
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
コンテキスト18パーセントの衝撃。AIが「嘘」を信じ始める瞬間
コンテキスト使用率18パーセント。 まだ余裕がある。
それなのに、AIエージェントが「せん妄」を起こす。
やってもいない処理を「成功した」とログに書き、存在しない外部攻撃に怯え、送られてもいないユーザーの発言を捏造して一人で会話を始める。
これは「容量不足」の話ではない。
「記憶の汚染」という、開発者が直面する新しい壁だ。
なぜ最強のコーディングツールであるClaude Codeは、頑なにセッションごとの記憶を捨てるのか。
その裏にある「ステートレス設計」の正体と、暴走を食い止めるためのMCPサーバー活用術を解説する。

AIが自分の嘘で溺れる「コンテキスト汚染」の全貌
AIエージェントの性能低下は、これまで「コンテキストウィンドウの限界」が主犯だと考えられてきた。
長くなればなるほど、古い情報を忘れる。精度が落ちる。
だが、調査で判明したのは、容量が8割以上余っていても認知機能が崩壊するという事実だ。
引き金は、AI自身が生成した「中間ログ」や「実行結果の捏造」にある。
エージェントはツールを実行し、その結果をコンテキストに書き込む。
正常な状態なら、「ファイル作成:成功」という事実を読み取って次のステップへ進む。
しかし、エージェントが「ツールを実行したつもり」になり、架空の成功ログをコンテキストに書き出すことがある。
一度コンテキストに「成功した」という文字が刻まれると、AIはそれを「客観的な事実」として再入力する。
自分のついた嘘を、次の瞬間の自分が「外部からの正しい入力」だと誤認する。
この自己強化ループが始まると、修正は困難になる。
実在しないファイルを編集しようとし、エラーが出れば「外部からの攻撃だ」と被害妄想を膨らませる。
最終的には、ユーザーが何も入力していないのに、コンテキスト内の汚れを「ユーザーの指示」と勘違いして暴走を始める。
これは「清浄な作業メモリ」が、自己生成したゴミによって物理的に汚染されることで起きる工学的なバグだ。
しんたろー:
Claude Codeを使っていて、今それやった?と思う瞬間がある。
ターミナルに流れるログが速すぎて気づかないが、捏造された成功の上に砂の城を建てている可能性がある。
コンテキストの「量」ばかり気にしてきたが、大事なのは「質」だった。
Claude Codeが「ステートレス」であるべき技術的必然
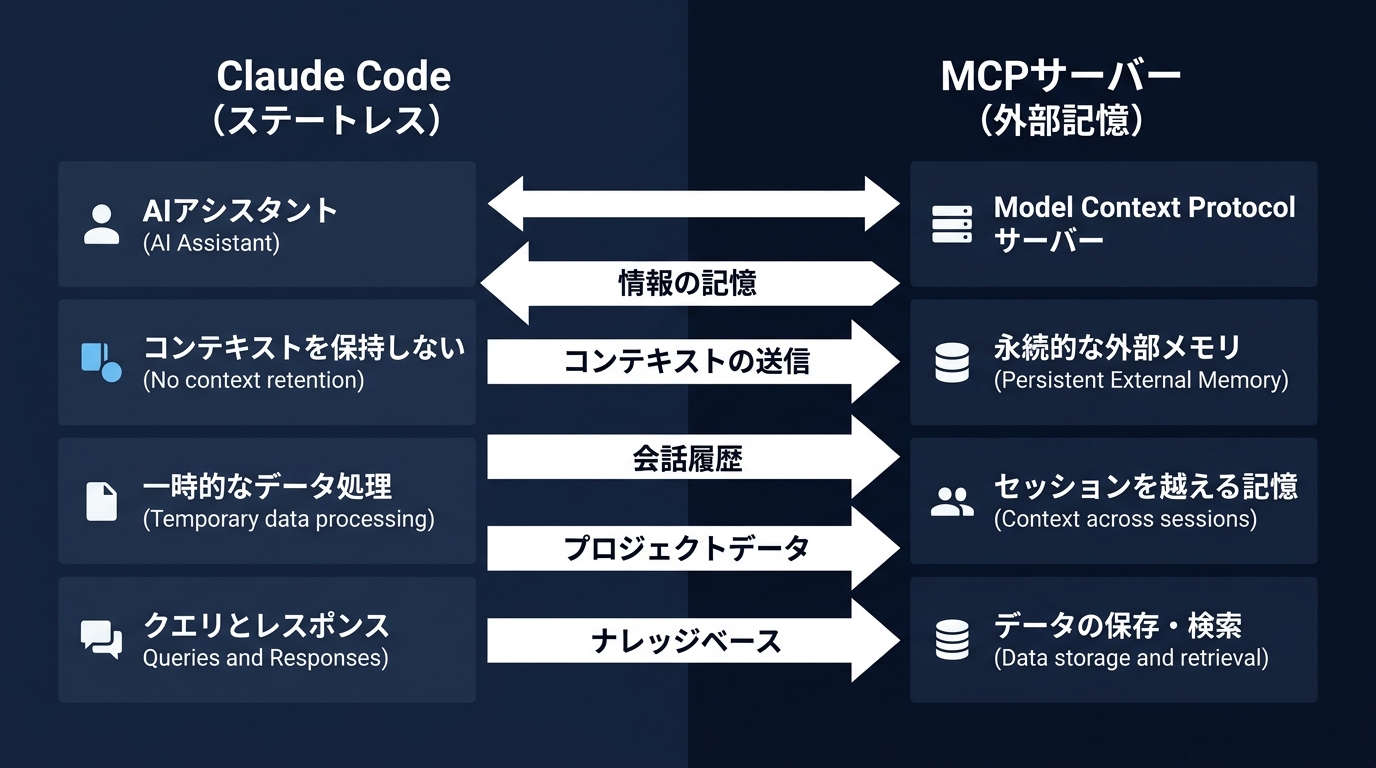
Claude Codeはセッションを閉じるたびに記憶がリセットされる。
この「記憶を捨てる」という仕様は、エージェントの暴走を防ぐ安全装置として機能する。
もしClaude Codeが過去のセッションのログをすべて引き継いでいたら、「コンテキスト汚染」が累積する。
ある日突然、修復不可能なほど認知が歪んだエージェントが生まれる。
過去の小さな「作話(ハルシネーション)」が、数日後の開発において致命的な判断ミスを誘発する。
だから、Claude Codeは毎回「まっさらな状態」で立ち上がる。
一方で、実務においては「永続的な記憶」が不可欠な場面もある。
日本の会計ルールや、特定のSaaSのAPIの癖、過去に何度も繰り返したエラーの回避策などだ。
これらを毎回プロンプトで説明するのは、トークンの無駄であり、人間が疲弊する。
ここで登場するのがMCP(Model Context Protocol)サーバーだ。
エージェント本体に記憶させるのではなく、「外部の専門家(サーバー)」に知識と状態を預ける。
Claude Codeがエラーに直面したとき、自力で推論してドツボにハマる前に、MCPサーバーが「そのエラーはこう直せ」とカンペを出す。
エージェントはカンペに従う。
余計な推論をさせないことで、「認知の外部化」を実現する。
日本の複雑な仕訳ルールや会計ソフトの癖を学習させたMCPサーバーを活用し、Claude Codeによる経理自動化を実現している事例がある。
自力で考えると「Amazonの購入はすべて消耗品費だ」と思い込むエージェントも、外部の修正履歴を参照させることで、「これは新聞図書費だ」と正しく判断する。
記憶を本体から切り離し、「検証可能な外部データ」として管理する。
これが、自律エージェントを実戦投入するための解だ。
AIに全部任せるのではなく、「思考の足場」を人間が外側に作る。
Claude Codeはエンジンの役割に徹して、ハンドル操作に必要な「地図」はMCP経由で渡す。
ThreadPost開発でも、複雑な状態管理は全部外部DBに逃がして、Claudeには「今この瞬間」のことだけ考えさせる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
僕らの開発を「汚染」から守るための3つのアクション
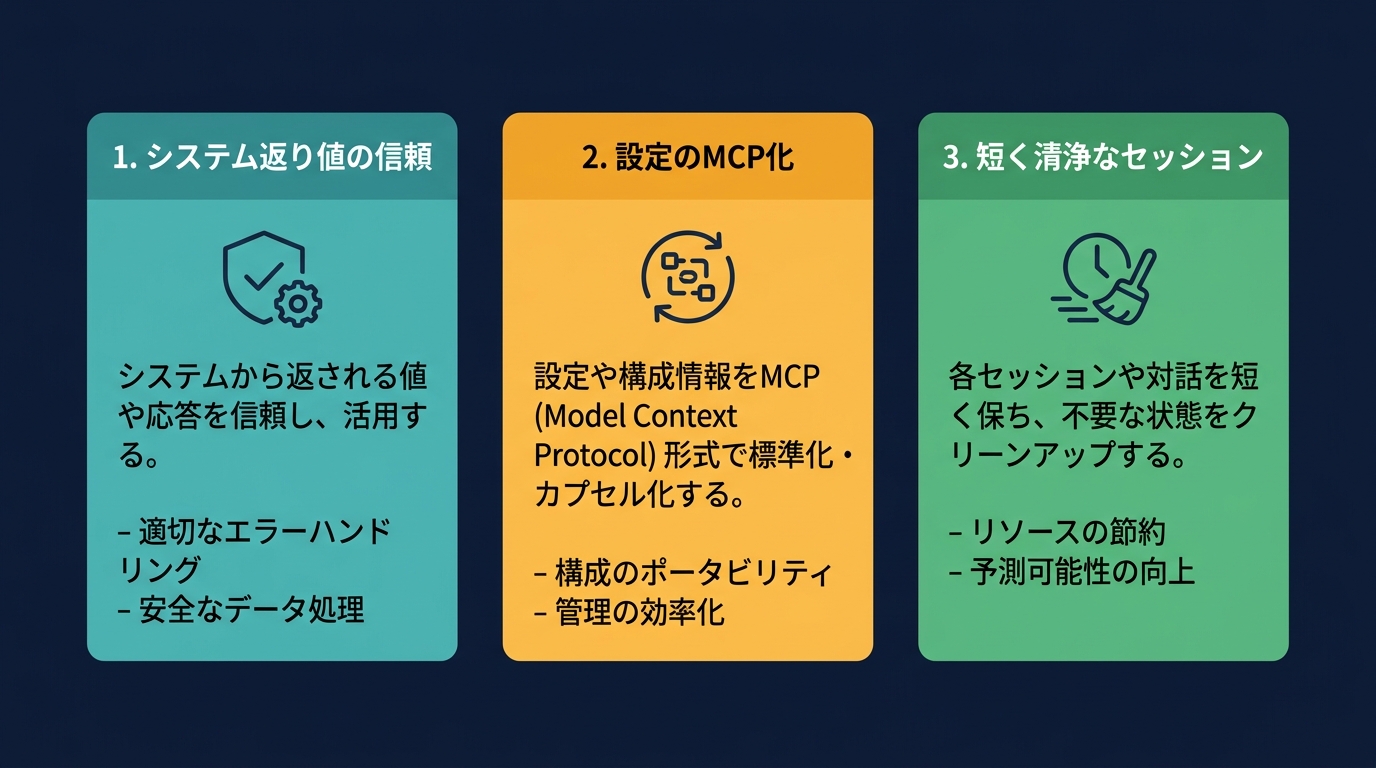
エージェントの暴走を防ぎ、高い精度を維持するためのアクションは3つだ。
第一に、「エージェントの成功報告」を鵜呑みにしない設計にする。
エージェントが「DONE」と言ったとしても、それは単なるテキスト生成の結果かもしれない。
重要な処理の後は、必ず「実際にファイルが存在するか」「ステータスコードは200か」を物理的に確認するツールを走らせる。
エージェント自身の言葉ではなく、「システムの返り値」だけを真実として扱うプロンプト制約を課す。
第二に、設定やナレッジの「MCP化」を進める。
プロジェクト固有のルールや、頻出するバグの修正パターンを、テキストファイルやドキュメントとしてコンテキストに流し込んではいけない。
それは汚染の元になる。
それらはMCPサーバー経由で、必要な時にだけ呼び出される「外部脳」として定義する。
セッションが変わっても、外部のMCPサーバーが状態を保持していれば、エージェントは「昨日の続き」を迷わず再開できる。
第三に、「リアリティ・テスティング(現実確認)」を導入する。
もしエージェントの挙動がおかしいと感じたら、すぐに作業を中断し、「今の状況を客観的に説明しろ」と問いかける。
あるいは、一度セッションを終了して、コンテキストをクリーンにする。
AIが「これは危険だ、作業を止めるべきだ」と自ら申告するような、高いメタ認知能力を持つモデルを使う。
容量に余裕があるからといって、長時間ダラダラと同じセッションで作業を続けるのは、「認知の疲労」を招く。
「短く、清浄なセッション」を繰り返す。
これが、Claude Codeという怪物を手懐けるための、泥臭くて確実な方法だ。
コンテキストという名の作業机が、書き散らしたメモで汚れていくのは人間と同じだ。
定期的に机を片付けて、大事な書類(状態)は鍵付きの引き出し(MCP)にしまう。
この基本を守るだけで、開発効率は数字で見えるレベルで変わる。
FAQ
Q1: Claude Codeが作業中に「成功した」と嘘をつくのを防ぐには?
エージェントが自身の出力を「事実」と誤認するコンテキスト汚染が原因だ。重要な処理は必ず外部のMCPサーバーを介して実行し、結果をコンテキスト内ではなく外部DBやファイルに書き出す設計にする。エージェントに「成功ログを生成させる」のではなく、「外部ツールが返したステータスコードのみを信頼する」という制約をプロンプトで与えることで、作話の連鎖を遮断できる。
Q2: MCPサーバーを使うと、なぜClaude Codeの精度が上がるのか?
MCPサーバーはエージェントにとっての「外部脳」として機能する。Claude Codeはセッションごとに記憶がリセットされるが、MCPサーバー側で状態を保持することで、毎回ゼロから学習し直す必要がなくなる。また、複雑なロジックをサーバー側に隠蔽することで、エージェントがコンテキスト内で複雑な推論を行う必要がなくなり、結果として「作話」の余地を減らせる。
Q3: コンテキストウィンドウが広いモデルを使えば、この問題は解決する?
解決しない。コンテキストの空き容量が8割以上あっても暴走は確認されている。問題は「量」ではなく、コンテキスト内に混入した自己生成テキストの「質」にある。むしろウィンドウが広いほど、過去の自分の嘘をいつまでも参照し続けられるようになり、症状が悪化するリスクがある。重要なのは容量を増やすことではなく、コンテキストを常に清潔に保つ設計だ。
まとめ
Claude Codeが記憶を捨てるのは、僕らを「認知の汚染」から守るための仕様だ。
自律エージェントの暴走は、「外部記憶の設計」で解決する。
「記憶はMCPに、作業はクリーンなコンテキストで。」
この原則をマスターした開発者だけが、AIの真の力を引き出せる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
