
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
突然のAPI制限とコスト増の現実
ある日突然、いつも通り動いていた自動化ツールが止まった。
原因はAPIの無料枠のサイレント修正だ。
1日250回叩けていたはずのAPIが、突如として20回に激減した。
朝のバッチ処理が429エラーを吐き続け、システムが完全に沈黙した。
まじかよ。
無料APIに依存した個人開発は、プラットフォームの機嫌ひとつで即死する。
これが今のAI開発のリアルだ。
コストを抑えつつ、安定したシステムをどう維持するか。
僕ら開発者は今、根本的なアーキテクチャの見直しを迫られている。
無料枠の縮小と開発者の生存戦略
各社LLMの無料枠がこっそりと、しかし確実に削られている。
これまで個人開発者のインフラを支えていた太っ腹なプランが次々と姿を消している。
そんな中、新たな代替案として浮上したのが月間10億トークンという圧倒的な無料枠を持つAPIだ。
桁違いのトークン数が無料で使える。
しかし、当然ながら強烈な代償が用意されている。
1分間に2リクエスト、つまり2 RPMという極端なレート制限だ。
リアルタイムのチャットアプリには絶対に使えない仕様になっている。
一方で、情報収集や要約アプリを開発する層は、別の問題に直面している。
情報過多と、AIの出力のブレだ。
ただ単に記事を要約させるだけでは、本当に読む価値がある情報かどうかの判断ができない。
AIがもっともらしい嘘をつくハルシネーションの問題もつきまとう。
そこで、直接APIを叩いて即座に結果を返すのではなく、間に「事実抽出」のステップを挟む非同期パイプライン構造が注目されている。
大量の情報を一度中間データに落とし込み、そこから価値ある情報だけを精製するアプローチだ。
さらに、開発中のAPIコストを抑えるための新しいツールも登場している。
プロンプトを微調整するたびに課金されるのを防ぐため、ローカルでリクエストをキャッシュするプロキシツールだ。
同じリクエストならローカルDBから即座に返す。
これにより、テスト時のAPIコストを完全に0円に抑え込むことができる。
プログラミング未経験者ですら、AIを使ったバイブコーディングでこうした複雑なミドルウェアを作り上げる時代になった。
個人開発におけるAI活用は、単なるAPIの呼び出しから、周辺システムの構築へと完全にフェーズが移行している。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
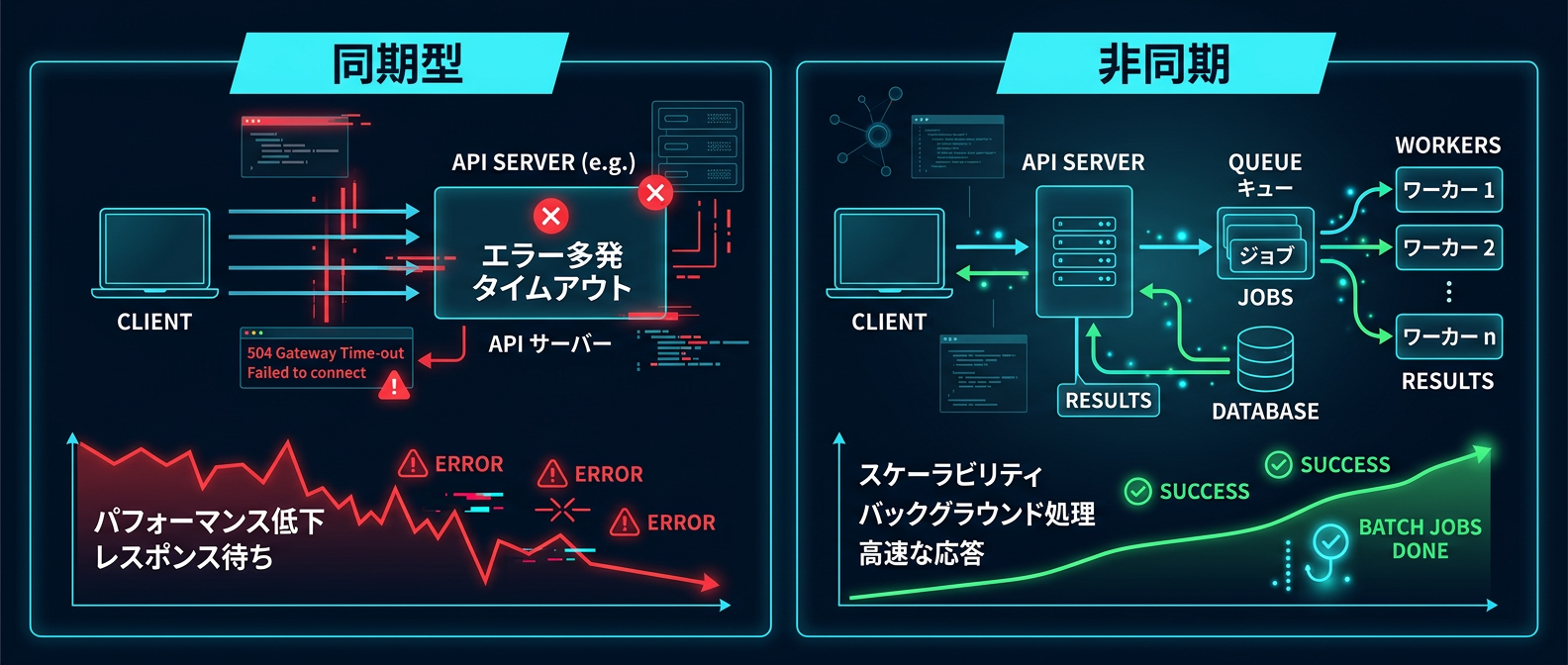
APIの制約をシステムで吸収するアーキテクチャ
月間10億トークンの無料枠は喉から手が出るほど魅力的だ。
でも2 RPMの制限をどう乗り越えるか。
答えは「非同期のバッチ処理」へのパラダイムシフトだ。
30秒に1回しかAPIを叩けないなら、システム側で待てばいい。
タイミングのズレを考慮して、31秒間隔でキューをゆっくり消化する。
ユーザーを待たせるのではなく、裏側で動くクローラーやデータ整理のジョブとして割り切る。
この「賢い順番待ち」を実装するだけで、月間100万トークン消費しても無料枠のわずか0.1%にすぎない。
しんたろー:
1分間に2回しかAPI叩けないって、普通なら速攻で採用見送るレベル。
でもバッチ処理なら関係ないし、この割り切り方は一人開発のインフラ防衛策としてかなりアリだと思う。
APIの独自形式への依存も危険だ。
特定のプロバイダーの独自構造に縛られると、無料枠が削られたときの乗り換えコストが跳ね上がる。
だからこそ、OpenAI互換の共通フォーマットを採用しているAPIを選ぶことが重要になる。
URLとモデル名を差し替えるだけで、次の無料プロバイダーへ即座に逃げられる設計にしておく。
AIに記事を要約させるアーキテクチャも劇的に進化している。
いきなり全文を投げて「要約して」と頼むのはもう古い。
間に「事実抽出」という中間ステップを挟む。
まずは客観的な事実や数値だけを箇条書きで抽出させる。
その無機質な中間データをもとに、最終的な要約を生成する。
このパイプライン構造にすることで、出力結果が圧倒的に安定する。
ハルシネーションの発生率も激減する。
さらに、後から別の高性能なモデルが出たときに、事実データだけを使って要約を再生成することも容易になる。
AIに一度にすべてをやらせるのではなく、人間が扱いやすい中間成果物を残す設計だ。
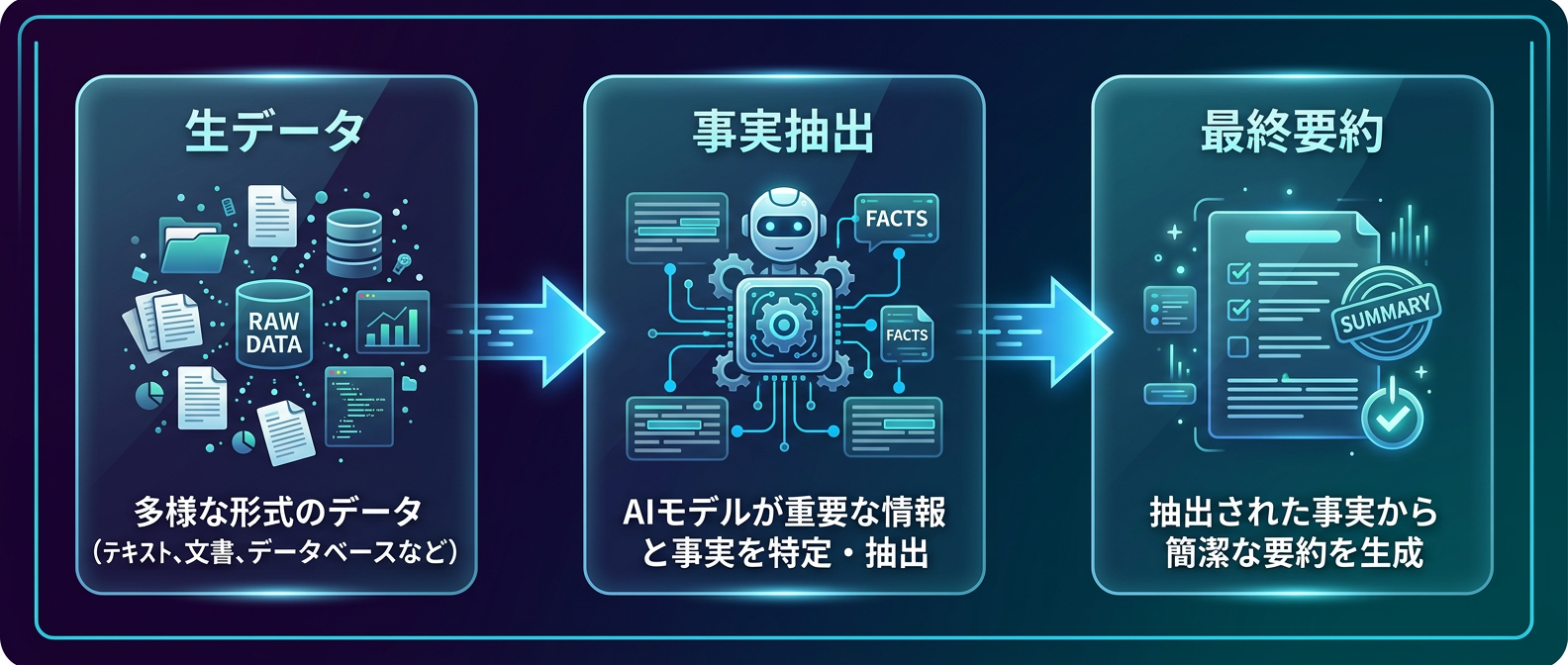
フロントエンド、APIサーバー、そしてAI処理を行うワーカーを分離する。
ユーザーの操作とは完全に切り離し、イベント駆動のジョブとしてAI処理を裏側で走らせる。
これが大量の情報を処理する現代のSaaSアーキテクチャの基本形だ。
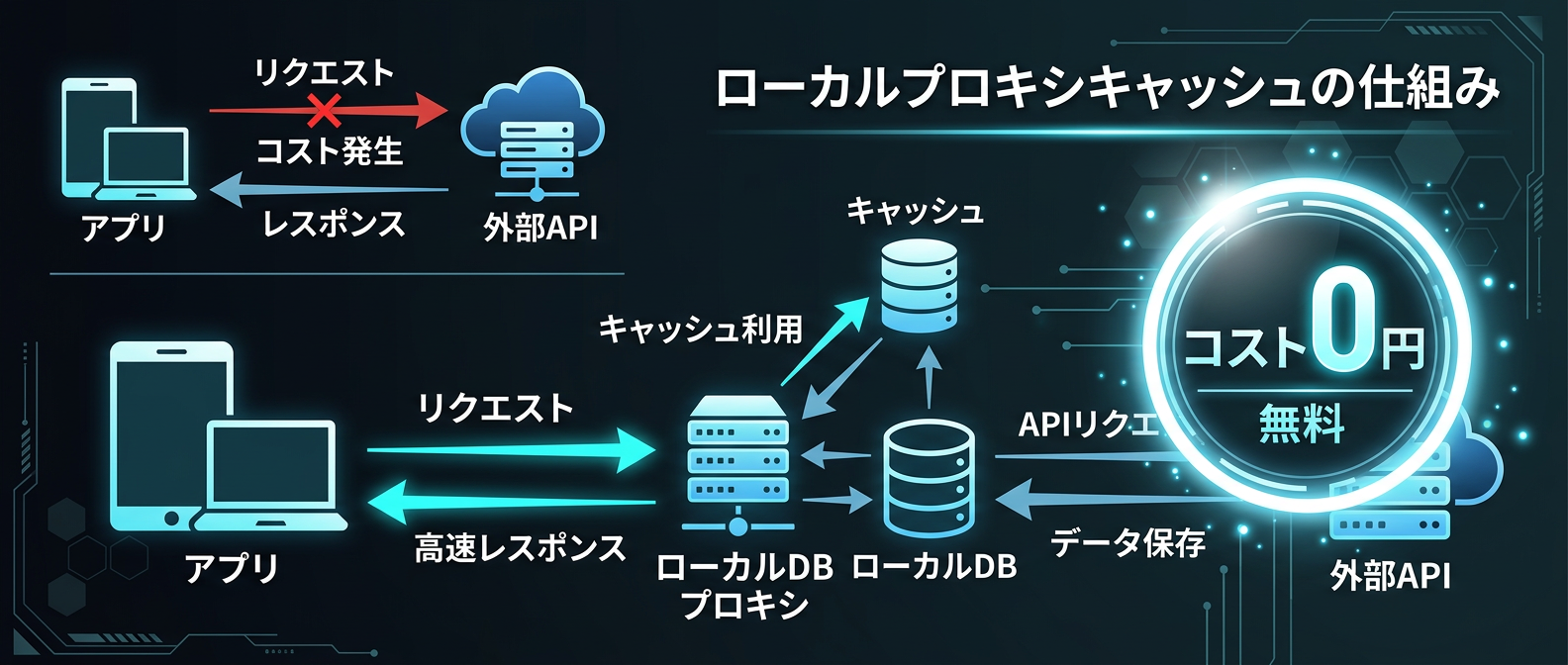
開発中のコスト問題も深刻だ。
プロンプトを1文字変えてテストするだけで、毎回チャリンチャリンとAPI料金が発生する。
これを解決するのがローカルプロキシの導入だ。
APIとアプリの間に、リクエストを傍受するミドルウェアを挟む。
1回目のリクエストは実際のAPIを叩き、結果とトークン数、コストをローカルのSQLiteに保存する。
2回目以降、まったく同じリクエストが来たら、実APIは叩かずにDBのキャッシュから返す。
これでCI/CDで何度自動テストを回しても、コストは永遠に0円だ。
うちの構成でもプロンプトの微調整でAPI代が地味に嵩むから、このローカルプロキシの仕組みはすぐにでも導入したい。
キャッシュをDBに持たせておけば、過去の出力結果との比較検証も爆速になりそう。
さらに強力なのは、過去の実行ステップを遡れる機能だ。
エージェントの処理履歴を保存しておき、特定のステップから別のプロンプトで分岐させる。
まるでGitのブランチを切るように、LLMのプロンプトエンジニアリングをバージョン管理できる。
これをプログラミング未経験者がAIにコードを書かせて作ってしまうのだから恐ろしい。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
1人SaaS開発における実務への影響
LLMアプリ開発のゲームのルールが変わった。
「どの最強モデルを使うか」という単純な勝負ではない。
「LLMの弱点や制約をどうシステムでカバーするか」という総力戦だ。
APIを直接同期的に叩くシンプルな設計は、すぐに限界を迎える。
コストの壁。
レート制限の壁。
出力のブレという壁。
これらをまともに食らうと、SaaSの運用はあっという間に破綻する。
だからこそ、周辺アーキテクチャの構築が必須になる。
非同期キューイングシステムを導入する。
キャッシュプロキシを挟んでコストを遮断する。
事実抽出の中間データ保持層を作る。
LLMを安全かつ安価に扱うための「防波堤」をどれだけ高く築けるかが、個人開発者の腕の見せ所だ。
複雑なミドルウェア層の実装は、たしかに腰が重い。
キューの管理やエラーハンドリング、DBスキーマの設計など、考えることは山ほどある。
でも僕らにはClaude Codeがある。
Claude Codeを使っていると、こういう「ちょっと面倒な中間層」の実装ハードルがバグレベルで下がるのを感じる。
APIの仕様変更に怯えるくらいなら、プロキシ層をサクッと作って自衛したほうが精神衛生上いい。
ターミナルから直接AIに指示を出せば、非同期パイプラインの構築も一瞬で終わる。
イベント駆動のワーカーの実装も、SQLiteを使ったキャッシュ機構の組み込みも、すべて対話形式で進められる。
インフラの制約に振り回されるのはもうやめよう。
システム設計の力で、理不尽な制約をねじ伏せる。
それがこれからの1人SaaS開発のスタンダードになる。
よくある質問
Q1: Mistral APIの無料枠は実務でどう活用すべきですか?
A1: 月10億トークンという圧倒的な枠がある一方、1分間に2リクエスト(2 RPM)という厳しいレート制限があります。そのため、ユーザーを待たせるリアルタイムの対話型アプリには不向きです。GitHub Actionsのcronなどで定期実行する、ニュース要約やデータ整理などの「非同期バッチ処理」に特化して使うのが最適です。
Q2: AIに記事を要約させると出力がブレたり、根拠が不明確になったりします。対策はありますか?
A2: いきなり全文を要約させるのではなく、間に「事実抽出」のステップを挟むパイプライン構造が有効です。まずLLMに客観的な事実や数値を箇条書きで抽出させ、その中間データをもとに要約を生成することで、出力が安定しハルシネーションも減らせます。また、後から別のモデルで要約だけ再生成することも容易になります。
Q3: LLMアプリの開発中、プロンプトを調整するたびにAPI料金がかさむのを防ぐには?
A3: APIリクエストをキャッシュするローカルプロキシを導入するのが効果的です。一度実行したリクエストとレスポンスをローカルDBに保存し、同じリクエストが来た場合はキャッシュから返す仕組みにすることで、CI/CDでのテストやプロンプトの微調整にかかるAPIコストを実質0円に抑えることができます。
まとめ
APIの無料枠縮小はピンチではなく、より堅牢で賢いアーキテクチャへと進化するための絶好のチャンスだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
