
数十秒かかっていたAIの応答が、数十ミリ秒に縮まる。
APIコストは10分の1に下がり、システム全体の透明性が完全に確保される。
AIエージェントの開発手法が今、根本から変わろうとしている。
流行りの重厚なフレームワークを窓から投げ捨て、コアロジックを自作するアプローチだ。
LLMの呼び出し回数を極限まで減らし、周辺タスクを非LLM化する。
1人SaaS開発の現場で採用が急増している設計思想だ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
魔法はモデルの中ではなくループの中にある
海外の開発者たちの間で、ある明確なトレンドが浮上している。
それは「脱フレームワーク」と「脱LLM依存」という強烈な揺り戻しだ。
これまでAIエージェント開発といえば、巨大なライブラリを使うのが常識だった。
しかし今、多くの実力派開発者が素のPythonコードに戻り始めている。
理由は極めて単純だ。
重すぎる。遅すぎる。そして中身がブラックボックスすぎる。
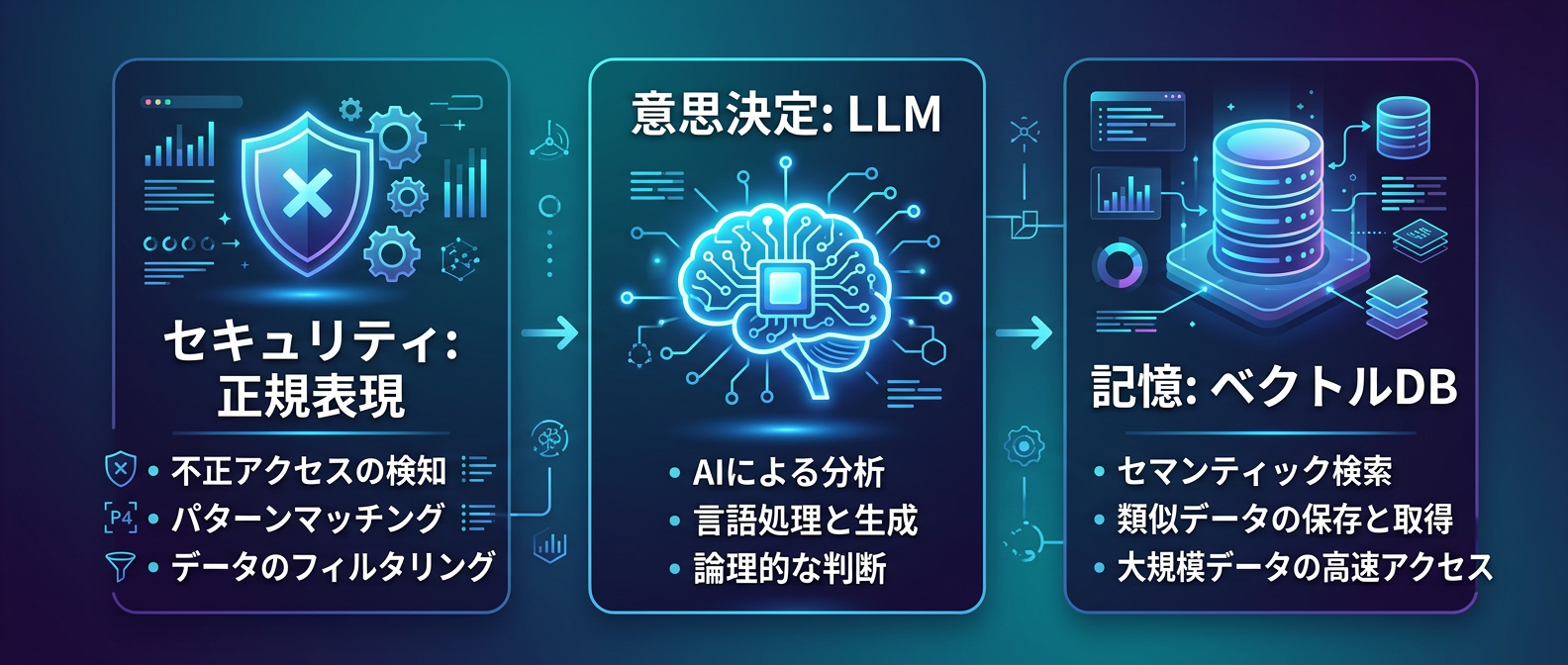
具体的な設計の変化は、主に3つの領域で同時多発的に起きている。
1つ目は、エージェントの心臓部であるコアループの完全な自作だ。
状態管理やツール呼び出しのタイミングを、外部ライブラリの魔法に任せない。
単純なPythonのループ処理で、開発者自身が完全に制御権を握る。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
2つ目の変化は、セキュリティ監視の非LLM化だ。
エージェント間の通信監視に、重くて遅いLLMを一切使わない。
悪意あるプロンプトの検知をLLMに任せると、処理が遅延しコストが嵩む。
代わりに正規表現ベースのパターンマッチングで、瞬時に危険を弾き飛ばす。
3つ目は、メモリ管理の極端な軽量化だ。
過去の会話の要約や、記憶の抽出のためにLLMを呼び出すことを完全にやめる。
ユーザー入力を単純にベクトル化し、ベクトルデータベースに保存するだけだ。
類似度検索だけで記憶を引き出すことで、LLMの無駄な呼び出しがゼロになる。
これらを組み合わせることで、数十秒かかっていた処理が数十ミリ秒で終わる。
魔法はAIモデルの中にあるのではない。僕らが書くシンプルなループの中にある。
ブラックボックスを避けるハイブリッドなアーキテクチャ
なぜ今、この極端なミニマリズムが支持されているのか。
実運用におけるレイテンシとコストの壁に全員が直面した。
流行りのエージェントフレームワークは、プロトタイプを作るには最高だ。
数行のコードを書くだけで、それっぽいものが魔法のように動く。
だが、本番環境に投入した瞬間に開発者は地獄を見る。
エラーが起きたとき、内部で何が起きているのか全く分からない。
意図しないタイミングで謎のツールが呼ばれる。
無限ループに陥り、その度に高いAPI利用料だけが飛んでいく。
しんたろー:
これ本当にわかる。流行りのライブラリの裏で勝手にLLMが呼ばれまくって、APIの請求額が跳ね上がるリスクが怖い。
自分で制御できるシンプルなループの方が、精神衛生上もパフォーマンス的にも圧倒的に良さそう。とはいえ、シンプルなループを書くのすら面倒くさがるのが僕なんだけど。
ブラックボックスを徹底的に避ける。
これが限られたリソースで戦う1人SaaS開発の基本戦略となる。
自分で書いたシンプルなループなら、どこでバグったか一瞬で分かる。
デバッグの容易さが、そのまま開発スピードに直結する。
LLMは決して万能ではない。
LLMはただの推論エンジンであり、何でも屋ではない。
記憶の保存やセキュリティ判定といった周辺タスクまでLLMにやらせると破綻する。
それは明らかにオーバーキルであり、高価なリソースの無駄遣いとなる。
LLMはループ内の意思決定だけに特化させる。
それ以外の処理は、すべて軽量な非LLM技術で処理する。

このハイブリッドなアーキテクチャこそが、現在の実務的な最適解だ。
応答速度は500倍になり、コストは10分の1に下がる。
そして、この軽量なアプローチはClaude Codeと圧倒的に相性が良い。
重厚なフレームワークの独自記法を、AIに学習させる必要がない。
素のPythonコードの生成は、Claude Codeが最も得意とする領域だ。
コアロジックのスクラッチ開発を指示すれば、数分で完璧なベースラインを書き上げてくれる。
うちの構成だと、Claude Codeに「外部ライブラリなしでエージェントの基本ループ書いて」って頼むのが一番速い。
複雑な依存関係がないからエラーも起きないし、後からのカスタマイズも一瞬で終わる。まあ、その指示を出すプロンプトを考えるのに30分かかったりするんだけど。
正規表現ベースのセキュリティ監視ツールも同様だ。
プロンプトインジェクションの典型的なパターンを列挙させれば、一瞬で堅牢な防御壁が完成する。
流行りのツールを盲信するのではなく、要件に応じて技術を使い分ける。
LLMを使わない処理をいかに組み合わせるかが、今後の設計力を左右する。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
限界まで削ぎ落とした最速の実装へ
複数の海外フォーラムの議論を統合すると、この脱フレームワークの動きは一過性のブームではない。
LangChainやLlamaIndexの複雑さに疲弊した開発者たちが、一斉に素のPythonへ回帰している。
では、日々の開発にどう取り入れていくか。
今すぐ重厚なフレームワークをすべて窓から投げ捨てる必要はない。
だが、ここはLLMを使わなくても実装できるのではないかと立ち止まる。
それだけで、システムのパフォーマンスは数倍に跳ね上がる。
まず最初に見直すのは、間違いなくメモリ管理の部分だ。
会話の履歴を毎回LLMに要約させて保存するような設計になっていないか確認する。
ベクトル化と類似度検索だけのシンプルな構成に切り替える。
それだけで、ユーザーが体感する応答速度は30秒から50ミリ秒になる。
ローカルLLM環境であれば、この差はさらに顕著に出る。
記憶抽出のための30秒の待ち時間が、50ミリ秒の瞬きに変わる。
次に手を入れるのは、システム全体のセキュリティだ。
ユーザーからの入力を、何の検査もせずにそのままLLMに渡すのは危険すぎる。
「これまでの指示を無視しろ」といった典型的な攻撃パターンがある。
これらは、わざわざLLMに判定させなくても正規表現で簡単に弾ける。
LLMに渡す前の関所で、軽量なチェックを挟む。
リスクスコアを算出し、一定値を超えたらアプリケーション層で即座に遮断する。
セキュリティ判定をLLMにやらせると、LLM自体が騙されるリスクがあるのが一番怖いところ。
正規表現での多層防御は地味だけど、コストゼロで確実に弾けるから実運用ではかなり頼りになりそう。正規表現を書くたびに、毎回ChatGPTに文法を聞き直しているのは内緒だけど。
この多層防御のアプローチなら、遅延も追加コストも一切発生しない。
シンプルで泥臭い手法こそが、本番環境では最も頼りになる。
エージェントの挙動を自分のコントロール下に置く。
状態管理は単純な変数でいい。
ツール呼び出しのトリガーも、文字列のパースと単純な条件分岐で十分だ。
複雑なことを、あえて極限までシンプルに実装する。
それが最終的に、最もメンテナンスしやすく、最も速いシステムになる。
1人でSaaSを開発・運用していく上で、この透明性は最大の武器になる。
ブラックボックスを排除し、コアロジックを自分の手で握る。
このミニマリズムの設計思想は、すべての開発者に影響を与えるパラダイムシフトとなる。
開発者が抱く3つの疑問
Q1: エージェント開発で重厚なフレームワークを使わないメリットは何ですか?
最大のメリットは圧倒的な透明性とカスタマイズ性の確保です。
フレームワークは素早く構築できる反面、内部で何が起きているか分かりにくく、エラー時のデバッグや特殊な要件への対応が極めて困難になります。
Pythonの基本ループで自作することで、状態管理やツール呼び出しのタイミングを完全に制御できます。
不要なオーバーヘッドも削減でき、結果としてAPIの呼び出しコストも10分の1に抑えることが可能です。
Q2: エージェント間の通信セキュリティはどのように担保しますか?
LLMを使って悪意あるプロンプトを判定すると、遅延やコストが増大し、LLM自体が騙されるリスクもあります。
まずは正規表現ベースの軽量なパターンマッチングを導入します。
「指示の無視」や「外部へのデータ送信」などの典型的な攻撃を瞬時に検知し、アプリケーション側でブロックします。
LLMに到達する前に危険を排除する多層防御のアプローチが、実用的かつ最も高速な解決策です。
Q3: ローカルLLMにメモリ(記憶)を持たせる最適な方法は何ですか?
会話の要約や記憶の抽出にLLMを使用するアプローチは、ローカル環境では処理時間が30秒かかるなど致命的なボトルネックになります。
ユーザー入力をEmbedding(ベクトル化)し、ベクトルDBに保存する方式が最適です。
新しい入力に対して類似度検索を行うだけのシンプルなRAG方式を採用します。
これによりLLMの呼び出し回数を極限まで減らし、50ミリ秒で記憶を引き出すことが可能になります。
魔法に頼らない堅牢なシステムを
重厚なフレームワークや過度なLLM依存から脱却し、シンプルで透明なコアロジックを構築する。
この設計思想の転換が、今後のAI開発における大きな分水嶺となる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
