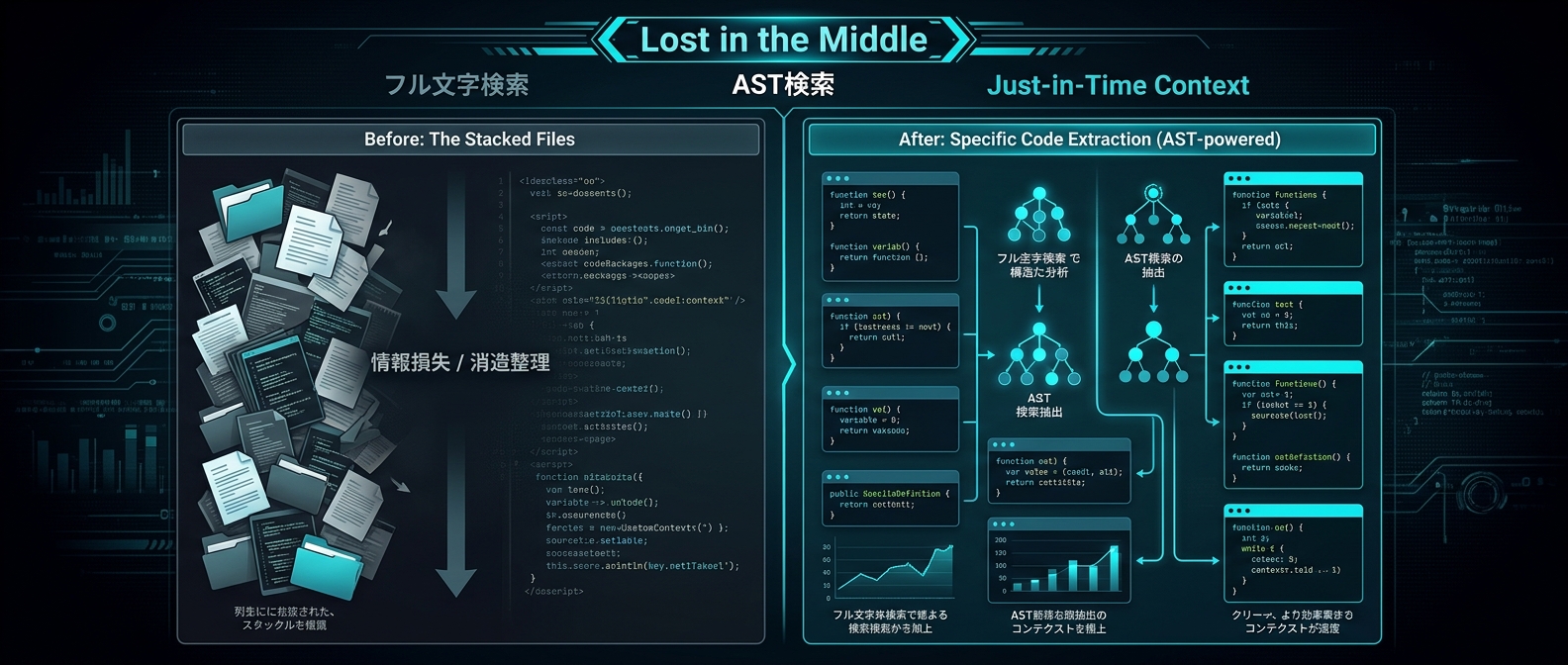
Lost in the Middleの絶望とコンテキストの罠
100万トークンの器を手に入れた今、僕らが直面するのは「Lost in the Middle」という絶望だ。
AIに情報を詰め込みすぎると、中間にある重要なデータを見落とす。
LLMの注意機構は、最初と最後の情報はよく覚えている。
しかし、真ん中の情報はスルーしがちだ。
コンテキストウィンドウが広がったからといって、この注意の偏りが解消されたわけではない。
むしろ、詰め込める量が増えたことで、ノイズに埋もれるリスクは極大化した。
「全部渡せば精度が上がる」は、現代のAI開発における最悪のアンチパターンだ。
複数のAI研究機関のレポートを統合したcrossSourceFindingsによれば、コンテキストの拡張と検索精度の低下はトレードオフの関係にある。
真のコンテキスト戦略は「Just-in-Time Context」だ。
タスクが要求する瞬間に、そのタスクに最小限必要な情報だけを注入する。
この原則を無視したエージェントは、ただのトークン浪費マシーンに成り下がる。
ここで注目される技術が、AST(抽象構文木)ベースのセマンティック検索だ。
文字ベースのナイーブなチャンキングはもう古い。
関数の途中で無理やり分割されたコードを渡されても、AIはロジックを正確に理解できない。
AST検索によるコンテキスト最適化
cocoindex-codeのようなAST検索ツールは、コードの構文構造を理解した上でインデックスを作る。
自然言語で「認証ロジックはどこ?」と検索すれば、プロジェクト全体から正確なコードブロックだけを抽出する。
これをAIエージェントに渡すことで、トークン消費を70%削減できるとcocoindex-codeの公式ドキュメントに記載されている。
100万トークンの真の価値は「全部読み込めること」ではない。
AST検索などで抽出した高品質なコンテキストを、溢れる心配なく安全に保持できる「器の大きさ」にある。
ノイズを排除し、純度の高い情報だけを100万トークンの空間に並べる。
AST検索で必要な関数だけ引っこ抜いて渡すアプローチが気になる。
コンテキストは「与える」んじゃなくて「取りに行かせる」設計にしないと破綻しそう。
1Mの器があっても、中身がゴミなら出力もゴミになる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
コンテキストエンジニアリングの実践
明日から僕らの開発ワークフローはどう変わるのか。
「とりあえず設定ファイルに全部書く」という怠惰なアプローチは捨てる。
プロジェクトの設定ファイルは常に300行以内に収めるのが鉄則だ。
最強のモデルと最大のコンテキストを常に使う必要はない。
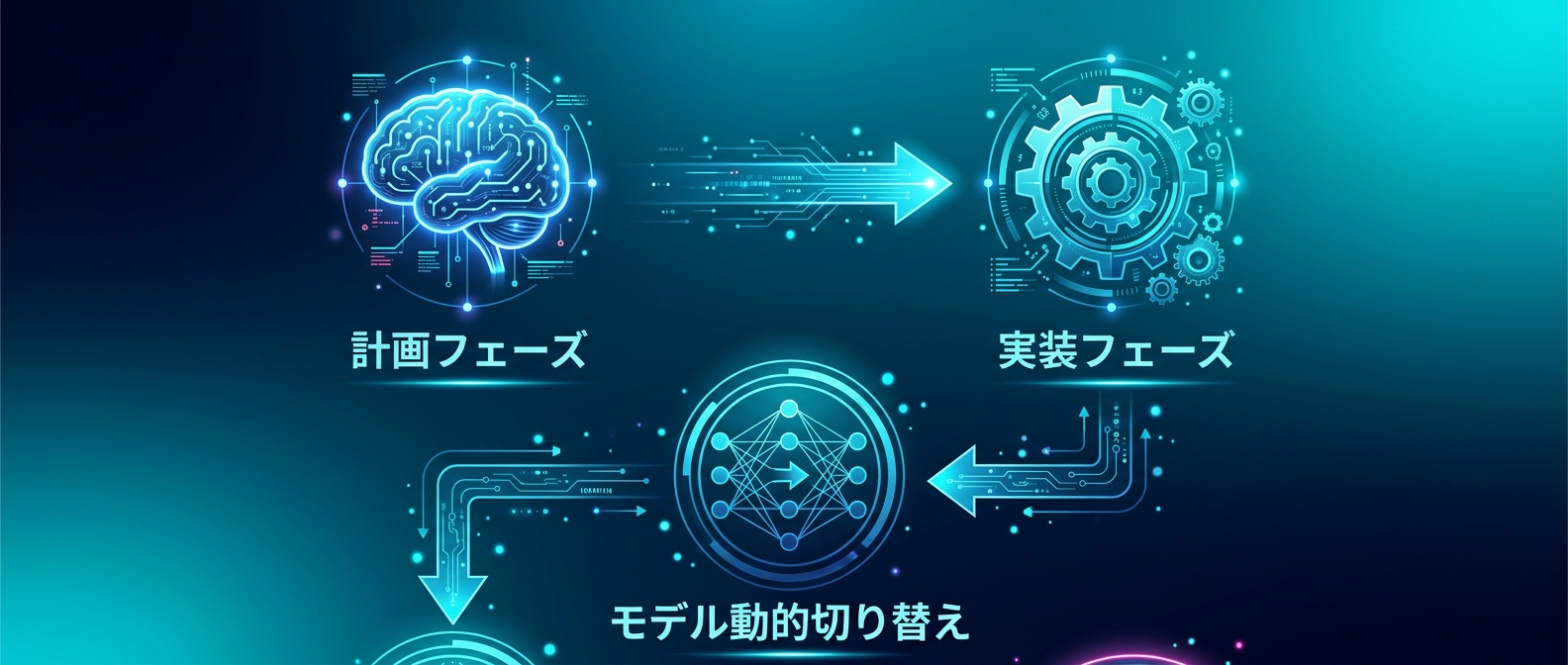
コストと品質を最適化するなら、モデルの動的切り替えが必須になる。
Claude Codeの「opusplan」コマンドは、まさにこのための機能だ。
アーキテクチャ設計や複雑なバグ調査を行う「計画フェーズ」では、推論力の高いOpus 4.6を使う。
日常的なコード修正やテスト作成の「実装フェーズ」では、高速なSonnet 4.6に切り替える。
この切り替えを自動化することで、「考えるときは賢く、作業するときは速く」が実現する。
さらに、エディタ上のLSPとAIのセマンティック検索を明確に使い分ける。
LSPとAI検索の使い分け
LSPはリアルタイムの構文エラーチェックや定義ジャンプなど、局所的で深い解析に使う。
一方、AIエージェントにはAST検索ツールを持たせ、プロジェクト全体の横断的な理解を任せる。
スキルの遅延評価(Lazy Loading)の導入も選択肢に入る。
AIのシステムプロンプトには「スキルの名前と説明」だけを書いておく。
実際のスキルの内容は、AIが「そのスキルを使いたい」と判断した瞬間にだけロードする。
データ分析でも同じだ。
生データを全量読み込ませるのではなく、メタ情報と操作結果のサマリーだけをAIに渡す。
AIはデータを保持するのではなく、何をどの順番で操作するかを推論するオーケストレーターとして機能させる。
100万トークンは、僕らを自由にしたのではない。
「必要な情報を、必要なタイミングで、最適なモデルに渡す」という高度なオーケストレーションを要求している。
コンテキストエンジニアリングこそが、これからの開発者のコアスキルになる。
このスキルを習得した開発者は、10倍の生産性を叩き出す。
しかし、私は昨日、モデルの切り替え設定を忘れてOpus 4.6で単純作業を続け、API代を30ドル無駄にした。
opusplanの自動切り替え、マジで快適そう。
ずっとOpusで作業してたらAPI代がエグいことになるし、Sonnetだけだと設計でボロが出る。
ツール側でフェーズごとにモデルをスイッチしてくれるのは、1人開発の生産性爆上がり案件。
よくある質問(FAQ)
Claude Codeで1Mコンテキストが使えるようになりましたが、プロジェクトの全ファイルを読み込ませても大丈夫ですか?
物理的には可能ですが、推奨されません。
大量の無関係なコードをコンテキストに詰め込むと「Lost in the Middle」現象が発生します。
AIが中間にある重要な情報を見落とし、ハルシネーションの原因になります。
また、従量課金の場合はAPIコストが増大し、レスポンスも遅くなります。
AST検索ツールなどを併用し、タスクに必要なファイルだけを「Just-in-Time」で渡す設計がベストプラクティスです。
100万トークンは、精査された情報を保持するための空間として活用します。
Opus 4.6とSonnet 4.6はどう使い分ければよいですか?
Claude Codeの「opusplan」コマンドを使うのがスマートです。
この設定を有効にすると、アーキテクチャ設計などの「計画フェーズ」では推論力の高いOpus 4.6が自動で選ばれます。
そして、日常的なコード修正などの「実装フェーズ」では、高速で軽量なSonnet 4.6に自動で切り替わります。
毎回手動でモデルを変更する手間が省け、コストと品質のバランスを最適化できます。
手動で切り替える場合は、タスクの複雑さに応じてOpus 4.6とSonnet 4.6を選択します。
単純なリファクタリングにOpus 4.6を使うのは、コストの無駄遣いです。
ASTベースの検索ツールは既存のLSPの代わりになるものですか?
いいえ、両者は完全に補完関係にあります。
LSPはリアルタイムの構文エラーチェックや正確な定義ジャンプなど「局所的で深い解析」に特化しています。
一方、AST検索ツールは「認証ロジックはどこ?」といった自然言語によるプロジェクト全体の「横断的なセマンティック検索」に優れています。
AIエージェントにはAST検索で全体像を把握させ、人間のエディタ上ではLSPを使うのが理想的な開発環境です。
両者を組み合わせることで、100万トークンのコンテキストを最大限に活かすことができます。
AIと人間の得意分野を分担することが、開発効率向上の鍵です。
コンテキストを制する者がAI開発を制する
100万トークンの圧倒的な暴力は、使い方を間違えれば自分を殺す刃になる。
コンテキストを制する者が、これからのAI開発を制する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
