
AI開発の主戦場が、静かに、しかし決定的に変わった。
昨日までは「どのモデルが一番賢いか」というベンチマークの殴り合いだった。
今は「いかに安く、予測可能なコストで、その知能を使い倒すか」の勝負だ。
Claude Codeの最新アップデート、OpenAIが発表した次世代モデル群、そしてNVIDIAの新しいルーティング技術。
これら複数の動きを繋ぎ合わせると、一つの明確な答えが浮かび上がる。
モデルの性能を追うのをやめて、コストの制御を設計の核に据える時が来た。
数字がそれを証明している。
性能が上がっても、コストが予測不能なら、プロダクトとして成立しない。
1人SaaS開発を実践する立場から、この巨大な変化の波を解剖する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
効率と予測可能性が支配する新しいAI開発の標準
AI業界の勢力図が塗り替えられている。
主要プレイヤーたちは一斉に「コストの透明性」と「推論の効率化」に舵を切った。
Claude Codeがバージョン2.120.0へと進化した。
このアップデートは、エージェントとしての動作の安定化と、無駄なトークン消費を抑えるためのリトライ制御の最適化を指す。
OpenAIは役割の異なる3つのモデルを提示した。
太陽、地球、月。
それぞれが異なるコスト構造と性能を持ち、開発者が用途に合わせて選別する。
最上位モデルの Sol は、長時間のエージェント作業や複雑な推論に特化している。
中位の Terra は、前世代のトップモデルと同等の性能を維持しながら、価格を 50パーセント にまで抑えた。
そして最安の Luna は、速度とコストを極限まで追求している。
同じタスクをこなすために必要な 出力トークン数 は、前世代と比較して 3分の1 にまで削減された。
「賢くなった」のではない。「同じ仕事を、より少ない手際でこなせるようになった」のだ。
プロンプトキャッシュの仕組みも変わった。
新しい設計では、開発者が キャッシュ区切り(cache breakpoint) を明示的に指定できる。
キャッシュの保持時間は 最低30分 と保証される。
この設計変更には代償がある。
キャッシュへの書き込みコストは、通常の入力単価の 1.25倍 に設定された。
一方で、キャッシュからの読み出しは 9割引き の単価が適用される。
一度高いコストを払って記憶させ、それを何度も使い回すことで利益を出す構造だ。

しんたろー:
OpenAIがAnthropicのキャッシュ設計に寄せてきた。
「自動でよしなにやるが、いつ課金が跳ねるか分からない」という甘えが許されなくなった。
開発者に「どこを固定して、どこを動かすか」という設計の責任が委ねられた。
これでようやく「AI破産」の恐怖から解放されて、まともな事業計画が立てられる。
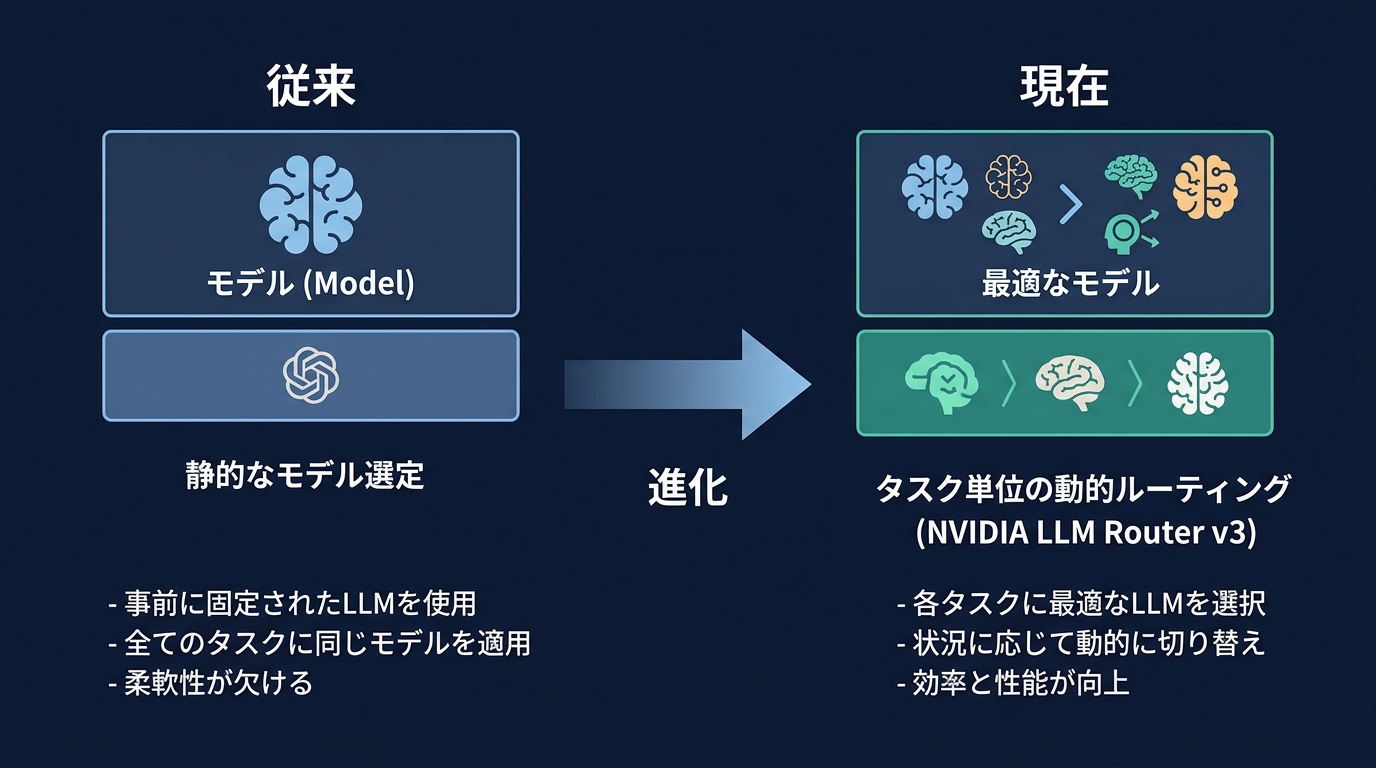
開発者の視点が「モデル選定」から「動的ルーティング」へシフトする理由
モデルが安くなり、キャッシュが明示的になった。
開発者は、NVIDIAが提示した LLM Router v3 のような、プロンプト単位の自動振り分け技術を活用する。
これまでの開発は、プロダクト全体で「このモデルを使う」と決める静的なものだった。
これからはリクエストごとに「このプロンプトはどのモデルへ投げるべきか」をリアルタイムで判断する。
NVIDIAのルーティングシステムは、内部に Qwen3.5-0.8B のような超軽量のエンコーダーを持っている。
ユーザーからプロンプトが届いた瞬間、この軽量モデルが「この内容はどのモデルなら正解できるか」を予測する。
要求される精度を満たしつつ、最もコストが低いモデルを自動で選択する。
この仕組みで重要な変数が 許容度(tolerance) だ。
最高性能のモデルの予測スコアから、どれだけの乖離を許すかという設定値だ。
この値を調整することで、コストと品質のトレードオフを能動的にコントロールする。
単純なコード生成やテキストの引用要求であれば、上位モデルと下位モデルのスコア差は小さい。
システムは迷わず最安のモデルを選択する。
逆に、複雑な論理推論や、高度な数学的判断が必要な場合は、スコア差が大きく開くため、高価な上位モデルへとルーティングされる。
動的ルーティングを導入することで、品質を維持したままコストを 数割から半分以下 にまで削減できる可能性がある。
これは、1人SaaS開発者のようなリソースの限られた人間にとって死活問題だ。
Claude Codeのようなエージェントツールも、この流れを汲んでいる。
エージェントは背後で何度もツール定義やシステムプロンプトを送信する。
これらを適切にキャッシュし、さらにタスクの難易度に応じてモデルを使い分けるロジックが組み込まれれば、運用コストは下がる。
向き合うべきは、「プロンプトの書き方」だけではない。
「どの情報をキャッシュの壁(breakpoint)の向こう側に置くか」
「どの程度の精度低下を許容して、コストを削るか」
こうした、よりアーキテクチャに近い判断が求められている。
Claude Codeを毎日回していると、APIの請求書が気になる。
特にデバッグのループに入った時、同じコンテキストを何度も送り直す無駄がある。
NVIDIAのルーターみたいに、「これ、安いモデルでもいけるんじゃね?」という判断を自動でやってくれるレイヤーが、Claude Codeの内部にも標準搭載される日は近い。
自分でルーティングロジックを書くのは面倒だが、ライブラリ化されたら即導入したい。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
AIエージェント運用の実務に直結する3つのアクション
この技術的なシフトを受けて、開発に取り入れるべきアクションは明確だ。
第一に、 システムプロンプトとツール定義の完全な固定化 だ。
新しいキャッシュ制御の仕組みでは、1文字でも変更があればキャッシュは無効化され、1.25倍の書き込みコストが発生する。
動的な値をシステムプロンプトに埋め込むのは悪手だ。
動的なデータは必ずメッセージの後半、キャッシュ区切りの後に配置する設計を徹底する。
第二に、 タスクの難易度によるティア分け の実施だ。
全ての機能を Sol や Claude 3.5 Sonnet で動かす必要はない。
要約、翻訳、単純なフォーマット変換は Luna や他の軽量モデルにオフロードする。
アプリケーション側に「難易度判定レイヤー」を設けることが、長期的な利益率を左右する。
第三に、 許容度(tolerance)の概念をプロダクトに組み込む ことだ。
ユーザーのプランや、リクエストの緊急度に応じて、使用するモデルの品質レベルを動的に変える。
「最高品質だが遅くて高い」モードと、「そこそこの品質で速くて安い」モードを、開発者が意図的に使い分ける設計だ。
OpenAIが導入した max reasoning effort や ultra mode のような、推論コストを上乗せして精度を買うオプションは、ここぞという場面に限定して使う。
エージェントが自律的にこれらのモードを使い分け始めた時、キャッシュ制御ができていなければ、一晩で数万円が溶ける未来もあり得る。
僕らの仕事は、AIにコードを書かせることだけではない。
AIという「高価な計算リソース」を、いかに効率よく、無駄なく、ビジネスの価値に変換するか。
その設計思想そのものが、開発者の市場価値になる。

モデルが賢くなるスピードより、コスト最適化の技術が進化するスピードの方がワクワクする。
「AIを使って何を作るか」のフェーズから、「AIを使ってどう利益を出すか」のフェーズに完全に移行した。
1人SaaS開発で一番大事なのは、開発を止めないことだ。
開発を止めないために一番大事なのは、API代で銀行残高がゼロにならないことだ。
FAQ
Q1: AIエージェントのコストを抑えるために、まず何から始めるべきですか?
まずは 明示的なキャッシュ制御 の導入だ。
システムプロンプトやツール定義など、リクエストごとに変わらない情報の直後に キャッシュ区切り(cache breakpoint) を設定する。
これにより、同じコンテキストを再送する際のコストを 90パーセント削減 できる。
その上で、単純なタスクと複雑なタスクを分類し、タスクの難易度に応じてモデルを使い分けるルーティングを検討する。
Q2: モデルの性能とコストのトレードオフをどう判断すればよいですか?
許容度(tolerance) という概念を導入する。
全てのタスクに最高性能のモデルを割り当てるのではなく、回答の正確性が絶対に必要なタスクと、速度やコストが優先されるタスクを定義する。
コード生成や特定の引用要求など、モデル間の性能差が出にくいタスクは軽量モデルに振り分ける。
論理的推論が必要なタスクのみ上位モデルを使う設定にすることで、品質を維持しつつコストを最適化できる。
Q3: キャッシュの書き込みコストが1.25倍になるのは、損ではないですか?
3回以上のリピート が発生するなら確実に得をする計算だ。
エージェントのループ処理や、同じチャットセッション内でのやり取りでは、同じシステムプロンプトが何十回も送信される。
1回目のリクエストで1.25倍を払っても、2回目以降が0.1倍(9割引き)になれば、累積コストは劇的に下がる。
予測可能性という観点でも、キャッシュが30分保持される保証があるため、コスト計算が立てやすくなる。
利益を生むためのAIアーキテクチャ設計
AI開発は「数学」から「経済学」へと移り変わった。
モデルのパラメータ数に一喜一憂するフェーズは終わった。
今見るべきは、トークンあたりの単価と、キャッシュのヒット率だ。
Claude Code 2.120.0で見られたような細かな最適化。
OpenAIによるモデルの三段活用。
NVIDIAの動的ルーティング。
これらは全て、AIを「魔法」から「冷徹な計算資源」へと変えるためのステップだ。
この変化に適応した開発者だけが、AIを使って持続可能なビジネスを構築できる。
僕も、自分のプロダクトである ThreadPost の裏側で、このコスト最適化のロジックを日々磨いている。
「賢いAI」を自慢する時代は終わった。
これからは「賢くAIを使う」開発者の時代だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
