
Anthropicの最新レポートが出た。衝撃的な数字だ。
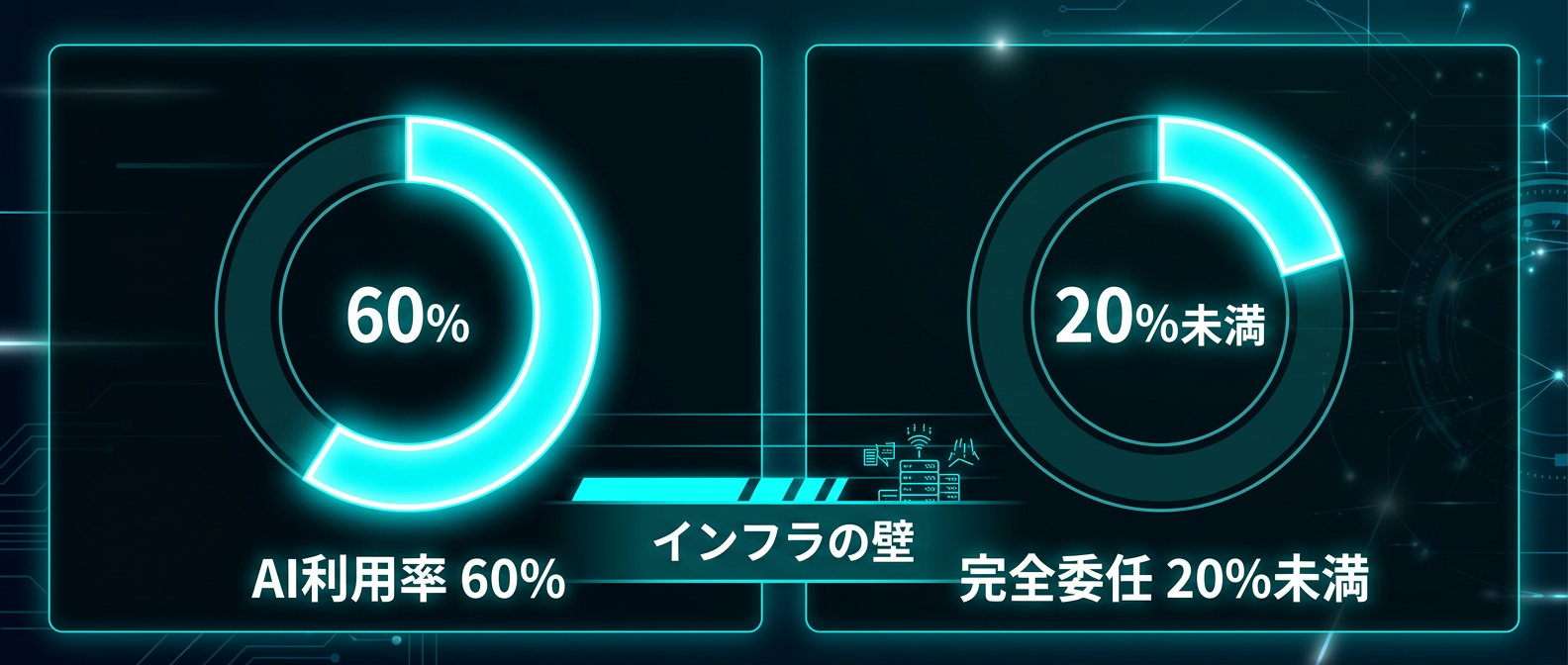
開発者の60%がすでに日常業務でAIを使っている。
しかし、AIにタスクを「完全委任」できている割合はわずか0〜20%にとどまる。
みんなAIを使っている。だが、AIに仕事を「任せきれて」はいない。
Stripeは数億行のRubyコードを相手に完全自律エージェントを稼働させた。
ByteDanceはDockerコンテナ内で動くスーパーエージェントを公開した。
僕ら開発者の仕事は、コードを書くことから「AIのタスクマネージャー」へとシフトしつつある。
2026年3月、AIエージェントの実行環境に関する決定的な動きが重なった。
Anthropicが公開した「Agentic Coding Trends Report」が厳しい現実を突きつけている。
開発者の過半数がAIツールを導入しているにもかかわらず、自律的な実行環境の構築には至っていない。
AIへの指示出し。出力されたコードの確認。手動でのコピペ。そしてローカル環境でのデバッグ。
この「人間による手作業の壁」が、開発プロセスの最大のボトルネックになっている。
モデルの知能は上がった。それを動かすインフラが追いついていない。
これを打破する動きが、トップティアのテック企業から一斉に出てきた。
StripeはMinionsと呼ばれる完全自律型のコーディングエージェントを社内稼働させている。
これは単なる技術デモではない。すでに実稼働している強固なシステムだ。
エンジニアがSlackでMinionボットにメンションを飛ばす。タスクを投げる。
すると、文脈の整理からサンドボックス環境でのテスト、検証、そしてGitHubのPR作成までを全自動で行う。
驚くべきは、これが小さな新規プロジェクトではなく、数億行のRubyモノレポで動いているという事実だ。
数百の内部サービス。300万件を超えるテストスイート。
汎用的なAIツールが「空気を読む」には絶対的な限界がある規模だ。だからStripeは内製に踏み切った。
途中での対話は一切ない。完全に使い捨てのVM環境で、ワンショットでタスクを完了させる。
チャット型ではなくワンショット型を選んだのは、大規模運用における絶対的な信頼性を担保するためだ。
一方で、設計思想が真っ向から対立するアプローチも登場した。
ByteDanceがDeerFlow 2.0というオープンソースのスーパーエージェントフレームワークを公開した。
既存のAIエージェントの多くは、テキストボックスの中で完結している。
しかしDeerFlowは全く違う。隔離されたDockerコンテナ内で、実際にファイルシステムを操作する。
bashターミナルを叩く。依存関係をインストールする。コードを実行して結果を返す。
Stripeが「状態を持たない使い捨て」を徹底したのに対し、ByteDanceはステートフルなメモリと永続的なファイルシステムを採用している。
ユーザーの特定のコーディングスタイル。プロジェクトの独自のディレクトリ構造。
これらをセッションをまたいで長期的に記憶し、適応していくアグレッシブな設計だ。
さらに、これらのエージェントを束ねるオーケストレーションの波も来ている。
OpenAIがSymphonyというマルチエージェントのオーケストレーションツールを発表した。
単一の強力なAIに全てを任せるアプローチはすでに限界を迎えている。
複数の特化型エージェントを並列で自律的に回す開発スタイルが、ここ数ヶ月で急速に広まっている。
「AIにどうコードを書かせるか」というプロンプトエンジニアリングの議論は終わった。
今は「複数のAIをどう安全な環境で連携させ、複雑なタスクを完遂させるか」というインフラとアーキテクチャのフェーズに突入している。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
この一連のニュースを見て、僕ら開発者が直面している現実がはっきりした。
LLMのモデルがGPT-5になろうが、Claude 4になろうが、完全自動化は勝手にはやってこない。
Stripeのエンジニアが残した言葉がすべてを物語っている。
「モデルよりも壁(インフラ)のほうが重要だ」。
AIに自由を与えつつ、本番システムを壊さないための「サンドボックス」をどう作るか。
これが現代の開発者にとって最も価値のあるアーキテクチャ設計スキルになっている。
しんたろー:
Stripeの「モデルより壁」って言葉、Claude Codeを毎日叩いてる身としては痛いほどわかる。
優秀なAIでも平気で既存のロジックを吹き飛ばそうとするから、隔離環境がないと怖くてエンタープライズのコードなんて触らせられない。
結局、人間がレビューする手間が減らないならエージェント化する意味がないんだよな。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
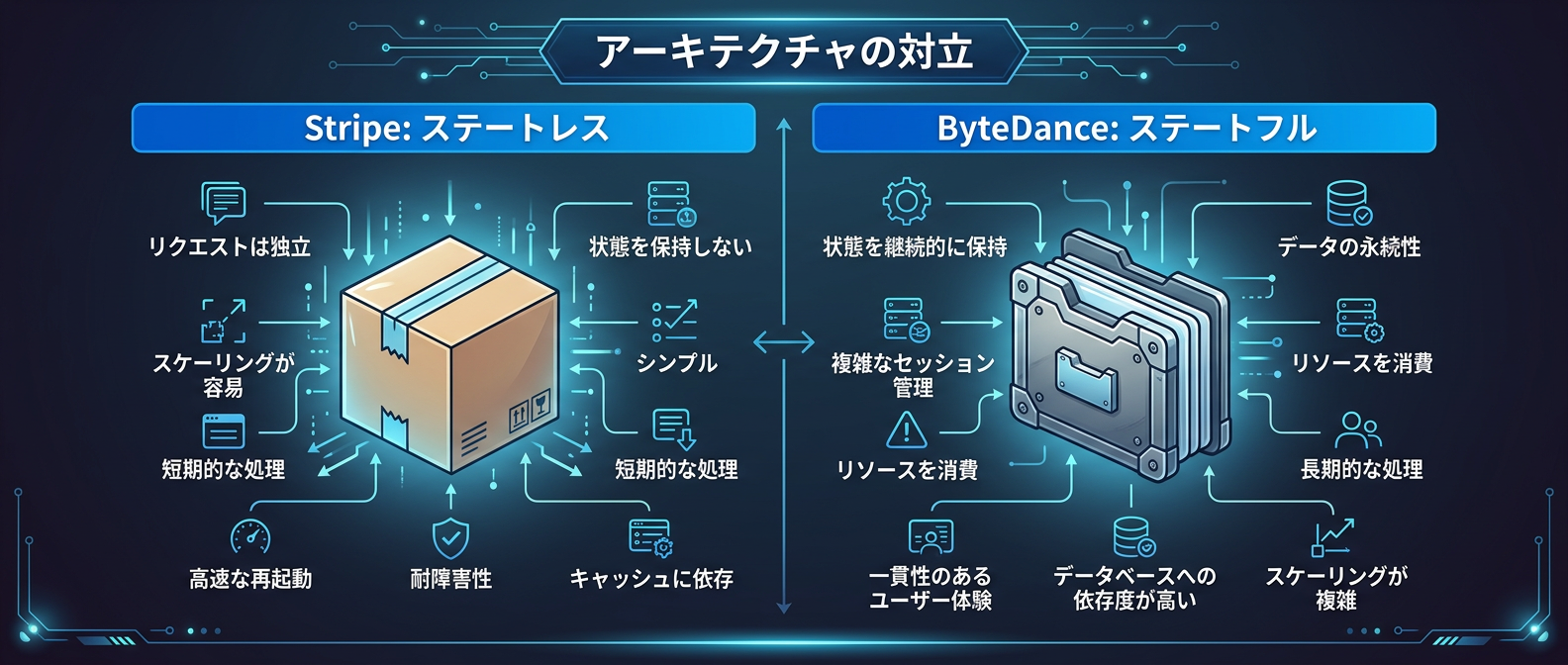
ステートレス vs ステートフル:2つのアーキテクチャ思想
最も注目すべきは、StripeとByteDanceでエージェントのアーキテクチャ思想が完全に分かれている点だ。
Stripeはステートレス(状態なし)を選んだ。
チャット型のように文脈を持ち越すと、どこかでAIの判断がズレたときに修正が効かなくなる。
だから、毎回リセットされる使い捨てのVM環境「devbox」を用意した。
メモリなし。状態なし。使い捨て。
タスク定義とコンテキストを最初に完全に渡し、1回の実行で成果物を出す。
途中で「これってどういう意味ですか?」と聞いてくることはない。
これが数億行の大規模コードベースで信頼性を担保する唯一の解だった。
対するByteDanceのDeerFlow 2.0はステートフル(状態あり)だ。
Dockerコンテナ内で永続的なファイルシステムを持ち、過去のセッションの記憶を引き継ぐ。
これは、長期的なプロジェクトや、特定のユーザーの癖に合わせたパーソナライズを重視しているからだ。
単発のフレーキーテストの修正なら、Stripeのワンショット型が圧倒的に強い。
ゼロからのWebアプリケーション構築や継続的なデータパイプラインの運用なら、ByteDanceのステートフル型が活きる。
プロジェクトの要件に合わせて、エージェントの「記憶の持ち方」と「実行環境」を設計するフェーズに入った。
暴走を止める:DAGとサンドイッチ構造
エージェントの暴走を止めるための仕組みも極めて洗練されてきている。
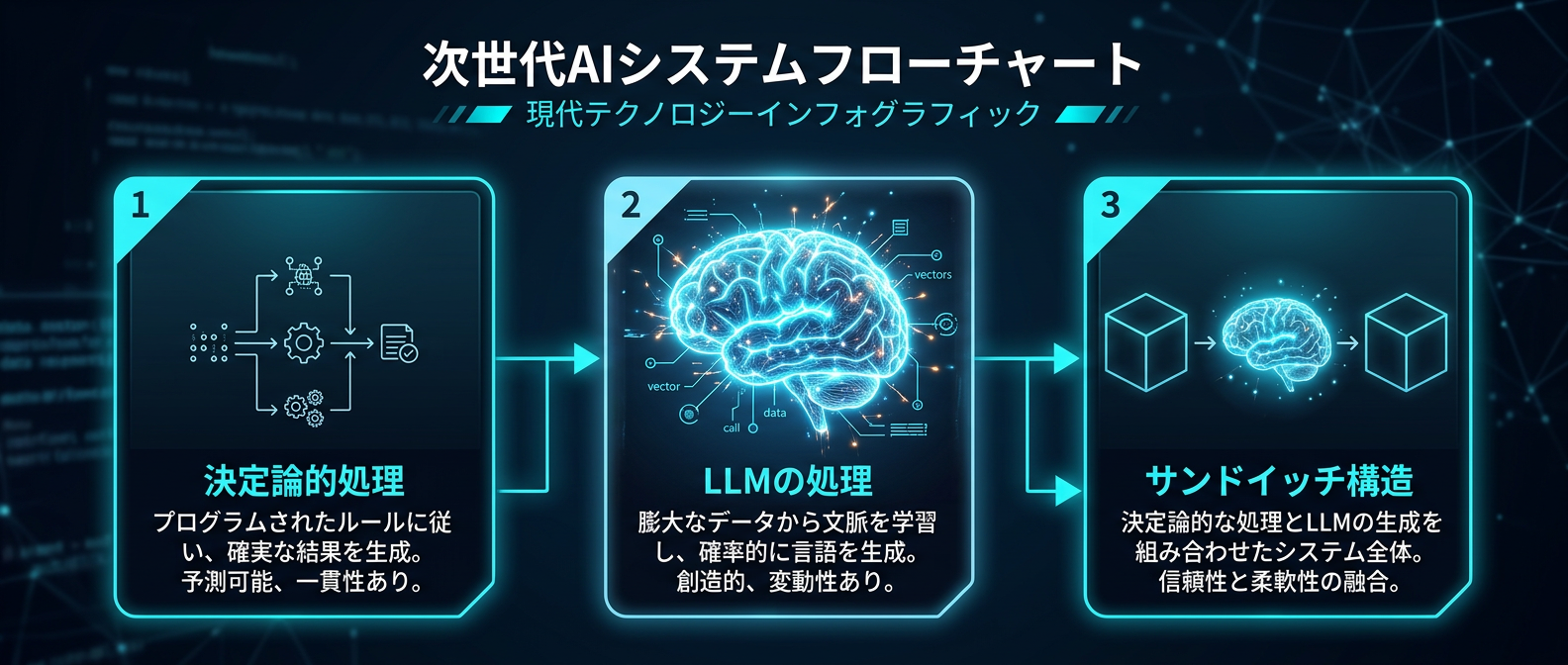
StripeのMinionsは、ワークフローをDAG(有向非巡回グラフ)構造で定義している。
すべてをLLMのブラックボックスに任せるわけではない。
決定論的ノードとLLMノードを交互に配置している。
「Lint実行(決定論)」→「タスク実装(LLM)」→「変更をpush(決定論)」→「CI失敗を修正(LLM)」。
LLMの不確実な処理の間に、必ず機械的で確実なチェックを挟む。
これにより、LLMの判断ミスによる影響範囲を構造的に制限している。
全部LLMに委ねると、判断が外れたときにどこまで波及するかわからない。
AIを制約された箱に入れることで、システム全体の信頼性が掛け算で上がる。
Stripeの公式ブログには「putting LLMs into contained boxes compounds into system-wide reliability upside」という言葉が残っている。
決定論的処理とのサンドイッチ構造、これが実運用の核心だと思う。
LLMにテストまで全部書かせて実行させると、テスト自体を改ざんして「通りました!」って言ってくるからな。
評価軸はLLMの外(決定論的ノード)に持たないと、AIの自律実行はただのギャンブルになる。
コンテキストの設計:500個のツールから15個に絞る
AIへのコンテキストの渡し方も大きく変わった。
ツールをたくさん与えればいいというものではない。
Stripeの内部MCPサーバーには約500個のツールがある。
しかし、1回のタスクでLLMに渡すのは15個程度に厳しく絞り込んでいる。
「ツールがたくさんあるほど良い」ではない。「適切なツールだけを渡す」のが設計思想だ。
多すぎるツールはLLMを混乱させ、ハルシネーションの確率を上げる。
LLMが起動する時点で、すでにリッチで洗練されたコンテキストが整っている必要がある。
エンジニアがSlackでタスクを投げると、LLMが動く前に決定論的なオーケストレーターが動いてコンテキストを整える。
また、人間とAIでルールを共有するアプローチも非常に理にかなっている。
Cursorルールの形式で書かれたルールファイルを、ディレクトリやファイルパターンにスコープして配置する。
そしてこのルールファイルは、人間が使うエディタ、ターミナルで動くClaude Code、そしてバックグラウンドで動くMinionsの3つで完全に共有される。
人間とエージェントの行動規範を統一する。
これにより、誰が(あるいはどのAIが)コードを書いても、出力の品質とスタイルが一定に保たれる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
開発者が今すぐ取り入れるべき4つの設計原則
これらのニュースは僕らの日々の開発に直結する。
「AIにプロンプトを書いてコードを生成させる仕事」の価値は暴落する。
これからの開発者の主業務は、「AIが安全に自律実行できる隔離環境(サンドボックス)を構築し、適切なコンテキストを渡すワークフローを設計すること」に変化する。
具体的なアクションアイテムは以下の通りだ。
1. 実行環境の隔離を大前提にする
AIにローカルのターミナルを直接触らせるのは、リスクが高すぎる。
ByteDanceのDeerFlowのように、Dockerコンテナなどの使い捨て環境をデフォルトにする。
Stripeの「隔離が権限管理になる」という思想は強力だ。
事前に「これはやっていい、これはダメ」という複雑なプロンプトを書く必要はない。
壁の中ならAIが何を壊してもいい。そういう環境をインフラレベルで作れない限り、完全委任の20%の壁は超えられない。
2. 決定論的プロセスをワークフローに組み込む
プロンプトを工夫して「ミスをしないでください」と祈るのをやめる。
LLMの出力後には、必ずLint、静的解析、テスト実行などの決定論的プロセスを挟む。
AIの作業を細かく分割し、その間に人間が信頼できる既存のツールチェーンを配置する。
LLMノードと決定論的ノードのサンドイッチ構造。これがAIのハルシネーションを封じ込め、本番環境に耐えうるコードを生み出す最も確実な方法だ。
3. 無限リトライのループを捨てる
Stripeの運用ルールに「2回直せなければ、3回目も直せない」というものがある。
AIに何度もエラーを食わせても、コンテキストが濁っていくだけで根本的な解決にはならない。
リトライ回数には明確な上限を設ける。
ダメならコンテキストの設計が間違っている。環境をリセットし、人間が介入するか、プロンプトの前提条件を見直す。
4. エージェントの並列起動とタスクマネジメント
単一のAIに複雑なタスクを丸投げしない。
OpenAIのSymphonyが示すように、プロジェクトマネージャー役のAIがタスクを細かく分解する。
そして、複数の特化型サブエージェントに並列で処理させる。
人間である僕らの役割は、オンコール中に複数のエージェントを並列起動し、上がってきたPRをレビューするだけの「タスクマネージャー」になる。
自分ひとりでコードを書き続けるプレイヤースタイルから、「自分+複数のAI部隊」をどう指揮し、オーケストレーションするかに頭を切り替える。
「2回でダメなら諦める」ってルール、本当にその通り。
Claude Codeでも、エラーの無限ループに入った時は大体コンテキストが破綻してる。
意地になってプロンプトこねくり回すより、セッション切って最初からやり直した方が圧倒的に早いんだよね。
よくある質問
Q1: AIエージェントにコードを自動実行させる際のリスクはどう管理すればいいですか?
A1: エージェントの実行環境を、完全に隔離されたサンドボックス(使い捨てのVMやDockerコンテナ)に限定することが基本だ。これにより、エージェントにどれだけ広い権限を与えても、ホストシステムや本番環境への影響を物理的に防ぐことができる。また、LLMの処理の間に決定論的な処理(Lintや自動テスト、セキュリティスキャン)を必ず挟むことで、LLMの判断ミスによる影響範囲を構造的に制限するアプローチが最も有効だ。プロンプトで縛るのではなく、インフラで縛る。
Q2: エージェントの設計において「ステートレス」と「ステートフル」はどちらを選べばいいですか?
A2: プロジェクトの目的によって完全に分かれる。Stripeのように大規模コードベースでのバグ修正やフレーキーテストの解消など、高い信頼性と再現性が求められる単発タスクには、文脈のズレを防ぐ「ステートレス(ワンショット・使い捨て)」が適している。毎回クリーンな状態から始めることで不確実性を排除できる。一方、ByteDanceのDeerFlowのように、ユーザーのコーディングスタイルやプロジェクトの複雑な文脈を長期的に学習・適応させたい場合は、記憶を引き継ぐ「ステートフル」が有利になる。
Q3: マルチエージェントのオーケストレーションとは具体的に何を指しますか?
A3: 複雑なタスクを単一のLLMに任せるのではなく、プロジェクトマネージャー役のAIがタスクを細かく分解し、複数の特化型サブエージェントに並列で実行させる仕組みだ。例えば「リサーチ」「コード生成」「テスト実行」を別々のエージェントに担当させる。これにより、全体の実行速度が大幅に向上するだけでなく、各エージェントが極めて狭いコンテキストに集中できるため、ハルシネーションが減り、タスクの成功率も高まる。
まとめ
AIの主戦場は「いかに賢いコードを書くか」から「いかに安全な箱の中で連携させるか」に完全に移行した。
モデルの進化を待つのではなく、インフラの壁を構築するフェーズだ。
自律型AIエージェントの最新アーキテクチャや、安全なサンドボックス環境の構築ノウハウについて、ThreadPostで議論しませんか?

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準

SalesforceがClaude Codeで開発を18倍高速化した理由とエンジニアの役割変化
