
AIエージェントを本気で仕事のパートナーにしようとすると、今のままでは少し物足りないと感じるはずだ。
一般的な知識は豊富でも、あなた個人の経験や文脈を全く覚えていないからだ。
単純なベクター検索やプロンプトへの全量注入では、長期記憶や複雑な文脈理解にすぐに限界がきてしまう。
結論から言うと、ナレッジグラフによる知識のネットワーク化と、人間が監査可能な階層型メモリの構築が必須になる。
今回は、AIエージェントに「つながった知識」を持たせるための具体的な実装手法を11個紹介する。
安心できるはずだ、個人開発レベルから始められる実践的なテクニックばかりだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理までAIがサポート。
AIエージェントの記憶を拡張する11の実装手法
カテゴリ1:ナレッジグラフによる知識の視覚化と構造化
エージェントに単なる文字列ではなく、意味のつながりを理解させる強力な手法だ。
#### 1. テキストからのナレッジグラフ自動生成と可視化
LLMを使って、テキストから主要概念や対立構造、根拠、結論などの意味構造を抽出し、ナレッジグラフとして可視化する手法だ。
単なる要約ツールやマインドマップとは違い、情報の構造を視覚的に整理できるのが最大の特徴だ。
たとえば、難解な認知科学の本を読んだときのメモや、複雑な仕様を決めた会議の議事録を、ノードとエッジのネットワークに変換して保存する。
これによって、個人の知見や文脈を直感的に把握しやすくなり、後から見返したときの理解度が劇的に変わる。
フロントエンドの描画には、余計なフレームワークを入れずに軽量なJavaScriptの描画APIを直接叩く構成にすると、動作も軽快で良さそうだ。
ノードに奥行きを持たせて、ズーム時にパララックス効果をつけるなどの工夫をすると、視覚的な体験も向上する。
#### 2. 複数グラフの融合による分野横断的なつながりの発見
異なるテーマや分野のテキストから生成されたナレッジグラフ同士を、LLMの力で融合させるアプローチだ。
これを行うことで、AIが分野をまたいだ新しいつながりを見つけ出してくれる。
たとえば、まったく関係ないと思っていた「認知科学の知識」と「組織論の知識」を掛け合わせると、思いがけない共通点や新しいフレームワークが浮かび上がってくるイメージだ。
ただし、すべてのノードの組み合わせをLLMに計算させると、トークン数が爆発してコストが跳ね上がってしまう。
そのため、事前に意味のあるクロスエッジだけを絞り込むアルゴリズムを挟む工夫が必須になる。
この「おっ」と思うようなつながりの発見を積み重ねることで、自分の中の言語化されていなかった世界が、少しずつ形になっていくはずだ。
#### 3. 抽出プロンプトの2段階分割による出力の安定化
LLMにナレッジグラフを作らせる際、1回のプロンプトで全ノードの詳細まで一気に生成させようとすると、情報量が多いときに品質が著しく落ちてしまう。
そこで、「何を切り出すか」の判断と、「どう説明するか」の文章生成を2段階に分ける手法が非常に有効だ。
このタスクの分離によって、複雑で長文のテキストからでも、安定して高品質なナレッジグラフを構築できるようになる。
抽出したノードは、主要概念、対立、結論、根拠といった型ごとに色分けしたり、描画サイズを変えたりするといい。
そうすることで、全体をズームアウトした状態でも「この記事はどんな構造の議論をしているのか」が一目でわかるようになる。
AIの出力を安定させるための、実践的で強力なテクニックだ。
しんたろー:
Claude Codeで毎日コードを書いてる身からすると、プロンプトを分割するアプローチは本当に理にかなっている。
理由はシンプルで、LLMに一度に複数のタスクを詰め込むと、どうしても推論の精度が落ちるからだ。
複雑な処理は小さく分割して連鎖させるのが、AI開発の鉄則だと言える。
カテゴリ2:階層型メモリとMarkdownによる管理
ここからは、エージェントの記憶をどう保存し、どう引き出すかの具体的な管理手法を解説する。
まずは、記憶管理手法の比較表を見て全体像を掴んでおこう。
| 管理手法 | 検索精度 | コンテキスト消費 | 運用保守性 | おすすめ度 |
| --- | --- | --- | --- | --- |
| 単純なプロンプト注入 | 高い | 非常に激しい | 低い | ★☆☆ |
| 辞書方式(リスト化) | 中程度 | 激しい | 中程度 | ★★☆ |
| 階層型メモリ(Markdown) | 高い | 最小限 | 非常に高い | ★★★ |
| ナレッジグラフ | 非常に高い | 少ない | 高い | ★★★ |
#### 4. 辞書方式の限界とコンテキスト肥大化の回避
AIエージェントに記憶を持たせる際、最初は1つのインデックスファイルにすべてのメモをリスト化する「辞書方式」から始める人が多い。
しかし、この方式はナレッジが20件、50件と増えてくると、エージェントが情報の関連性を正しく把握できなくなるという致命的な弱点がある。
すべての情報が並列かつ無関係なものとして扱われるため、必要な知識を得るためのコンテキストがどんどん肥大化してしまうからだ。
コンテキストは情報の質が高く、かつ短い方がAIの推論精度は上がる。
そのため、情報量が増えてきたら、単なるリスト化からネットワーク的な管理への移行が不可欠になる。
辞書方式はあくまで初期のプロトタイプと割り切り、早めに次のステップへ進むのがおすすめだ。
#### 5. 知識のネットワーク化とハイブリッド検索
専用のツールを活用して、テキストからファクトやエンティティ、因果関係を自動抽出し、ネットワーク状のデータベースとして保存する手法だ。
これを使うと、単純なベクトル類似度だけでなく、キーワードマッチやグラフの走査、時間軸によるフィルタリングを組み合わせたハイブリッド検索が可能になる。
これによって、「半年前のプロジェクトで、なぜあの技術選定を見送ったのか」といった、複雑な時系列と因果関係が絡む文脈を横断的に取得できる。
単なる単語の羅列ではなく、意味を持った「つながり」として知識を引き出せるのが最大の強みだ。
この用途には専用のナレッジ抽出ツールがかなり良さそうなので、個人的に注目している技術の一つだ。
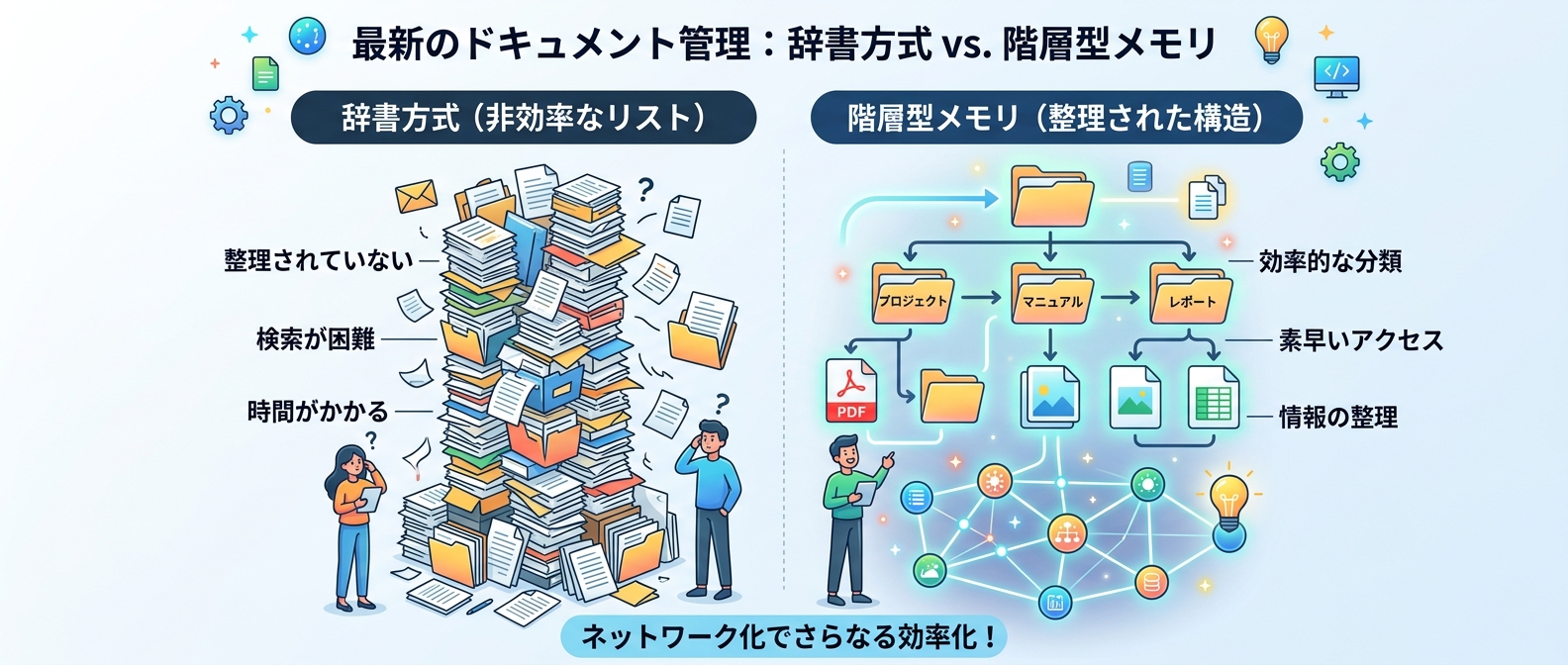
#### 6. 階層型メモリシステムによるコンテキスト管理
エージェントの記憶を、アクセス頻度や重要度に応じて3つの層に分けて管理する優れた手法だ。
第一層は常に読み込まれるコンパクトなインデックスファイル、第二層は必要に応じて取得するトピック別の詳細ファイル、そして第三層は全体を検索するデータベースという構造になる。
これによって、LLMのコンテキスト制限を賢く回避しつつ、数ヶ月前の長期的な記憶も正確に維持できる。
エージェントには、特定のトピックについて詳しく知りたいときだけ、専用のツールを使って第二層のファイルを読みに行く権限を与えるといい。
無駄なトークン消費を抑えつつ、必要なときには深い知識にアクセスできる、非常に合理的な設計だ。
#### 7. 人間が読める・編集できるMarkdownベースのメモリ管理
エージェントの記憶を、中身が見えない不透明なベクターデータではなく、人間が直接読んで編集できるMarkdownファイルとして保持するアプローチだ。
専用のベクターデータベースは中身がブラックボックスになりがちで、AIが間違った記憶を持ったときや、古い情報を参照し続けているときのデバッグが極めて難しい。
Markdown形式なら、使い慣れたテキストエディタでいつでも簡単に内容を確認し、手動で書き換えたり追記したりできる。
システムが信じていることを人間が直接監査できるため、運用保守性が飛躍的に向上する。
個人開発や小規模なチームでAIエージェントを運用するなら、間違いなくこの構成が一番おすすめだ。
カテゴリ3:自律エージェントと検索基盤の高度化
最後は、構築したメモリシステムをエージェントが自律的に使いこなすための高度な実装手法だ。
#### 8. 軽量データベースと全文検索を活用した検索基盤の構築
専用の重厚なベクターデータベースの運用オーバーヘッドを避け、軽量なリレーショナルデータベースの全文検索機能と、ローカル環境でのベクトルエンベディングを組み合わせる手法だ。
この構成なら、単一のデータベースファイルとMarkdownのディレクトリだけで記憶全体を管理できる。
管理するための別プロセスを立ち上げたり、面倒なフォーマット移行に悩まされたりする手間が一切かからない。
数万語規模の個人ナレッジであれば、この軽量な構成でもミリ秒単位の検索が可能になり、実用上は十分すぎるパフォーマンスを発揮する。
大掛かりなインフラを用意しなくても、手元の環境から小さく確実に始められるのが大きなメリットだ。
#### 9. LLMパイプラインによるメモリの自動整理と重複排除
エージェントとのセッションが終了した後に、裏側で会話記録から重要な事実だけを抽出して自動整理するバッチ処理のパイプラインだ。
抽出した新しい知識を既存のメモリと照合し、重複を排除しながら適切な場所に統合していく。
これによって、記憶の肥大化や矛盾を防ぎ、常に最新かつ整理されたナレッジベースを維持できる。
人間の脳が睡眠中に記憶を整理するのと同じようなプロセスを、AIエージェントにも実装するイメージだ。
メモリシステムは一度作って終わりではなく、放置するとすぐにノイズだらけになってしまうため、この自動整理の仕組みは長く運用する上で必須の機能だと言える。
#### 10. ナレッジグラフの自律的ナビゲーション
AIエージェント自身が、構築されたナレッジグラフの中を自律的に探索して情報を集める、高度な情報検索の実装だ。
エージェントが自律的にノード間のリンクを辿り、複数のドキュメントを横断して情報を収集してくる。
これによって、一問一答の単純な検索では答えられないような、複雑な質問に対するマルチホップ推論が可能になる。
人間が思いつかないようなキーワードや、潜在的な関連性をAIが自ら見つけ出して提示してくれる。
単なる「検索システム」から、共に考え、提案してくれる「知的なパートナー」へと進化させるための鍵となる技術だ。

#### 11. 知識ギャップの特定と新しいノートの自動生成
エージェントがナレッジグラフを探索する過程で、現在の知識ベースに不足している情報を自ら特定し、新しいノートを自動生成する手法だ。
AIが単に保存された情報を引き出すだけでなく、ユーザーの知識ベースの穴を見つけ、能動的に拡張・補完してくれる。
既存のネットワーク構造にピタリと適合するように新しい知識を生成してくれるので、使えば使うほどデータベースが立体的で豊かなものになっていく。
ここまで実装できれば、AIは単なるツールを超えて、あなたの思考を拡張する真のアシスタントとして機能するようになるはずだ。
3. しんたろーのイチ推しTips
11個紹介した中で、僕のイチ推しは「人間が読めるMarkdownベースのメモリ管理」だ。
Claude Codeを使って自分のサービスを開発しているときも、プロジェクトの文脈や決定事項をMarkdownで残しておくのが一番確実だった。
ベクターDBのような見えないブラックボックスに依存するより、テキストファイルとして手元で管理できる安心感は計り知れない。
エラーが起きたときも、Markdownならすぐに原因を特定して修正できるから最高だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後はAIが投稿案を毎日生成。確認して選ぶだけ。
4. FAQ

Q1: ベクターデータベースだけではAIエージェントの記憶として不十分なのはなぜ?
ベクターデータベースは「質問に似た文章を探す」ことには優れているが、知識同士の関連性や時系列の文脈を保持するのが苦手だからだ。
そのため、複雑な文脈を思い出す際に断片的な情報しか取得できず、エージェントが適切な判断を下せない原因になる。
ナレッジグラフや階層型メモリを導入することで、知識のつながりを維持したまま文脈を伝えることが可能になる。
Q2: ナレッジグラフを構築するメリットは何?
情報を概念と関係性のネットワークとして保存することで、AIが分野をまたいだ知識のつながりを発見しやすくなることだ。
自律的なエージェントと組み合わせることで、AIがリンクを辿って情報を収集するマルチホップ推論が可能になる。
単なる検索では見落としてしまうような、新しいアイデアのひらめきをAIがサポートしてくれる点が大きな魅力だ。
Q3: エージェントの記憶をMarkdownで管理する利点は何?
最大の利点は、人間が直接読んで監査や編集ができるという透明性の高さだ。
専用のデータベースにブラックボックス化されると、AIが間違った記憶を持ったときにどこを修正すればよいか把握するのが困難になる。
Markdownであれば、使い慣れたテキストエディタで簡単に内容を確認し、誤りを訂正したり新しい知識を手動で追加したりできる。
Q4: 記憶システムを構築する際、コンテキストの肥大化を防ぐにはどうすればいい?
常に読み込ませる情報は最近の活動など最小限に留め、詳細な情報はトピック別のファイルに分割する階層構造が有効だ。
AIが必要な時だけツールを使って読みに行く仕組みにするといい。
また、セッション終了後に会話記録から重要な事実だけを抽出し、重複排除を行う自動整理パイプラインを組むことで、常に最新の状態を保てる。
Q5: 個人開発でメモリシステムを作る場合、おすすめの技術スタックは?
大規模なインフラは不要で、フロントエンドの可視化なら軽量なJavaScript、バックエンドなら軽量なデータベースの全文検索とローカルのエンベディングの組み合わせで十分だ。
単一のファイルで管理できる構成にすれば、運用コストも手間も最小限に抑えられる。
まずは手元のMarkdownファイルとシンプルな検索基盤から、小さく始めるのがおすすめだ。
5. まとめ
今回は、AIエージェントに「つながった記憶」を持たせるための実装手法を11個紹介した。
結論として、単純なベクター検索から卒業し、ナレッジグラフやMarkdownベースの階層型メモリに移行することが、賢いエージェントを作る近道だ。
まずは、日々の会話記録や重要な知見をMarkdownファイルにまとめ、人間が読んで編集できるシンプルなインデックスを作成するところから始めるといい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、AIがサポートします。
ThreadPostをもっと知る
関連記事

Claude Code 2.120.0で変わる開発コストの最適化|キャッシュ制御が利益を生む理由

【2026年版】Claude Codeで始めるループエンジニアリング入門|開発者が押さえるべき5つの鉄則

なぜ開発者はコードを書くのをやめるのか。Claude Codeの自律化で変わるエンジニアの役割

なぜAI開発はコードを書くより判断を設計する時代へ変わったのか

【2026年版】Claudeモデル選定の最適解|コストと性能で導く3つの使い分け基準
