
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIモデルの知能を100パーセント引き出す「ハーネス」の正体
Claude Codeが速く、的確に動く理由が明らかになった。
最新の報告で、AI開発の主戦場はモデルの性能からハーネス(制御層)の設計に移っている。
GitHubが公開したデータは興味深い。
同じClaude 3.5 SonnetやGPT-4oでも、制御側の設計でトークン効率とタスク解決率に差が出る。
SWE-bench Verifiedでのスコア向上とトークン消費量の削減は、モデルの進化ではなくエンジニアリングの成果だ。
僕ら開発者は、推論ハーネスの最適化に向き合う。
複数ソースが示す「効率化」の新しい定義
AI業界のトップランナーたちは、異なるアプローチで効率を追求している。
開発現場で注目されているのがエージェント用ハーネスの最適化だ。
これはモデルの知能をタスクへ適用するオーケストレーション層を指す。
最新のベンチマークデータでは、以下の4つの主要モデルで検証が行われた。
- Claude Sonnet 4.6
- Claude Opus 4.7
- GPT-5.4
- GPT-5.5
これらのモデルを共通ハーネス上で走らせた結果、事実が判明した。
標準的な環境よりも、ワークフローに特化して最適化されたハーネスの方が、トークン消費を抑えつつ高い解決率を示した。
特にSWE-bench Verifiedや、より難易度の高いSWE-bench Proにおいて、その差は顕著だ。
コンテキストウィンドウの管理、推論ステップの制御、MCPサーバーとの連携において、無駄なトークンを削ぎ落とすアルゴリズムが組み込まれている。
しんたろー:
モデルのパラメータ数ばかり追う時代は終わったと感じる。
1トークンあたりどれだけ仕事をしてくれるか、GitHubのハーネスの話はまさにその急所を突いている。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者の視点:なぜ「ハーネス」がすべてを決めるのか
僕がClaude Codeを叩いていて感じるのは、レスポンスの密度だ。
無駄な挨拶がなく、核心のコードを書き始める。
ハーネスは、AIモデルという巨大な脳を、特定の開発タスクという狭い出口に押し込むためのフィルターだ。
GitHubが公開したデータによると、彼らのハーネスは以下の3点を徹底している。
- 予測可能性:モデルの出力を開発者の期待に合わせる。
- トークン効率:コンテキストの情報を動的に選択し、コストを最小化する。
- 高速なフィードバック:ターミナル操作やファイル編集のループを最短化する。
彼らはTerminalBenchやSkillsBenchといった内部ベンチマークを使い、モデルがスキルをどう発動させるかをミリ秒単位で計測している。
一方で、個人開発者が直面するのは精度のトレードオフだ。
モデルを軽量化しようとすると、数学的な歪みが生じる。
「計算コストをケチった代償に、モデルの知能が壊れる」という現実がある。
1人SaaS開発ではAPIコストは死活問題だ。
自分でモデルを回すにせよ、APIを叩くにせよ、精度の代償をどうコントロールするかがエンジニアの腕の見せ所だ。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
僕らの開発にどう影響するか:実務へのアクションアイテム
この効率化の波を、自分のプロジェクトに取り込む必要がある。
自作のエージェントやAI機能を開発しているなら、トークン消費の動的最適化を優先する。
モデルに渡すコンテキストを固定せず、現在のタスクに必要な情報だけを抽出するロジックを組む。
GitHubの事例が示す通り、モデルの素の性能に頼るより、入力情報を整理する方が解決率は上がる。
これからの開発者に求められるのは、AIを魔法の箱として扱うことではない。
推論時のトークン効率と、学習時の数学的整合性だ。
この2つのレイヤーで発生する最適化のトレードオフを管理する、AIの調律師としての視点だ。
最後は泥臭い計測と実験に戻ってくる。
ツールが進化すればするほど、裏側にある理由を知っている人間の価値が上がる。
効率化の裏には必ず代償がある。

FAQ
Q1: なぜ実効バッチサイズが同じでも学習結果が変わるのか?
勾配累積を行う際、ミニバッチごとに計算されたlossの平均化処理や、低精度計算による丸め誤差が蓄積されるためだ。
特に学習率が高い場合、この誤差がパラメータ更新時に増幅され、フルバッチ学習の結果と乖離が生じる。
これを防ぐには、勾配累積のステップ数と学習率のバランスを調整し、必要に応じてfloat32での計算を検討する。
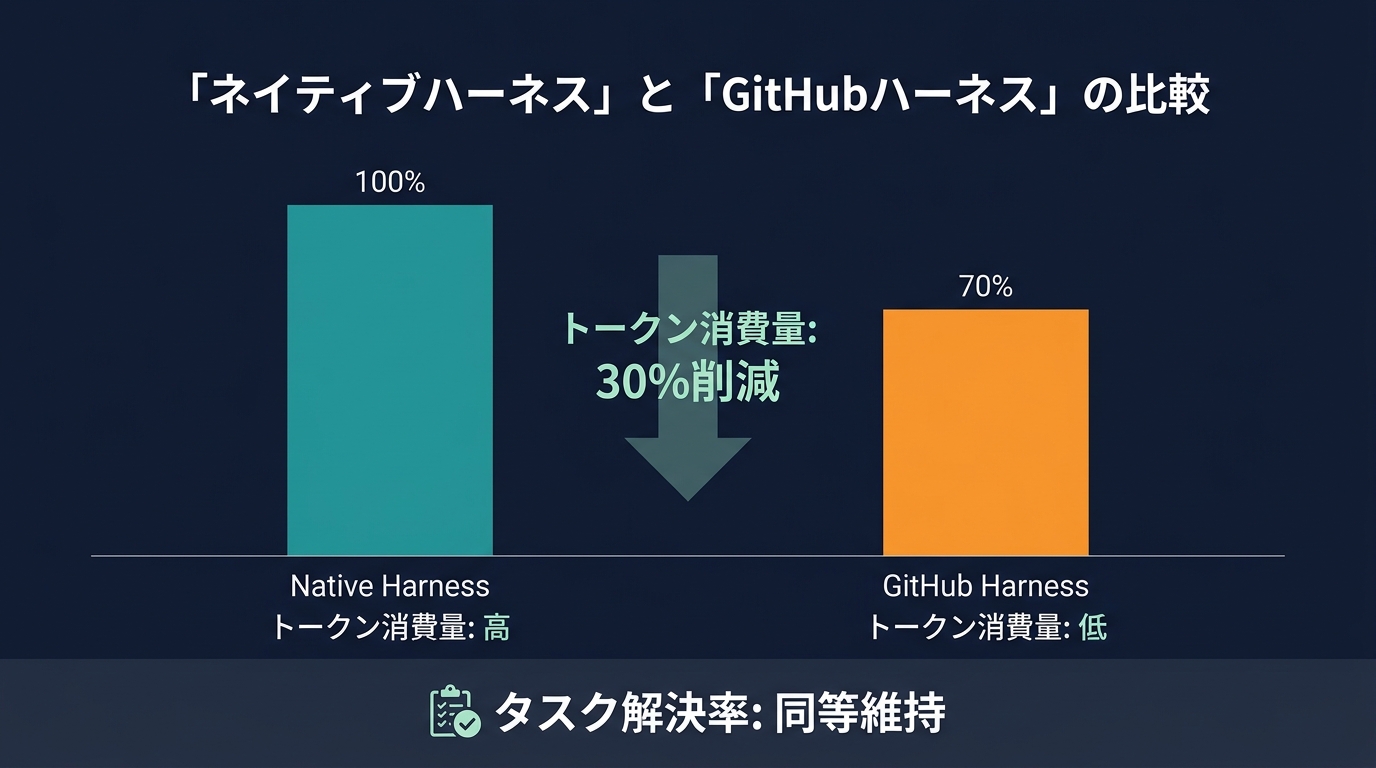
Q2: GitHub Copilotのハーネスを使うメリットは?
モデル提供元が提供するネイティブなハーネスと比較して、GitHubのハーネスは開発者のワークフローに特化して設計されている。
具体的には、SWE-benchなどのエンジニアリングタスクにおいて、同等の解決率を保ちながらトークン消費を抑えるよう最適化されている。
これにより、コストを抑えつつ、複雑なコードベースの修正を効率的に実行可能だ。
Q3: モデルのプルーニングはいつ行うべきか?
モデルの推論速度やメモリ使用量に制約があるデプロイ環境へ移行する直前に行うのが一般的だ。
不要なパラメータを削ぎ落とした後、ファインチューニングで精度を回復させることで、モデルの知能を維持したまま計算コストを削減できる。
開発初期から行うのではなく、ベースモデルの性能を出し切った後の最適化フェーズとして位置づける。
効率化の先にある「1人SaaS」の完成形
AI開発の焦点は、制御と効率へとシフトした。
モデルの巨大さに圧倒される必要はない。
必要なのは、その知能をいかに無駄なく、正確に、自分のコードへ変換するかという技術だ。
GitHubが示したハーネスの重要性を統合して、自分だけの最適な開発パイプラインを組み上げる。
それが、これからの1人開発を支える戦略になる。
AIの効率化の裏側にある技術的トレードオフを理解し、開発パイプラインを最適化したい方は、ぜひThreadPostをチェックしてほしい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
