
AnthropicがClaudeの政治的中立性スコアを公開した。
Opus 4.7で95%。Sonnet 4.6で96%。
彼らはシステムプロンプトでモデルの安全性をコントロールしている。
モデルが「公平で安全」であることと、出力が「真実」であることは別の次元だ。
AIの挙動をブラックボックスのまま放置すれば、もっともらしい嘘がプロダクトに混入する。
LLMのハルシネーションは次トークン予測の仕様だ。
開発者が自前でAIの品質監査パイプラインを構築する動きが広がっている。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
ニュースの概要
AnthropicはClaudeが政治的な質問に対して、バランスの取れた回答を返すよう訓練している。
Opus 4.7とSonnet 4.6の評価テストでは、それぞれ95%と96%の中立性スコアを記録した。
これはキャラクター・トレーニングと、システムプロンプトによる指示の成果だ。
彼らは評価手法とデータセットも公開している。
外部のシンクタンクや研究機関と連携し、モデル挙動をレビューしている。
利用規約には明確なルールが設定されている。
欺瞞的な政治キャンペーン、フェイクコンテンツの作成、投票システムへの干渉は禁止されている。
自動化された分類器と専任の脅威インテリジェンスチームが監視している。
LLMは「真実」を最適化するシステムではない。
入力に対して「尤もらしい続き」の条件付き分布を近似している。
各時刻でモデルは語彙のスコアを算出し、確率分布へ変換して次のトークンを選ぶ。
訓練時に最適化されるのは、データセットの分布への近似だ。
現実世界の事実関係の正しさが、直接モデルの損失関数に組み込まれているわけではない。
出力がモデル内部で尤もらしいことと、現実世界と整合していることは別だ。
ハルシネーションは確率的な生成機構から生まれる現象だ。
モデル内部では高い確率を持つ出力であっても、データベースと照らし合わせると偽であることは珍しくない。
この「接地の欠如」が開発現場の課題だ。
開発現場ではAIガバナンスの構築が進んでいる。
Anthropicのコンソールには、APIリクエストの入出力の生データは残らない。
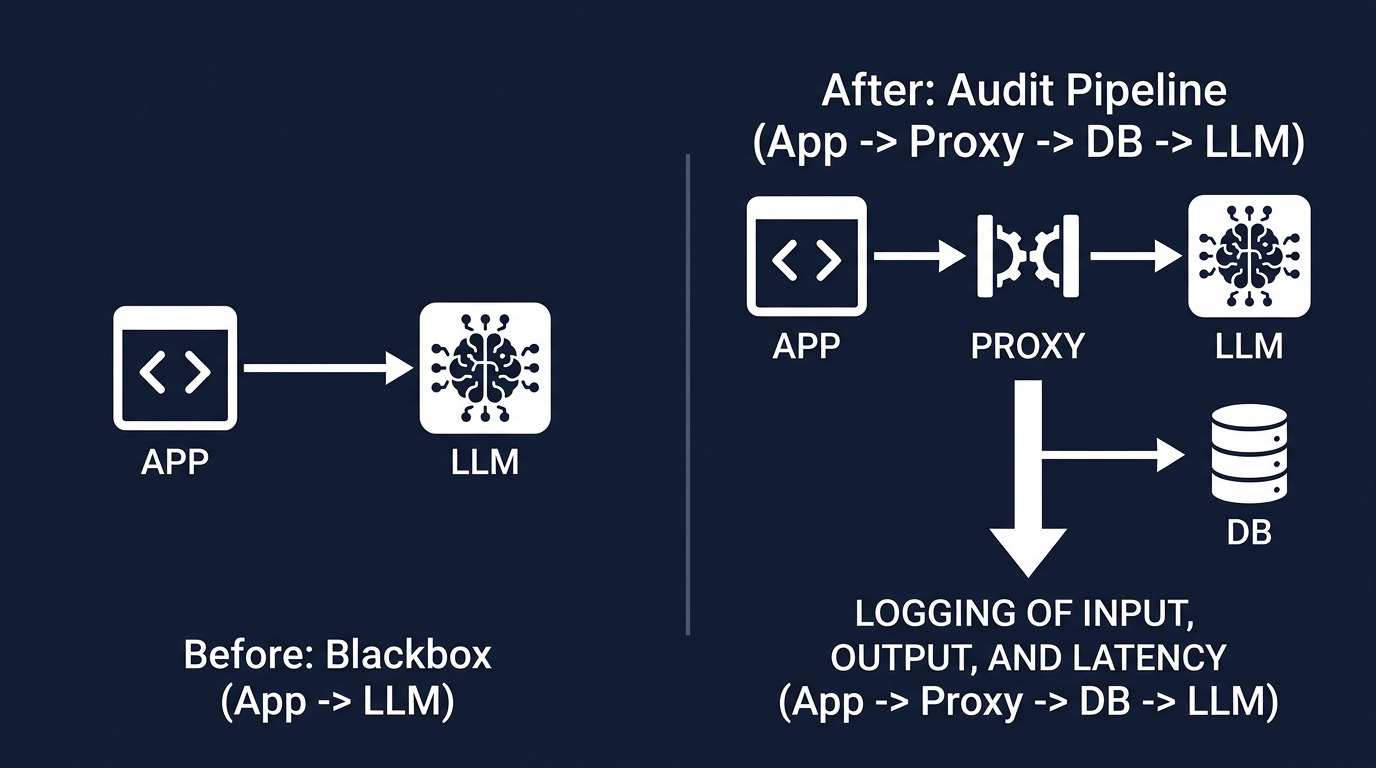
ブラックボックス状態を打破するため、監査パイプラインが構築されている。
非同期処理に強いバックエンドでプロキシ層を作り、リクエストをデータベースに記録する。
リクエストのハッシュ値、入力トークン数、出力トークン数、レイテンシ、コストを可視化する。
モデルの「安全性」はAnthropicが担い、出力の「真実性」は開発者が監査する。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
しんたろー:
ベンダーが安全性を高めるほど、開発側の確認コストが増えると感じる。
APIの裏側でシステムプロンプトが適用されると、こちらの指示が影響を受けることがある。
手元でログを取らないと本番環境での運用は難しい。

AI信頼性の二層構造
AIの信頼性は「モデルの安全性」と「出力の真実性」の二層で成立している。
Anthropicが担保しているのは前者だ。
彼らはモデルが偏った発言をしないよう、ガードレールを敷いている。
開発者がプロダクトに求めるのは「現実の仕様に合致した出力」だ。
LLMは入力に対して、出力の条件付き分布をモデル化している。
温度パラメータを調整しながら、語彙上のスコアベクトルを確率分布に変換している。
訓練時に最小化されるのは次トークン予測の損失であり、現実世界の真理判定ではない。
モデル内部で自然な文章が生成されても、それが現実と接地している保証はない。
言語的な尤もらしさと、世界に対する真偽を分離して考える必要がある。
世界の状況を、業務システムの仕様、データベースの制約として定義する。
LLMの出力が問題になるのは、その出力がこの基準となる世界に接地していないからだ。
文脈整合性が高くても、世界忠実度が低ければ、それはハルシネーションとなる。
生成AIの出力は、途中までは自然なのに結論がズレることがある。
これは言語モデルの内部での自然さと、現実世界に対する正しさが別物だからだ。
この二つの量を分けて考え、その差を乖離量として捉える視点が必要だ。
モデルにとっての正常は、世界にとっての誤りになり得る。
ハルシネーションは「AIの故障」ではない。
モデル分布と世界真理条件のズレによって現れる集合だ。
人間が「文章は自然なのに中身がおかしい」と感じるのは、この文脈整合性と世界忠実度の乖離だ。
LLMは埋め込み空間上で言葉の分布的関係を学習しているだけで、意味そのものを理解しているわけではない。
出力が現実のデータベースや業務ルールと一致するかは、LLMの管轄外だ。
内部で持っているのは、文字列の確率的なつながりだ。
この本質的な限界を理解せずに、AIの出力をそのまま信じるのはリスクを伴う。
Claude Codeを使用すると、この「もっともらしい嘘」が顕在化する。
生成されるコードの文法は完璧だが、プロジェクトの依存関係やライブラリの最新仕様と照らし合わせると動かないコードが出力されることがある。
これはモデルが確率の高い文字列の並びを出力した結果だ。
言語モデルとしての自然さと、プログラムとしての正しさは別の評価軸だ。
ベンダーが提供する安全性スコア95%は実績値だ。
だが、それは「政治的に中立な嘘」をつく可能性を否定するものではない。
ブラックボックス化されたLLMを制御するには、外側からの監視が必要だ。
モデルを信じず、データを信じる。
Claude Codeにリファクタリングを依頼すると、存在しないライブラリのメソッドを提案されることがある。
文脈が自然なため、一瞬正しいと錯覚しそうになる。
この「尤もらしさ」の制御が課題だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
監査パイプラインの構築
AIをプロダクションで使うなら、監査パイプラインの構築が選択肢に入る。
API呼び出しの記録をすべて手元に残す。
Anthropicの公式コンソールに加え、自前のプロキシ層を挟む手法がある。
アプリケーションとLLMの間に、リクエストを中継する専用のサーバーを立てる。
非同期処理に強いバックエンドを採用し、LLMの待機時間を効率的に捌く。
リクエストの中身、使用したモデル、プロンプトの全文を記録する。
レスポンスの全文、入力トークン数、出力トークン数、レイテンシも対象だ。
重複リクエストを検出するためのハッシュ値や、ミリ秒単位の処理時間も保存する。
リアルタイムなデータ購読と行レベルのセキュリティ制御ができるマネージドなデータベースを使用する。
フロントエンドの構築も進める。
モダンなフレームワークを使ってダッシュボードを構築し、エッジネットワークにデプロイする。
グラフ描画ライブラリを使ってコスト推移を可視化し、テーブルコンポーネントでリクエスト一覧を表示する。
どのプロジェクトで、どのモデルが、どれだけのトークンを消費しているかを把握する。
保存したデータに対する「品質スコア」の定義と算出を行う。
まずはシンプルなルールベースの減点方式を実装する。
品質スコアの算出には、基本となる50点満点からの減点方式を採用する。
期待される長さのパラメータを渡し、それを超えたら10点マイナス。
コードを要求したのに出力されなければ15点マイナス。
エラーパターンを検知したら5点マイナス。
このロジックでAIの不調を検知する。
精度を求めるなら、ルールベースとメタ評価LLMを組み合わせる。
消費コストが$0.05を超えるリクエストに対しては、別の安価なモデルを「評価者」として走らせる。
Haikuのような軽量モデルに、プロンプトとレスポンスを渡す。
「正確性」「完全性」「簡潔さ」「実用性」を基準に、品質を0〜50点で自動採点させる。
評価点数だけを数字として返させることで、データベースでの集計を容易にする。
メタ評価のプロンプトで評価基準を指示し、数字だけを返させる。
これにより、後続のデータ処理がシンプルになる。
評価用LLMが数字以外を返してきた場合に備えて、フォールバック処理を実装する。
ダッシュボードで日々の平均スコアやコスト推移をグラフ化する。
特定のプロンプトでスコアが急落した瞬間に、アラートを鳴らす仕組みを作る。
ブラックボックスなLLMを飼い慣らすための装備だ。
一人でSaaSを開発している個人にこそ、この可視化は有効だ。
コストと品質をコントロール下に置くことが、AI時代を生き抜く開発者の運用だ。
監査ログを確認すると、レイテンシが跳ね上がっているリクエストがある。
LLMが迷走して無駄に長い回答を生成しているケースが多い。
ルールベースの減点ロジックを組むことで、プロンプトの改善点が明確になった。

FAQ
Q1: LLMの回答が「もっともらしいが嘘」なのはなぜですか?
LLMは「真実」を生成するように設計されていないからだ。
入力された文脈に対して、統計的に「尤もらしい続き」を生成するように学習されている。
モデル内部の確率分布としては正解でも、それが現実世界のデータベースや仕様と一致するとは限らない。
これを「接地の欠如」と呼ぶ。
開発者は、モデルの出力が現実世界と整合しているかを検証する仕組みを別途用意する。
Q2: 個人開発でLLMの品質を管理するには何から始めればいいですか?
まずは「可視化」だ。
APIのリクエストとレスポンスをすべて自前のデータベースに保存するプロキシ層を作る。
レイテンシ、トークン数、簡易的な品質スコアを記録する。
回答の長さや、特定の拒絶パターンをルールベースでスコアリングするだけでも、精度低下の予兆は検知できる。
コストが許せば、軽量で安価なモデルを評価者として使い、回答の正確性を自動採点させるのが実用的だ。
Q3: プロキシ層を挟むとレイテンシが悪化しませんか?
アーキテクチャの設計次第だ。
非同期処理に特化したフレームワークを使えば、プロキシ自体によるオーバーヘッドは数ミリ秒レベルに抑えられる。
ログの書き込み処理を非同期のバックグラウンドタスクに逃がすことで、ユーザー体験への影響を最小化できる。
直接APIを叩いてブラックボックス化するリスクに比べれば、プロキシ層を挟むメリットは大きい。
可視化のない高速化は、リスクを伴う。
まとめ
AIの「尤もらしさ」に振り回されないために、パイプラインを可視化する。
モデルの安全性はベンダーに任せ、出力の真実性は開発者が自らの手で監査し、コントロールする。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
